
OR pg_xlog_location_diff(pg_last_xlog_replay_location(), WAL-POINTER)>=0 AS result"
这里 WAL-POINTER 是 WAL 指针,通过 PostgreSQL 函数 pg_current_xlog_insert_location() 返回的,它是在主服务器上执行的。在上面的代码片断中,该指针作为一个参数传递,然后它被引用或转义,并传递给查询。
使用函数 pg_last_xlog_replay_location() 我们可以取得次级服务器的 WAL 指针,然后,我们可以通过函数 pg_xlog_location_diff() 与我们的主服务器上的指针进行比较。如果结果大于 0 ,我们就可以知道次级服务器是同步的。
当一个次级服务器被提升为主服务器,并且我们的 GitLab 进程还不知道这一点的时候,添加检查 NOT pg_is_in_recovery() 以确保查询不会失败。在这个案例中,主服务器总是与它自己是同步的,所以它简单返回一个 true。
后台进程我们的后台进程代码 总是 使用主服务器,因为在后台执行的大部分工作都是写入。此外,我们不能可靠地使用一个热备机,因为我们无法知道作业是否在主服务器执行,也因为许多作业并没有直接绑定到用户上。
连接错误要处理连接错误,比如负载均衡器不会使用一个视作离线的次级服务器,会增加主机上(包括主服务器)的连接错误,将会导致负载均衡器多次重试。这是确保,在遇到偶发的小问题或数据库失败事件时,不会立即显示一个错误页面。当我们在负载均衡器级别上处理 的问题时,我们最终在次级服务器上启用了 hot_standby_feedback ,这样就解决了热备机冲突的所有问题,而不会对表膨胀造成任何负面影响。
我们使用的过程很简单:对于次级服务器,我们在它们之间用无延迟试了几次。对于主服务器,我们通过使用越来越快的回退尝试几次。
更多信息你可以查看 GitLab EE 上的源代码:
数据库负载均衡首次引入是在 GitLab 9.0 中,并且 仅 支持 PostgreSQL。更多信息可以在 9.0 release post 和 documentation 中找到。
Crunchy Data我们与 Crunchy Data 一起协同工作来部署连接池和负载均衡。不久之前我还是唯一的 数据库专家,它意味着我有很多工作要做。此外,我对 PostgreSQL 的内部细节的和它大量的设置所知有限 (或者至少现在是),这意味着我能做的也有限。因为这些原因,我们雇用了 Crunchy 去帮我们找出问题、研究慢查询、建议模式优化、优化 PostgreSQL 设置等等。
在合作期间,大部分工作都是在相互信任的基础上完成的,因此,我们共享私人数据,比如日志。在合作结束时,我们从一些资料和公开的内容中删除了敏感数据,主要的资料在 gitlab-com/infrastructure#1448,这又反过来导致产生和解决了许多分立的问题。
这次合作的好处是巨大的,它帮助我们发现并解决了许多的问题,如果必须我们自己来做的话,我们可能需要花上几个月的时间来识别和解决它。
幸运的是,最近我们成功地雇佣了我们的 第二个数据库专家 并且我们希望以后我们的团队能够发展壮大。
整合连接池和数据库负载均衡整合连接池和数据库负载均衡可以让我们去大幅减少运行数据库集群所需要的资源和在分发到热备机上的负载。例如,以前我们的主服务器 CPU 使用率一直徘徊在 70%,现在它一般在 10% 到 20% 之间,而我们的两台热备机服务器则大部分时间在 20% 左右:
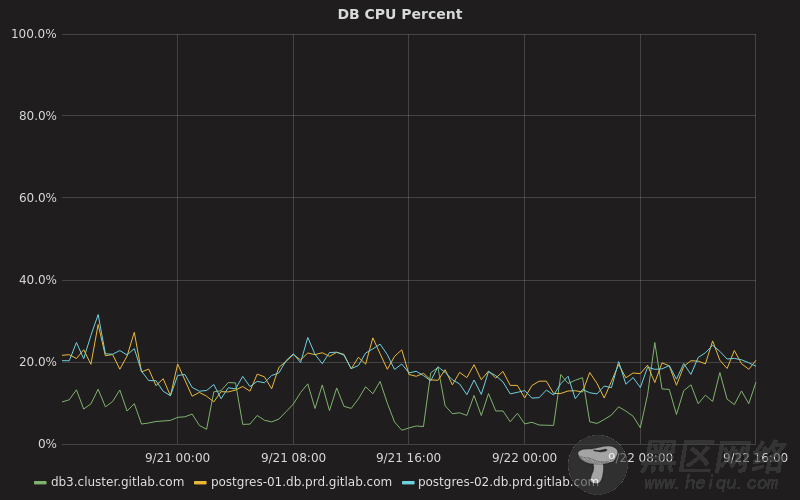
CPU Percentage
在这里, db3.cluster.gitlab.com 是我们的主服务器,而其它的两台是我们的次级服务器。