聚簇索引并不是一种单独的索引类型,而是一种数据存储方式。当表有聚簇索引的时候,它的数据行实际存放在索引的叶子页(leaf page)中。术语“聚簇”表示数据行和相邻的健值紧凑地存储在一起。因为无法同时把数据行存放在两个不同的地方,所以一个表只能有一个聚簇索引。
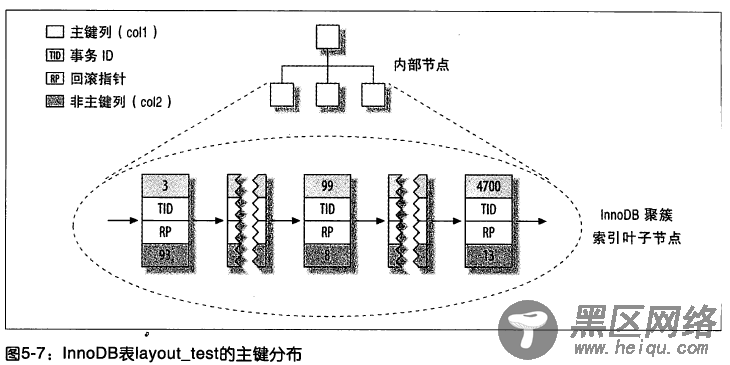
聚簇索引的存放如下图:
由上图注意到,叶子页包含了行的全部数据,但是节点页只包含了索引列。在这张图中,索引列包含的是整数值。
聚簇索引默认是主键,如果表中没有定义主键,InnoDB 会选择一个唯一的非空索引代替。如果没有这样的索引,InnoDB 会隐式定义一个主键来作为聚簇索引。InnoDB 只聚集在同一个页面中的记录。包含相邻健值的页面可能相距甚远。
聚簇索引优点:
可以把相关数据保存在一起。例如实现电子邮箱时,可以根据用户 ID 来聚集数据,这样只需要从磁盘读取少数的数据页就能获取某个用户的全部邮件。如果没有使用聚簇索引,则每封邮件都可能导致一次磁盘 I/O。
数据访问更快。聚簇索引将索引和数据保存在同一个 B-Tree 中,因此从聚簇索引中获取数据通常比在非聚簇索引中查找要快。
使用覆盖索引扫描的查询可以直接使用页节点中的主键值。
聚簇索引缺点:
聚簇数据最大限度地提高了 I/O 密集型应用的性能,但如果数据全部都放在内存中,则访问的顺序就没那么重要了。聚簇索引也就没扫描优势了。
插入速度严重依赖于插入顺序。按照主键的顺序插入是加载数据到 InnoDB 表中速度最快的方式。但如果不是按照主键顺序加载数据,那么加载完成后最好使用 OPTIMIZE TABLE 命令重新组织一下表。
更新聚簇索引列的代价很高,因为会强制 InnoDB 将每个被更新的行移动到新的位置。
基于聚簇索引的表在插入新行,或者主键被更新导致需要移动行的时候,可能面临“页分裂(page split)”的问题。当行的主键值要求必须将这一行插入到某个已满的页时,存储引擎会将该页分裂成两个页面来容纳该行,这就是一次页分裂的操作。页分裂会导致表占用更多的磁盘空间。
聚簇索引可能导致全表扫描变慢,尤其是行比较稀疏,或者由于页分裂导致数据存储不连续的时候。
二级索引(非聚簇索引)可能比想象的要更大,因为在二级索引的叶子节点包含了引用行的主键列。
二级索引访问需要两次索引查找,而不是一次。
