
Spark的运行模式多种多样,在单机上既可以以本地模式运行,也可以以伪分布式模式运行。而当以分布式的方式运行在Cluster集群中时,底层的资源调度可以使用Mesos 或者是Hadoop Yarn ,也可以使用Spark自带的Standalone Deploy模式
Spark处于活跃的开发过程中,代码变动频繁,所以本文尽量不涉及具体的代码分析,仅从结构和流程的角度进行阐述。
运行模式列表
基本上,Spark的运行模式取决于传递给SparkContext的MASTER环境变量的值,个别模式还需要辅助的程序接口来配合使用,目前支持的Master字符串及URL包括:
Local[N] :本地模式 使用N个线程
Local-cluster :伪分布式模式
Spark:// :Standalone Deploy模式,需要部署Spark到相关节点
Mesos:// :Mesos模式,需要部署Spark和Mesos到相关节点
Yarn-standalone :SparkContext和任务都运行在Yarn集群中
Yarn-client :SparkConext运行在本地,task运行在Yarn集群中
此外还有一些用于调试的URL
大致工作流程
总体上来说,这些运行模式都基于一个相似的工作流程,SparkContext作为调度的总入口,在初始化过程中会分别创建DAGScheduler作业调度和TaskScheduler任务调度两极调度模块
作业调度模块是基于Stage的高层调度模块,它为每个Spark Job计算具有依赖关系的多个Stage任务阶段(通常根据Shuffle来划分Stage),然后将每个Stage划分为具体的一组任务(通常会考虑数据的本地性等)以Task Sets的形式提交给底层的任务调度模块来具体执行
任务调度模块负责具体启动任务,监控和汇报任务运行情况
不同运行模式的主要区别就在于他们各自实现了自己特定的任务调度模块,用来实际执行计算任务
--------------------------------------分割线 --------------------------------------
CentOS 6.2(64位)下安装Spark0.8.0详细记录
Spark简介及其在Ubuntu下的安装使用
--------------------------------------分割线 --------------------------------------
相关基本类
TaskScheduler / SchedulerBackend
为了抽象出一个公共的接口供DAGScheduler作业调度模块使用,所有的这些运行模式实现的任务调度模块都是基于两个Trait:TaskScheduler和 SchedulerBackend
理论上,TaskScheduler的实现用于与DAGScheduler交互,负责任务的具体调度和运行,核心接口是submitTasks 和 CancelTasks
SchedulerBackend的实现用于与底层资源调度系统交互(如mesos/YARN),配合TaskScheduler实现具体任务执行所需的资源分配,核心接口是receiveOffers
这两者之间的实际交互过程取决于具体调度模式,理论上这两者的实现是成对匹配工作的,拆分成两部分,有利于相似的调度模式共享代码功能模块
TaskSchedulerImpl
TaskSchedulerImpl实现了TaskScheduler Trait,提供了大多数Local和Cluster调度模式的任务调度接口,此外还实现了resourceOffers和statusUpdate两个接口给Backend调用,用于提供调度资源和更新任务状态。另外在提交任务,更新状态等阶段调用Backend的receiveOffers函数用来发起一次任务资源调度请求
Executor
实际任务的运行,最终都由Executor类来执行,Executor对每一个Task启动一个TaskRunner类,并通过ExectorBackend的接口返回task运行结果
具体实现
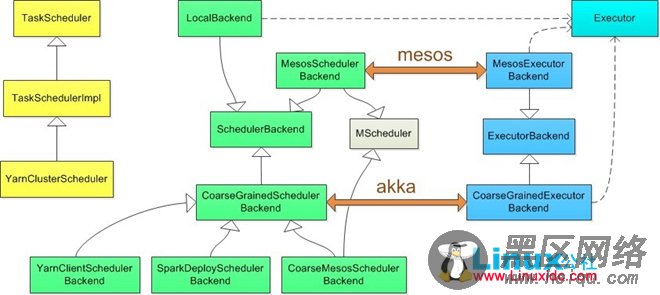
Local[N]
Local本地模式使用 LocalBackend 配合TaskSchedulerImpl
LocalBackend 响应Scheduler的receiveOffers请求,根据可用CPU Core的设定值[N]直接生成WorkerOffer资源返回给Scheduler,并通过Executor类在线程池中依次启动和运行Scheduler返回的任务列表
Spark Standalone Deploy
Standalone模式使用SparkDeploySchedulerBackend配合TaskSchedulerImpl ,而SparkDeploySchedulerBackend本身拓展自CoarseGrainedSchedulerBackend