希尔排序是插入排序的一种,又称“缩小增量排序”,希尔排序是直接插入排序算法的一种更高效的改进版本,关于插入排序可以看下这篇随笔:插入排序C语言实现 https://www.linuxidc.com/Linux/2019-08/159739.htm
1、希尔排序的基本思想:
设待排序元素序列有n个元素,首先取一个整数increment(小于n)作为间隔将全部元素分为n/increment个子序列,所有距离为increment的元素放在同一个子序列中,在每一个子序列中分别实行直接插入排序,然后缩小间隔increment,重复上述子序列划分和排序工作,直到最后取increment=1,将所有元素放在同一个子序列中排序为止,该方法实质上是一种分组插入方法
2、关于增量(increment)的取值
希尔排序的复杂度和增量序列是相关的,一般的初次取序列长度的一半为增量,以后每次减半,直到增量为1,希尔排序中对于增量序列的选择十分重要,直接影响到希尔排序的性能,一些经过优化的增量序列如Hibbard经过复杂证明可使得最坏时间复杂度为O(n3/2)
{1,2,4,8,...}这种序列并不是很好的增量序列,使用这个增量序列的时间复杂度(最坏情形)是O(n^2)
Hibbard提出了另一个增量序列{1,3,7,...,2^k-1},这种序列的时间复杂度(最坏情形)为O(n^1.5)
Sedgewick提出了几种增量序列,其最坏情形运行时间为O(n^1.3),其中最好的一个序列是{1,5,19,41,109,...}
3、代码实现
/* 希尔排序*/
int num[5] = {3, 7, 1, 8, 5};
int cur;
int i, j;
int length = sizeof(num)/sizeof(num[0]);
int incre;
incre = length / 2;
while (incre >= 1)
{
for (i = incre; i < length; i++)
{
cur = num[i]; //待排序元素
for (j = i - incre; j >= 0 && num[j] > cur; j = j - incre)
{
num[j + incre] = num[j]; //元素向后移动
}
num[j + incre] = cur; //插入待排序元素
}
incre = incre / 2; //增量减半
}
while里面的代码其实和插入排序的代码没多大区别,就是在两个for循环外面套了一个while再修改了一下内部的for循环,可以对照看一下下面列出来的插入排序的for循环
for (i = 1; i < length; i++)
{
cur = num[i]; //待排序元素
for (j = i - 1; j >= 0 && num[j] > cur; j--)
{
num[j + 1] = num[j];
}
num[j + 1] = cur;
}
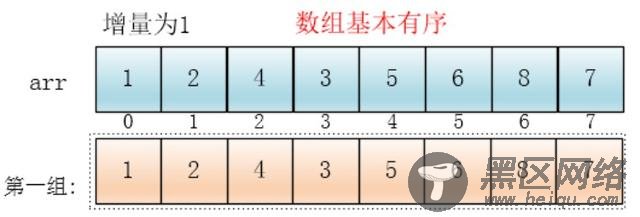
4、排序过程(以5,7,8,3,1,2,4,6为例)
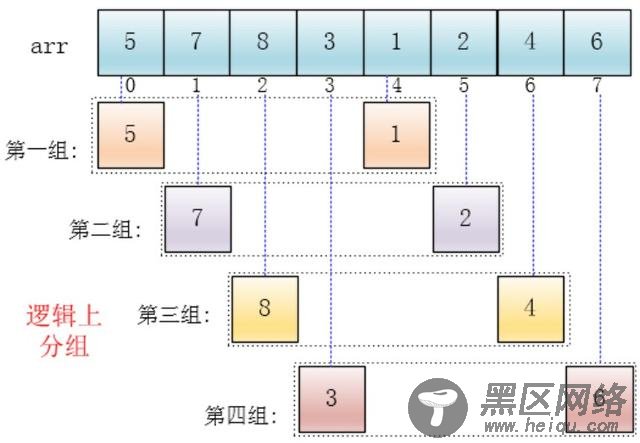


每个分组进行插入排序后,各个分组就变成了有序的了(整体不一定有序)
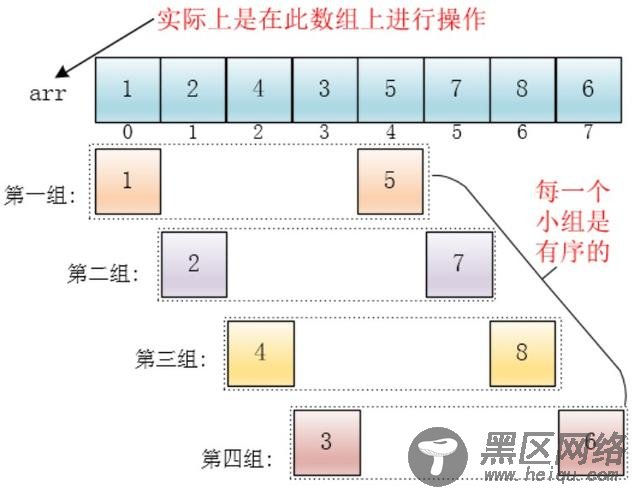
此时,整个数组变的部分有序了(有序程度可能不是很高)
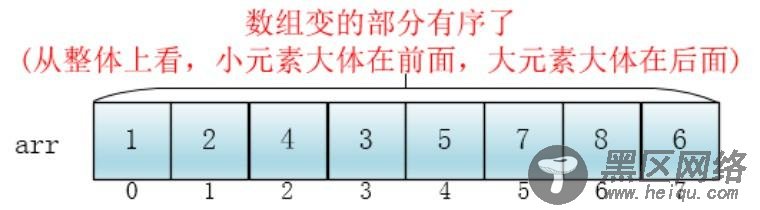
然后缩小增量为上个增量的一半:2,继续划分分组,此时,每个分组元素个数多了,但是,数组变的部分有序了,插入排序效率同样比高

同理对每个分组进行排序(插入排序),使其每个分组各自有序
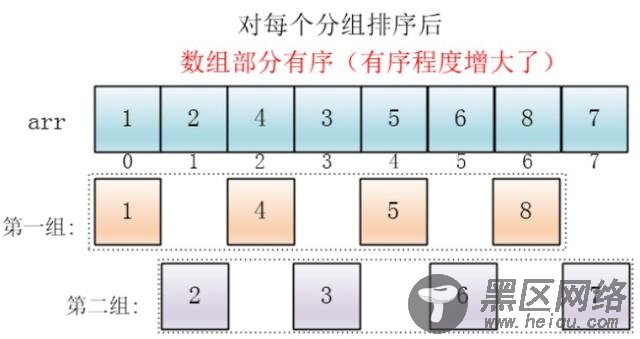
最后设置增量为上一个增量的一半:1,则整个数组被分为一组,此时,整个数组已经接近有序了,插入排序效率高