
有时候需要索引很长的字符列,如 BLOB、TEXT 或者很长的 VARCHAR 类型的列,这会让索引变得很大,导致查询很慢。对于这种情况,我们可以使用前缀索引来索引开始的部分字符,这样可以大大的节约索引空间,从而提高索引效率。但这样也会降低索引的选择性。
索引的选择性是指:不重复的索引值(也称为基数,cardinality)和数据表的记录总数(#T)的比值,范围从1/#T到1之间。
索引的选择性越高则查询效率越高,因为选择性高的索引可以过滤更多的行。唯一索引的选择性是1,这是最好的索引选择性,性能也是最好的。如下示例:
// 创建表
CREATE TABLE sakila.city_demo(
city VARCHAR(50) NOT NULL
);
// 自我复制
INSERT INTO sakila.city_demo(city) SELECT `city` FROM sakila.city;
// 从城市表中随机赋值数据到城市测试表
UPDATE sakila.city_demo SET city = (SELECT city FROM sakila.city ORDER BY RAND() LIMIT 1);
现在我们已经有了一个测试数据集,现在,我们来统计城市表中,最常见的城市:
SELECT
COUNT(*) AS cnt,
city
FROM
sakila.city_demo
GROUP BY
city
ORDER BY
cnt DESC
LIMIT 10;
结果集如下:
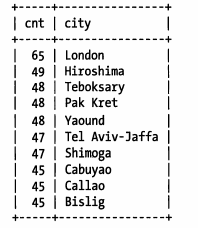
以上的10个城市就是最频繁出现的城市前缀,现在先从3个前缀字母开始:
SELECT
COUNT(*) AS cnt ,
LEFT(city, 3) AS pref
FROM
sakila.city_demo
GROUP BY
pref
ORDER BY
cnt DESC
LIMIT 10;
结果集如下:
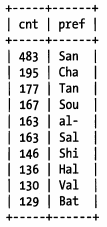
由上结果可知,每个前缀都比原来的城市出现的次数更多,因此唯一前缀比唯一城市要少得多。然后我们继续增加长度测试,直到这个前缀的选择性接近完整列的选择性。最后,我们发现,当长度为7时,最适合:
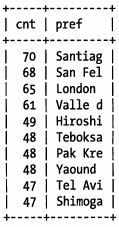
计算合适的前缀长度的另外一个方法就是计算完整性的选择性,并使前缀的选择性接近于完整列的选择性。下面显示如何计算完整列的选择性:
1 SELECT 2 COUNT(DISTINCT city)/COUNT(*) 3 FROM 4 sakila.city_demo;
结果集为:
通常来说,如果前缀的选择性能够接近0.031,基本已经可以用了。当然,也可以在一个查询中,针对不同前缀长度进行计算,这对于大表非常有用。
SELECT
COUNT(DISTINCT LEFT(city, 3))/COUNT(*) AS sel3,
COUNT(DISTINCT LEFT(city, 4))/COUNT(*) AS sel4,
COUNT(DISTINCT LEFT(city, 5))/COUNT(*) AS sel5,
COUNT(DISTINCT LEFT(city, 6))/COUNT(*) AS sel6,
COUNT(DISTINCT LEFT(city, 7))/COUNT(*) AS sel7,
FROM
sakila.city_demo;
结果集如下:
查询显示当前缀索引长度到达7的时候,再增加前缀长度,选择性提升的幅度已经很小了,处于索引长度越长,索引越大,查询越慢的考虑,所以长度为7是比较适合的。
当然,只看平均选择性是不够的,也有例外的情况。根据上面的平均选择性来看,你可能会认为前缀长度为4或者5的索引已经足够了,但如果数据分布很不均匀,可能会存在陷阱,现在我们来观察前缀长度为4的最长出现城市的次数:

由上可知,如果前缀是4个字节,则最常出现的前缀的出现次数比最常出现的城市的出现次数要大很多。即这些值的选择性比平均选择性要低。
下面我们来演示如何创建前缀索引:
ALTER TABLE sakila.city_demo ADD KEY (city(7));
优点:
能使索引更小、更快。
缺点:
无法使用前缀索引进行ORDER BY 和 GROUP BY ,也无法使用前缀索引做覆盖扫描。
常见的应用场景:
针对很长的十六进制唯一ID使用前缀索引。