
先看一个例子,我们想在页面展示一周内的消费变化情况,用echarts面积图进行展示。如下:

我们在后台将数据构造完成
HashMap<String, Integer> map = new HashMap<>(); map.put("星期一", 40); map.put("星期二", 43); map.put("星期三", 35); map.put("星期四", 55); map.put("星期五", 45); map.put("星期六", 35); map.put("星期日", 30);然而页面上一展示,发现并非如此,我们打印出来看,发现顺序并非我们所想,先put进去的先get出来
for (Map.Entry<String, Integer> entry : map.entrySet()){ System.out.println("key: " + entry.getKey() + ", value: " + entry.getValue()); } /** * 结果如下: * key: 星期二, value: 40 * key: 星期六, value: 35 * key: 星期三, value: 50 * key: 星期四, value: 55 * key: 星期五, value: 45 * key: 星期日, value: 65 * key: 星期一, value: 30 */那么如何保证预期展示结果如我们所想呢,这个时候就需要用到LinkedHashMap实体。
二. 初识LinkedHashMap首先我们把上述代码用LinkedHashMap进行重构
LinkedHashMap<String, Integer> map = new LinkedHashMap<>(); map.put("星期一", 40); map.put("星期二", 43); map.put("星期三", 35); map.put("星期四", 55); map.put("星期五", 45); map.put("星期六", 35); map.put("星期日", 30); for (Map.Entry<String, Integer> entry : map.entrySet()){ System.out.println("key: " + entry.getKey() + ", value: " + entry.getValue()); }这个时候,结果正如我们所预期
