
结果:
{ "took": 21, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": { "total": 8, "max_score": 0, "hits": [] }, "aggregations": { "price": { "buckets": [ { "key": 10000, "doc_count": 2 }, { "key": 15000, "doc_count": 1 }, { "key": 20000, "doc_count": 2 }, { "key": 25000, "doc_count": 1 }, { "key": 30000, "doc_count": 1 }, { "key": 35000, "doc_count": 0 }, { "key": 40000, "doc_count": 0 }, { "key": 45000, "doc_count": 0 }, { "key": 50000, "doc_count": 0 }, { "key": 55000, "doc_count": 0 }, { "key": 60000, "doc_count": 0 }, { "key": 65000, "doc_count": 0 }, { "key": 70000, "doc_count": 0 }, { "key": 75000, "doc_count": 0 }, { "key": 80000, "doc_count": 1 } ] } } }你会发现,中间有大量的文档数量为0 的桶,看起来很丑。
我们可以增加一个参数min_doc_count为1,来约束最少文档数量为1,这样文档数量为0的桶会被过滤
示例:
GET /cars/_search { "size":0, "aggs":{ "price":{ "histogram": { "field": "price", "interval": 5000, "min_doc_count": 1 } } } }结果:
{ "took": 15, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": { "total": 8, "max_score": 0, "hits": [] }, "aggregations": { "price": { "buckets": [ { "key": 10000, "doc_count": 2 }, { "key": 15000, "doc_count": 1 }, { "key": 20000, "doc_count": 2 }, { "key": 25000, "doc_count": 1 }, { "key": 30000, "doc_count": 1 }, { "key": 80000, "doc_count": 1 } ] } } }完美,!
如果你用kibana将结果变为柱形图,会更好看:
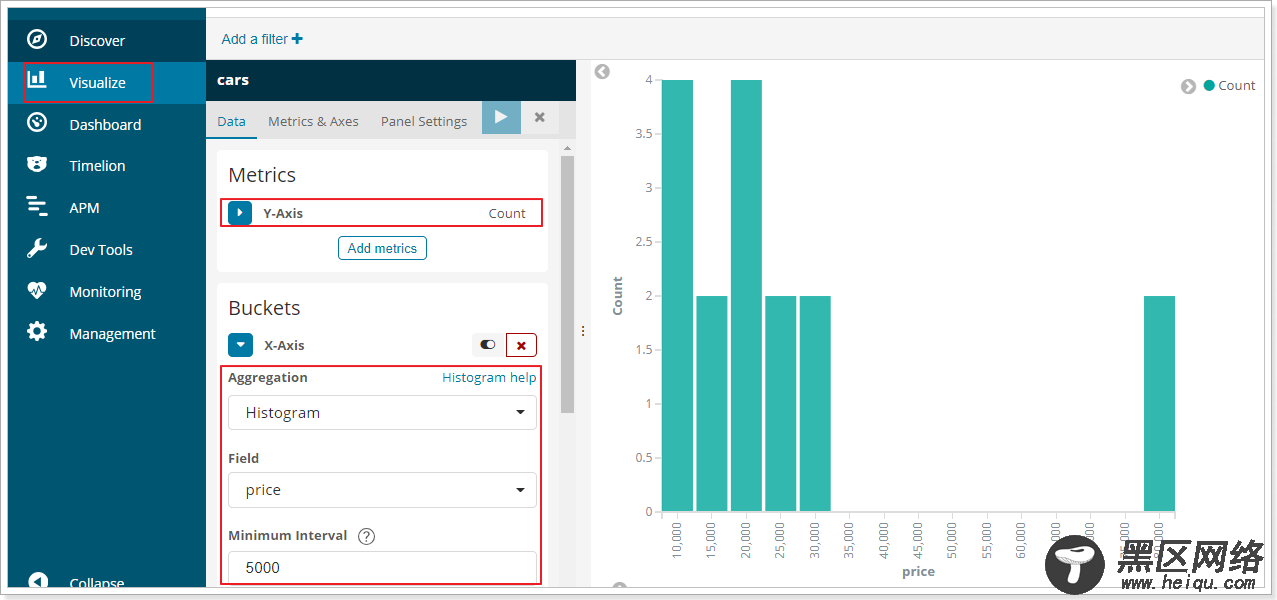
范围分桶与阶梯分桶类似,也是把数字按照阶段进行分组,只不过range方式需要你自己指定每一组的起始和结束大小。