
那到底什么是I/O复用(I/O multiplexing)。根据我的理解,复用指的是复用线程,从阻塞式I/O来看,基本一个套接字就霸占了整个线程。例如当对一个套接字调用recvfrom调用时,整个线程将被阻塞挂起,直到数据报准备完毕。
多路复用就是复用一个线程的I/O模型,Linux中拥有几个调用来实现I/O复用的系统调用——select,poll,epoll(Linux 2.6+)
线程将阻塞在上面的三个系统调用中的某一个之上,而不是阻塞在真正的I/O系统调用上。I/O复用允许对多个套接字进行监听,当有某个套接字准备就绪(可读/可写/异常)时,系统调用将会返回。
然后我们可能将重新启用一个线程并调用recvfrom来将特定套接字中的数据报从内核缓冲区复制到进程缓冲区。
优点
I/O复用技术的优势在于,只需要使用一个线程就可以管理多个socket,系统不需要建立新的进程或者线程,也不必维护这些线程和进程,所以它也是很大程度上减少了资源占用。
另外I/O复用技术还可以同时监听不同协议的套接字
缺点
在只处理连接数较小的场合,使用select的服务器不一定比多线程+阻塞I/O模型效率高,可能延迟更大,因为单个连接处理需要2次系统调用,占用时间会有增加。
当然你可能会想到使用信号这一机制来避免I/O时线程陷入阻塞状态。那么内核开发者怎么可能会想不到。那么我们来看看信号驱动式I/O模型的具体流程
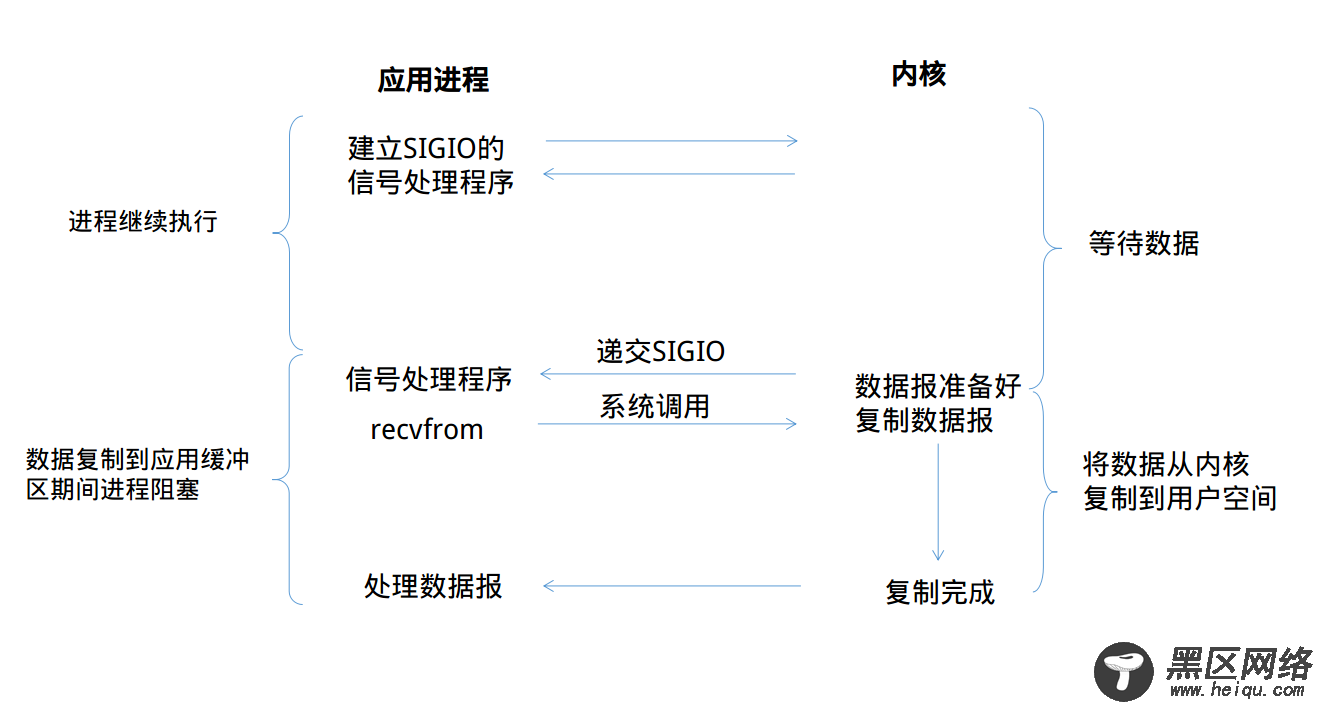
从上图可以看到,我们首先开启套接字的信号驱动式I/O功能,并通过sigaction系统调用来安装一个信号处理函数,我们进程不会被阻塞。
当数据报准备好读取时,内核就为该进程产生一个SIGIO信号,此时我们可以在信号处理函数中调用recvfrom读取数据报,并通知数据已经准备好,正在等待处理。
优点