为什么二级索引需要两次索引查找?因为二级索引的叶子节点保存的不是指向行的物理位置的指针,而是行的主键值。这就意味着通过二级索引查找行,存储引擎需要找到二级索引的叶子节点获得对应的主键值,然后根据这个值去聚簇索引中查找到对应的行。这里做了重复的操作:两次 B-Tree 查找而不是一次。
InnoDB 和 MyISAM 的数据分布对比
聚簇索引和非聚簇索引的数据分布有区别,以及对应的主键索引和二级索引的数据分布也有区别。使用以下的表来做测试:
CREATE TABLE layout_test(
col1 int NOT NULL,
col2 int NOT NULL,
PRIMARY KEY(col1),
KEY(col2)
);
假设该表的主键取值为1 ~ 10 000,按照随机顺序插入并使用 OPTIMIZE TABLE 命令做了优化。换句话说,数据在磁盘上的存储方式已经是最优,但行的顺序是随机的。列 col2 的值是从 1 ~ 100 之间随机赋值,所以有很多重复值。
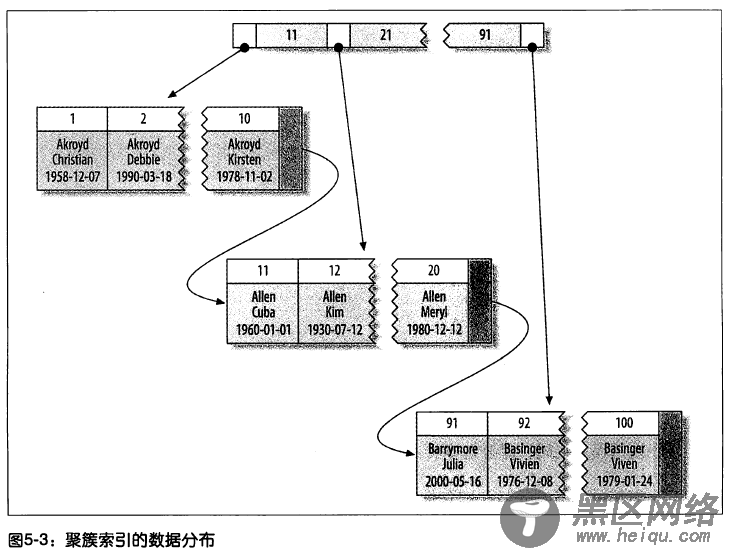
MyISAM 的数据分布。MyISAM 的数据分布非常简单,它按照数据插入的顺序存储在磁盘上,如图所示:
由上图 5-4 可以看出,行的旁边显示了行号,从 0 开始递增。因为行是定长的,所以 MyISAM 可以从表的开头跳过所需的字节找到需要的行(MyISAM 并不总是使用图 5-4 中的“行号”,而是根据定长还是变长的行使用不同策略)。
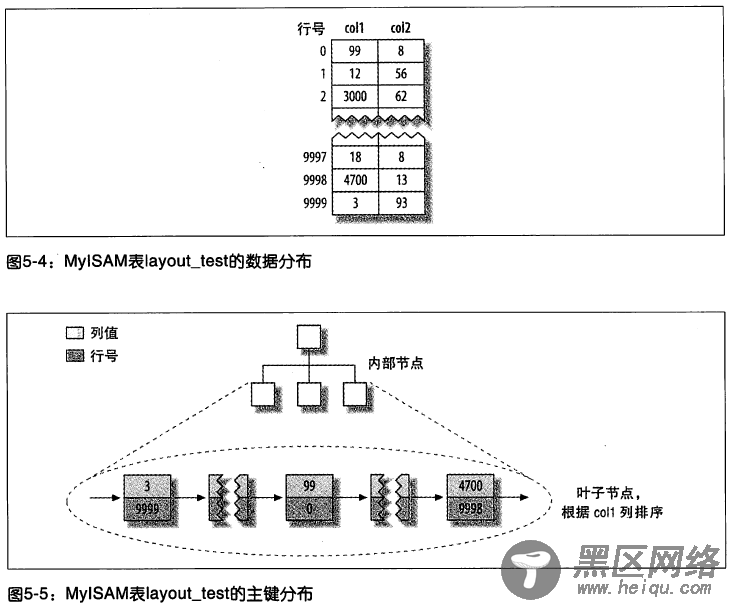
这种分布方式很容易创建索引。下面显示的一系列图,隐藏了页的物理细节,只显示索引中的“节点”,索引中的每个叶子节点包含“行号”。图 5-5 显示了表的主键。
col2 的索引如下图所示:
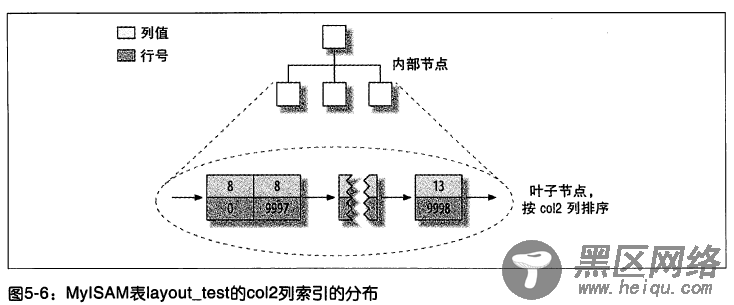
如上图 5-6 可以看出 col2 列的索引和其它索引没有什么区别。事实上,MyISAM 中主键索引和其他索引在结构上没有什么不同。主键索引就是一个名为 PRIMARY 的唯一非空索引。
InnoDB 的数据分布。因为 InnoDB 支持聚簇索引,所以使用非常不同的方式存储同样的数据。InnoDB 以如图 5-7 所示的方式存储数据。