key: 星期一, value: 40 key: 星期二, value: 43 key: 星期三, value: 35 key: 星期四, value: 55 key: 星期五, value: 45 key: 星期六, value: 35 key: 星期日, value: 30LinkedHashMap继承了HashMap类,是HashMap的子类,LinkedHashMap的大多数方法的实现直接使用了父类HashMap的方法,关于HashMap在前面的章节已经讲过了,《HashMap原理(一) 概念和底层架构》,《HashMap原理(二) 扩容机制及存取原理》。
LinkedHashMap可以说是HashMap和LinkedList的集合体,既使用了HashMap的数据结构,又借用了LinkedList双向链表的结构(关于LinkedList可参考Java集合 LinkedList的原理及使用),那么这样的结构如何实现的呢,我们看一下LinkedHashMap的类结构
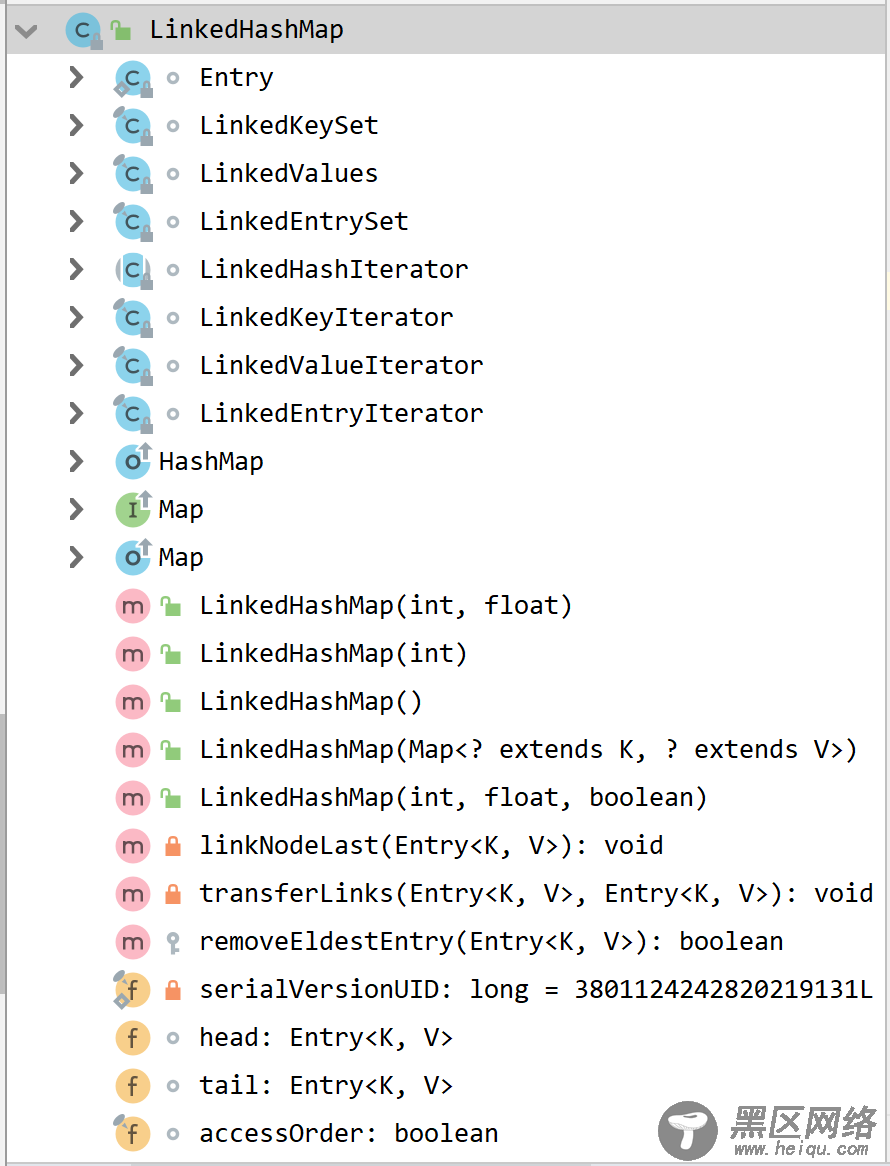
我们看到LinkedHashMap中定义了一个Entry静态内部类,定义了5个构造器,一些成员变量,如head,tail,accessOrder,并继承了HashMap的方法,同时实现了一些迭代器方法。我们先看一下Entry类
static class Entry<K,V> extends HashMap.Node<K,V> { Entry<K,V> before, after; Entry(int hash, K key, V value, Node<K,V> next) { super(hash, key, value, next); } }我们看到这个静态内部类很简单,继承了HashMap的Node内部类,我们知道Node类是HashMap的底层数据结构,实现了数组+链表/红黑树的结构,而Entry类保留了HashMap的数据结构,同时通过before,after实现了双向链表结构(HashMap中Node类只有next属性,并不具备双向链表结构)。那么before,after和next到底什么关系呢。
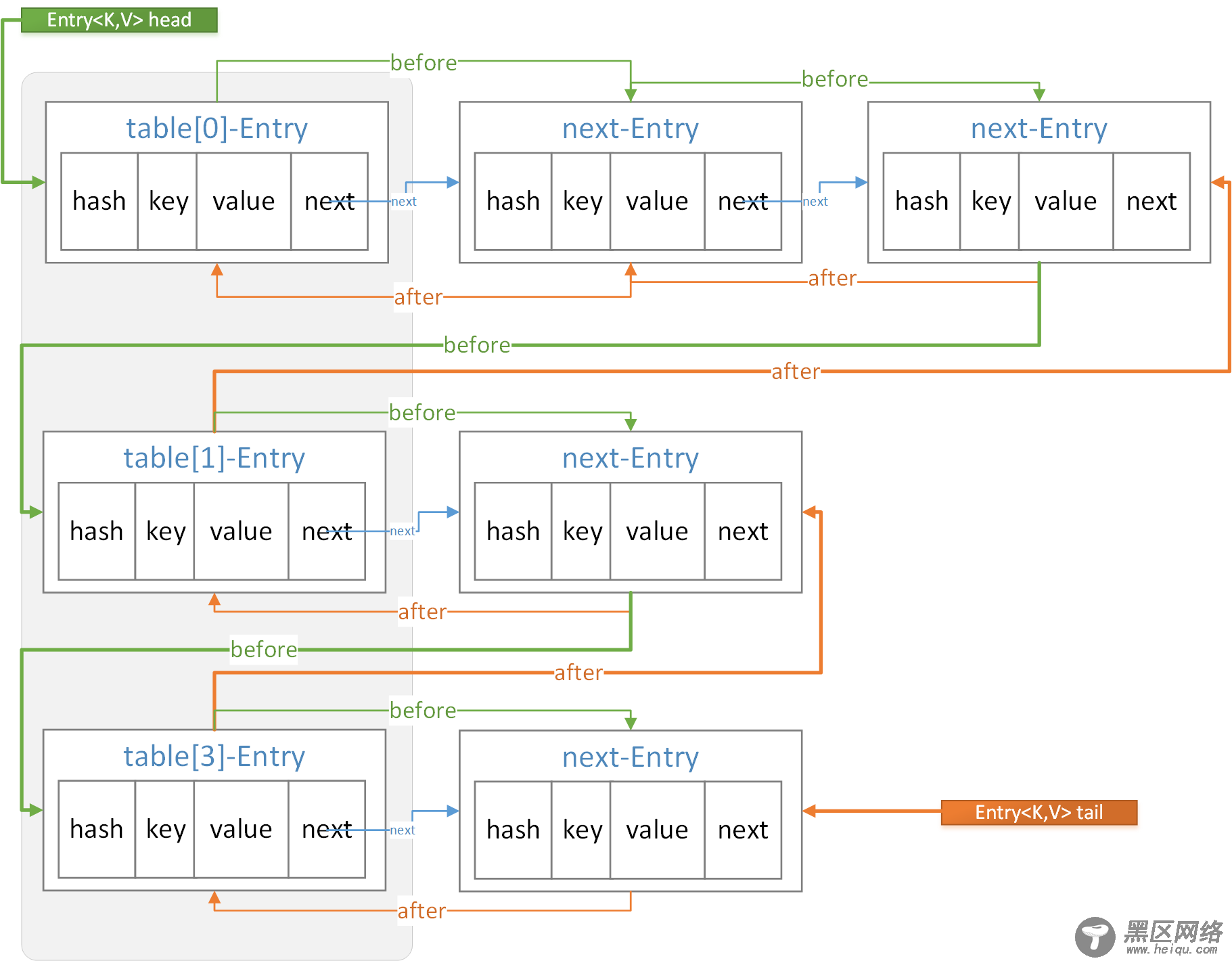