很明显,我们的线程并没有在等待数据时被阻塞,可以提高资源的利用率
缺点
其实在Unix中,信号是一个被过度设计的机制(这句话来自知乎大神,有待考究)
信号I/O在大量IO操作时可能会因为信号队列溢出导致没法通知——这个是一个非常严重的问题。
稍微歇息一下,还记得我们前面说过这4种I/O模型都可以划分为同步I/O方式,那我们来看看为什么。
了解了4种I/O模型的调用过程后,我们可以注意到,在数据从内核缓冲区复制到用户缓冲区时,都需要进程显示调用recvfrom,并且这个复制过程是阻塞的。
也就是说真正I/O过程(这里的I/O有点狭义,指的是内核缓冲区到用户缓冲区)是同步阻塞的,不同的是各个I/O模型在数据报准备好之前的动作不一样。
下面所说的异步I/O模型将会有所不同
五、异步I/O模型异步I/O,是由POSIX规范定义的。这个规范定义了一些函数,这些函数的工作机制是:告知内核启动某个操作,并让内核在整个操作完成后再通知我们。(包括将数据从内核复制到我们进程的缓冲区)
照样,先看模型的流程
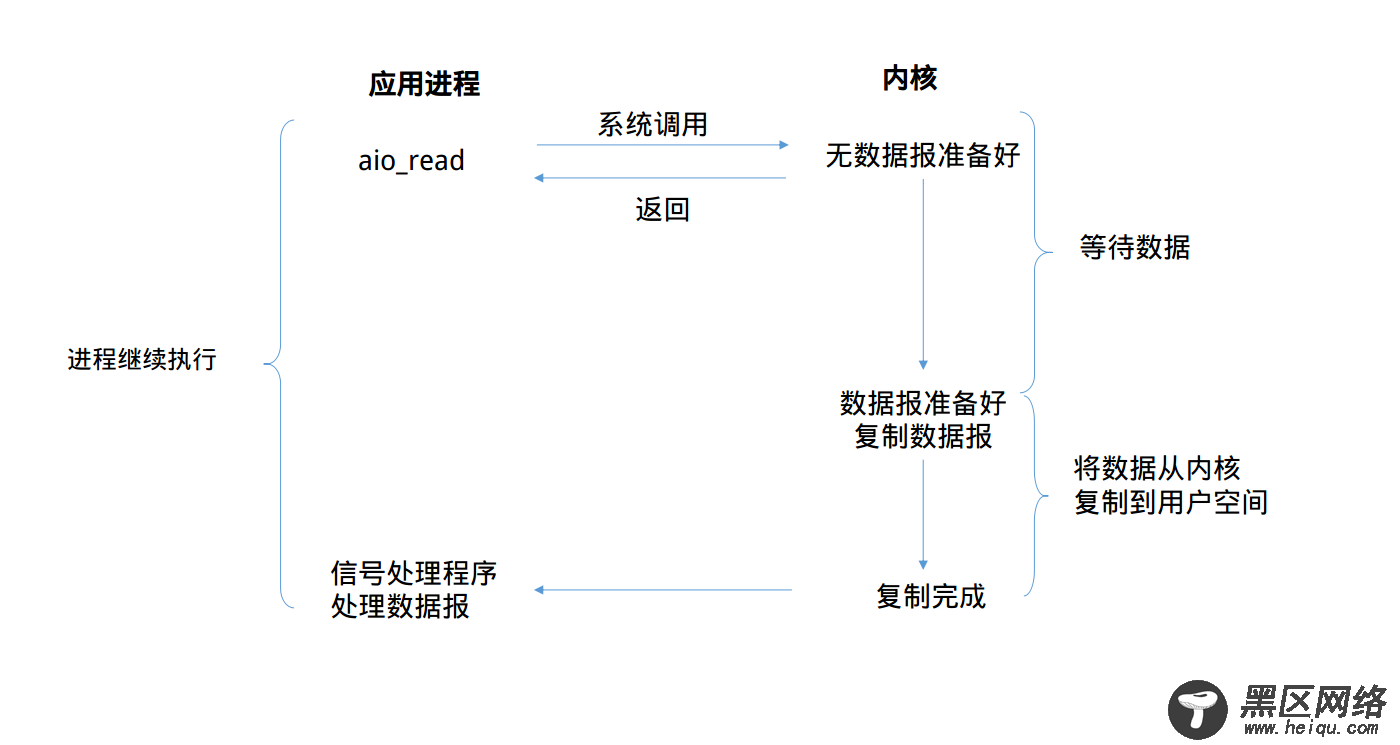
全程没有阻塞,真正做到了异步
异步的优点还用说明吗?
but

异步I/O在Linux2.6才引入,而且到现在仍然未成熟。
虽然有知名的异步I/O库 glibc,但是听说glibc采用多线程模拟,但存在一些bug和设计上的不合理。wtf?多线程模拟,那还有杀卵用。
引入异步I/O可能会代码难以理解的问题,这个站在软件工程的角度也是需要细细衡量的。
总结关于对Linux 的I/O模型的学习就写到这里,每个模型都有自己使用的范围
Talk is cheap, show me the code
实践出真知。
关于I/O模型的实验代码会在2017年10月前放到我的github仓库中。
《Unix网络编程卷1:套接字联网API》(第3版)人民邮电出版社