

在扩展 GitLab 数据库和我们应用的解决方案,去帮助解决我们的数据库设置中的问题时,我们深入分析了所面临的挑战。
很长时间以来 GitLab.com 使用了一个单个的 PostgreSQL 数据库服务器和一个用于灾难恢复的单个复制。在 GitLab.com 最初的几年,它工作的还是很好的,但是,随着时间的推移,我们看到这种设置的很多问题,在这篇文章中,我们将带你了解我们在帮助解决 GitLab.com 和 GitLab 实例所在的主机时都做了些什么。
例如,数据库长久处于重压之下, CPU 使用率几乎所有时间都处于 70% 左右。并不是因为我们以最好的方式使用了全部的可用资源,而是因为我们使用了太多的(未经优化的)查询去“冲击”服务器。我们意识到需要去优化设置,这样我们就可以平衡负载,使 GitLab.com 能够更灵活地应对可能出现在主数据库服务器上的任何问题。
在我们使用 PostgreSQL 去跟踪这些问题时,使用了以下的四种技术:
优化你的应用程序代码,以使查询更加高效(并且理论上使用了很少的资源)。
使用一个连接池去减少必需的数据库连接数量(及相关的资源)。
跨多个数据库服务器去平衡负载。
分片你的数据库
在过去的两年里,我们一直在积极地优化应用程序代码,但它不是一个完美的解决方案,甚至,如果你改善了性能,当流量也增加时,你还需要去应用其它的几种技术。出于本文的目的,我们将跳过优化应用代码这个特定主题,而专注于其它技术。
连接池在 PostgreSQL 中,一个连接是通过启动一个操作系统进程来处理的,这反过来又需要大量的资源,更多的连接(及这些进程)将使用你的数据库上的更多的资源。 PostgreSQL 也在 设置中定义了一个强制的最大连接数量。一旦达到这个限制,PostgreSQL 将拒绝新的连接, 比如,下面的图表示的设置:
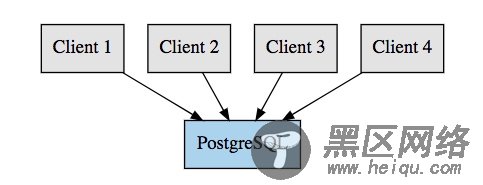
这里我们的客户端直接连接到 PostgreSQL,这样每个客户端请求一个连接。
通过连接池,我们可以有多个客户端侧的连接重复使用一个 PostgreSQL 连接。例如,没有连接池时,我们需要 100 个 PostgreSQL 连接去处理 100 个客户端连接;使用连接池后,我们仅需要 10 个,或者依据我们配置的 PostgreSQL 连接。这意味着我们的连接图表将变成下面看到的那样:
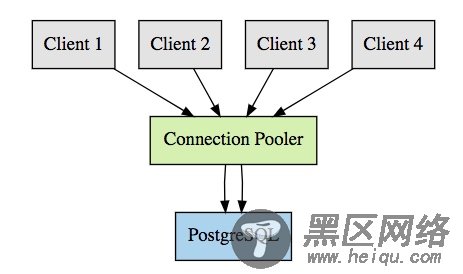
这里我们展示了一个示例,四个客户端连接到 pgbouncer,但不是使用了四个 PostgreSQL 连接,而是仅需要两个。
对于 PostgreSQL 有两个最常用的连接池:
pgpool 有一点特殊,因为它不仅仅是连接池:它有一个内置的查询缓存机制,可以跨多个数据库负载均衡、管理复制等等。
另一个 pgbouncer 是很简单的:它就是一个连接池。
数据库负载均衡数据库级的负载均衡一般是使用 PostgreSQL 的 “热备机hot-standby” 特性来实现的。 热备机是允许你去运行只读 SQL 查询的 PostgreSQL 副本,与不允许运行任何 SQL 查询的普通备用机standby相反。要使用负载均衡,你需要设置一个或多个热备服务器,并且以某些方式去平衡这些跨主机的只读查询,同时将其它操作发送到主服务器上。扩展这样的一个设置是很容易的:(如果需要的话)简单地增加多个热备机以增加只读流量。
这种方法的另一个好处是拥有一个更具弹性的数据库集群。即使主服务器出现问题,仅使用次级服务器也可以继续处理 Web 请求;当然,如果这些请求最终使用主服务器,你可能仍然会遇到错误。
然而,这种方法很难实现。例如,一旦它们包含写操作,事务显然需要在主服务器上运行。此外,在写操作完成之后,我们希望继续使用主服务器一会儿,因为在使用异步复制的时候,热备机服务器上可能还没有这些更改。
分片分片是水平分割你的数据的行为。这意味着数据保存在特定的服务器上并且使用一个分片键检索。例如,你可以按项目分片数据并且使用项目 ID 做为分片键。当你的写负载很高时,分片数据库是很有用的(除了一个多主设置外,均衡写操作没有其它的简单方法),或者当你有大量的数据并且你不再使用传统方式保存它也是有用的(比如,你不能把它简单地全部放进一个单个磁盘中)。