在Linux/UNIX系统中包含很多文本处理器或文本编辑器,其中grep、sed和awk是shell编程中经常用到的文本处理工具,因此,被业内的人广泛的称之为“shell编程三剑客”。
grep命令工具
grep命令工具,在日常生活中,会经常用到,这里也就不多说了,如果有不明白的朋友,请参考博文:Shell脚本应用之正则表达式详解,里面详细介绍了grep命令的相关参数及使用,
sed命令工具
sed是一个强大而简单的文本解析转换工具,可以读取文本,并根据指定的条件对文本内容进行编辑,最后输出所有行活仅输出处理的某些行,sed可以在无交互的情况下实现相当复杂的文本处理操作。被广泛的应用于shell脚本中,用于完成各种自动化处理任务。
sed的工作流程主要包括:
1. 读取:sed从输入流中读取一行内容不能够存储到临时的缓冲区中;
2. 执行:默认情况下所有的sed命令都在模式空间中按顺序地执行,除非指定了行的地址,否则sed命令将会再所有行上依次执行;
3. 显示:发送修改后的内容到输出流,再发送数据后,模式空间将会被清空。
注意:在所有的文件内容都被处理完成之前,上述过程将重复执行,直至所有内容都被处理完。
1)sed命令的语法及相关参数:
sed [选项] '操作' 参数
或
sed [选项] -f scriptfile 参数
常见的sed命令选项的主要参数:

如果要求在第几行到第几行之间进行修改等,常见的操作参数包括:
2)sed命令用法示例(注意以下操作不会改变文件本身内容,如果需要修改必须带“-i”选项)
1.输出符合条件的文本
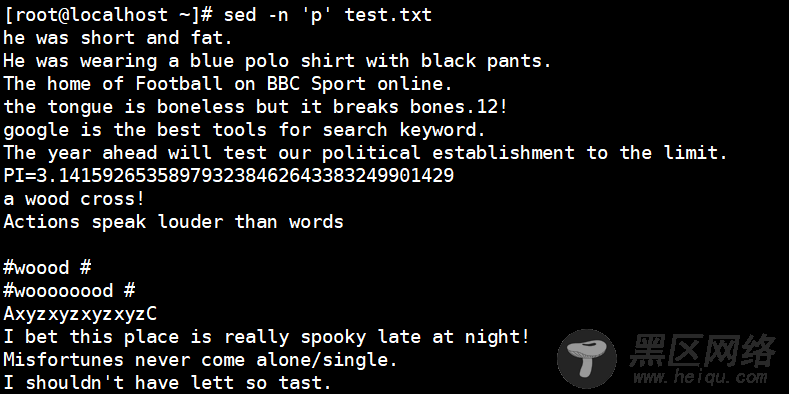
[root@localhost ~]# sed -n 'p' test.txt
//输出所有内容,等同于“cat test.txt”
[root@localhost ~]# sed -n '3p' test.txt
//输出第三行内容

[root@localhost ~]# sed -n '3,5p' test.txt
//输出3~5行
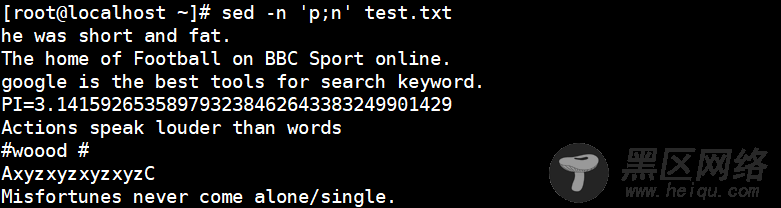
[root@localhost ~]# sed -n 'p;n' test.txt
//输出所有奇数行,n表示读入下一行数据
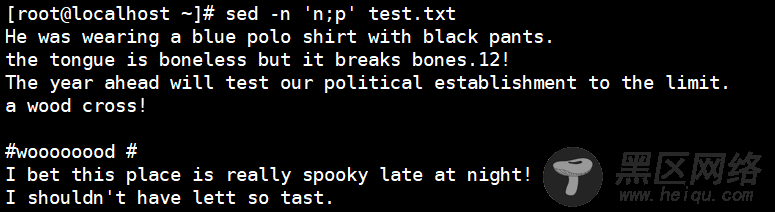
[root@localhost ~]# sed -n 'n;p' test.txt
//输出所有偶数行,n表示读入下一行数据
[root@localhost ~]# sed -n '1,5{p;n}' test.txt
//输出第1行~第5行之间的奇数行(第1、3、5行)

[root@localhost ~]# sed -n '10,${n;p}' test.txt
//输出第10行至文件尾部之间的偶数行(包括空行)
sed命令与正则表达式结合使用的案例
sed命令结合正则表达式时,格式略微有些不同,正则表达式以“/”包围。
[root@localhost ~]# sed -n '/the/p' test.txt
//输出包含“the”的行
[root@localhost ~]# sed -n '4,/the/p' test.txt
//输出从第4行到都第一个包含“the”的行
[root@localhost ~]# sed -n '/the/=' test.txt
//输出包含“the”的行所在的行号(等号(=)用来输出行号)

[root@localhost ~]# sed -n '/^PI/p' test.txt
//输出以“PI”开头的行
[root@localhost ~]# sed -n '/\<wood\>/p' test.txt
//输出包含单词wood的行,\<、\>代表单词边界
2.删除符合条件的文本
nl命令用于计算文件的行数
[root@localhost ~]# nl test.txt | sed '3d'
//删除第3行