看上面的结构图,定义了头结点head,当我们调用迭代器进行遍历时,通过head开始遍历,通过before属性可以不断找到下一个,直到tail尾结点,从而实现顺序性。而在同一个hash(在上图中表现了同一行)链表内部after和next效果是一样的。不同点在于before和after可以连接不同hash之间的链表。
前面我们发现数据结构已经完全支持其顺序性了,接下来我们再看一下构造方法,看一下比起HashMap的构造方法是否有不同。
// 构造方法1,构造一个指定初始容量和负载因子的、按照插入顺序的LinkedList public LinkedHashMap(int initialCapacity, float loadFactor) { super(initialCapacity, loadFactor); accessOrder = false; } // 构造方法2,构造一个指定初始容量的LinkedHashMap,取得键值对的顺序是插入顺序 public LinkedHashMap(int initialCapacity) { super(initialCapacity); accessOrder = false; } // 构造方法3,用默认的初始化容量和负载因子创建一个LinkedHashMap,取得键值对的顺序是插入顺序 public LinkedHashMap() { super(); accessOrder = false; } // 构造方法4,通过传入的map创建一个LinkedHashMap,容量为默认容量(16)和(map.zise()/DEFAULT_LOAD_FACTORY)+1的较大者,装载因子为默认值 public LinkedHashMap(Map<? extends K, ? extends V> m) { super(m); accessOrder = false; } // 构造方法5,根据指定容量、装载因子和键值对保持顺序创建一个LinkedHashMap public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) { super(initialCapacity, loadFactor); this.accessOrder = accessOrder; }