
RAID系统是用来对存储数据进行数据保护的有效手段。在RAID创建过程中往往会存在一个时间极长的系统初始化过程,为什么RAID初始化过程中会存在这样的一个操作呢?这个操作对SSD会导致什么方面的影响呢?存储老吴从技术研发的角度和大家一起对RAID初始化过程进行分析、研究。
传统RAID的基本组织结构如下图所示:
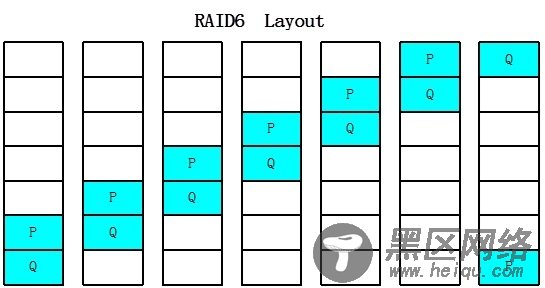
所有加入RAID Group的盘会按照LBA地址切分成一系列的切片,这些切片被称之为Stripe Unit,不同盘中相同LBA地址所对应的Stripe Unit会组织成一个条带(Stripe)。在一个条带中对所有数据进行编码,例如RAID6生成两个编码数据块P和Q,可以允许两个数据盘同时损坏。
所以,在RAID系统中,所有条带中的数据都需要满足编解码算法规则,即条带中的所有数据可以按照一定规则生成编码数据,并且该编码数据和条带中存储的编码数据相同。这种情况被称之为该条带中的数据是一致的。当一个磁盘发生故障时,可以通过存储在条带中的编码数据恢复丢失的数据块。
如果一个条带中的数据不一致,即条带中的数据计算得到的编码结果和存储的编码数据不相同,那么一旦一个磁盘发生故障,那么通过存储在条带中的编码数据将无法正确恢复丢失的数据块。所以,一个数据不一致的条带将会在故障发生时导致数据正确性问题。
在创建一个RAID系统时,RAID Group中的磁盘可能是新盘,也可能是一块已经被使用过的数据盘,这些盘上的数据不会全是零。在这种情况下,采用这些盘构建的数据条带一定不能满足数据一致性的需求。即每个条带中的数据按照一定规则计算得到的编码数据和条带中的编码数据是不相符的。这种数据不一致的条带将会对RAID数据正确性问题引入极大的风险。
正因为这个原因,在创建一个RAID的时候需要考虑将系统中所有的条带进行初始化,以此来保证条带中数据的一致性。条带初始化通常可以采用两种方式来解决:
1, 通过全盘写零的方式初始化RAID系统中的所有的条带。数据全零的条带,其校验数据也为零。因此,全零数据可以保证条带的一致性。
2, 将所有条带进行校验计算,更新条带中的校验数据,以此达到条带数据的一致性。
当一个RAID系统被初始化完成后,所有条带中的数据将会变得一致,如下图所示:
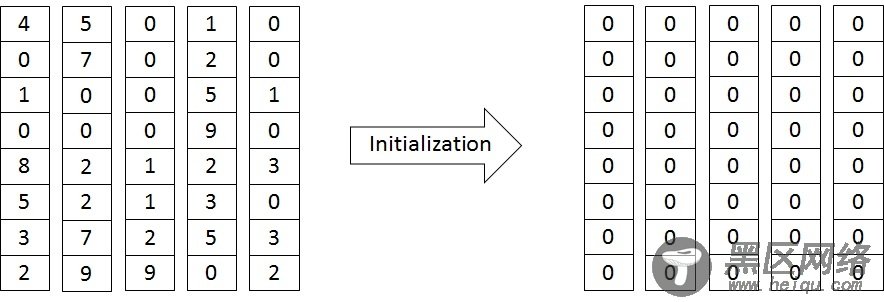
RAID系统初始化过程是一个非常漫长的过程,其主要原因是需要对系统中所有条带进行初始化。还需要考虑和前端用户IO之间的性能平衡,所以,RAID系统初始化往往是一个后台执行的一个过程,会持续较长时间,并且对前端应用的性能造成影响。
对于SSD而言,RAID系统初始化过程还会引入其他问题。在系统初始化过程中,无论是采用写零还是校验数据更新的方式,都需要向SSD盘写入数据,这个过程会导致无谓的数据写放大。用户数据还没有被写入的时候,通过初始化的方式就已经在SSD内部建立了数据映射表。对SSD而言降低了使用寿命和性能。因此,一个针对SSD的RAID系统需要考虑对系统初始化过程的优化,传统RAID是不会考虑到SSD这个特殊特性的。所以,传统RAID不能直接在SSD上进行部署,会对SSD本身的寿命和性能造成影响。
RAID系统采用数据条带化的方式对数据进行保护,但是在条带化数据保护的过程同样引入了一系列问题,系统初始化就是一个典型的条带一致性问题。一个优秀的RAID数据保护系统在设计的过程中都会解决掉这个问题,例如EMC的Data Domain RAID就不存在系统初始化过程,当然其需要和文件系统进行配合,并且在RAID条带数据分布上做了很多的优化。
如何在Linux上构建 RAID 10阵列
Debian软RAID安装笔记 - 使用mdadm安装RAID1
Linux实现最常用的磁盘阵列-- RAID5