
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.0.112:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.0.112:19888</value>
</property>
</configuration>
配置 yarn-site.xml(增加yarn功能)
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>192.168.0.112:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>192.168.0.112:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>192.168.0.112:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>192.168.0.112:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.0.112:8088</value>
</property>
</configuration>
将配置好的hadoop文件copy到两台slave机器上,配置和路径和master一模一样。
4.3. 格式化namenode
在master和slave机器上分别操作:
cd ~/tools/hadoop/bin
./hdfs namenode -format
4.4. 启停hdfs和yarn
cd ~/tools/hadoop/sbin
./start-hdfs.sh
./stop-hdfs.sh
./start-yarn.sh
./stop-yarn.sh
启动后可以用jps查看进程,通常有这几个:
NameNode、SecondaryNameNode、ResourceManager、DataNode
如果启动异常,可以查看日志,在master机器的/home/ap/cdahdp/tools/hadoop/logs目录。
4.5. 查看集群状态
查看hdfs::50070/
查看RM::8088/
4.6. 运行wordcount示例程序
上传几个文本文件到hdfs,路径为/tmp/input/
之后运行:
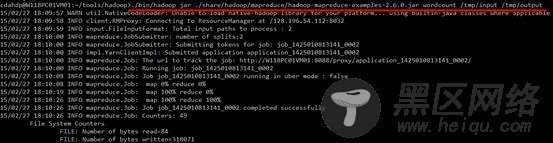
查看执行结果:

正常运行,表示hadoop集群安装成功。
5. Spark集群部署
5.1. 安装Spark并配置环境变量
安装Spark1.1.0版本,安装目录如下。在~/.bash_profile中配置环境变量。
5.2. 修改Hadoop配置文件
配置slaves(增加slave节点)
配置spark-env.sh(设置spark运行的环境变量)
把spark-env.sh.template复制为spark-env.sh
将配置好的spark文件copy到两台slave机器上,配置和路径和master一模一样。
5.3. Spark的启停
cd ~/tools/spark/sbin
./start-all.sh
./stop-all.sh
5.4. 查看集群状态
spark集群的web管理页面::8080/
spark WEBUI页面::4040/
启动spark-shell控制台:

5.5. 运行示例程序
往hdfs上上传一个文本文件README.txt:

在spark-shell控制台执行:
统计README.txt中有多少单词:
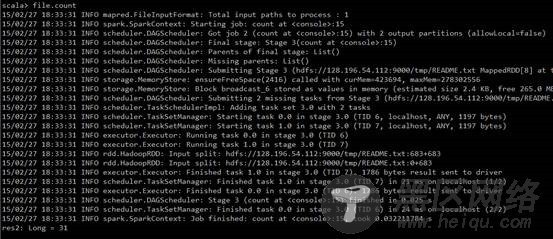
过滤README.txt包括The单词有多少行:

正常运行,表示Spark集群安装成功。