
结合文章列表的开始部分并通过观察可知,“</div>”为整个文章列表的结束部分。因此,在“区域结束的HTML”中,应填入”</div>”。
设置结束后的“文章网址匹配规则“, 如(图11)所示,
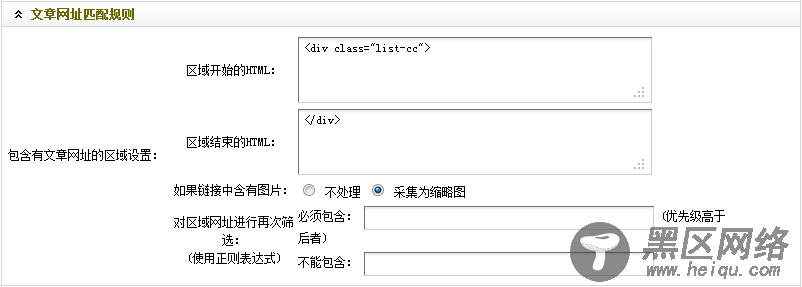
图11-设置后的文章网址匹配规则
通过1.1.1小节、1.1.2小节和1.1.3小节,新增采集节点的第一步就已经设置完成了。设置后的结果,如(图12)所示,
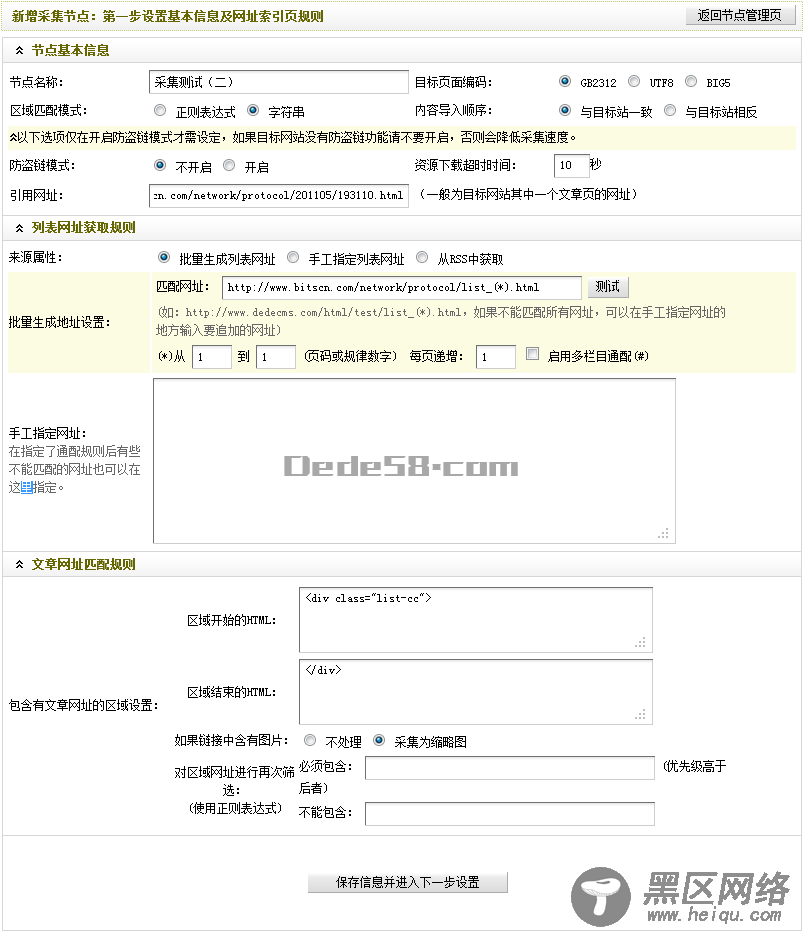
图12-设置后的新增采集节点:第一步设置基本信息及网址索引页规则
全部完成并检查无误后,单击“保存信息并进入下一步设置“。如果之前设置正确,单击后,将会进入“新增采集节点:测试基本信息及网址索引页规则设置的网址获取规则测试”页面并看到相应的文章列表地址。如(图13)所示,

图13-网址获取规则测试
确定正确无误后,单击“保存信息并进入下一步设置”。否则,请单击“返回上一步进行修改“。
到这里,第一节就结束了。下面进入第二节。。。