


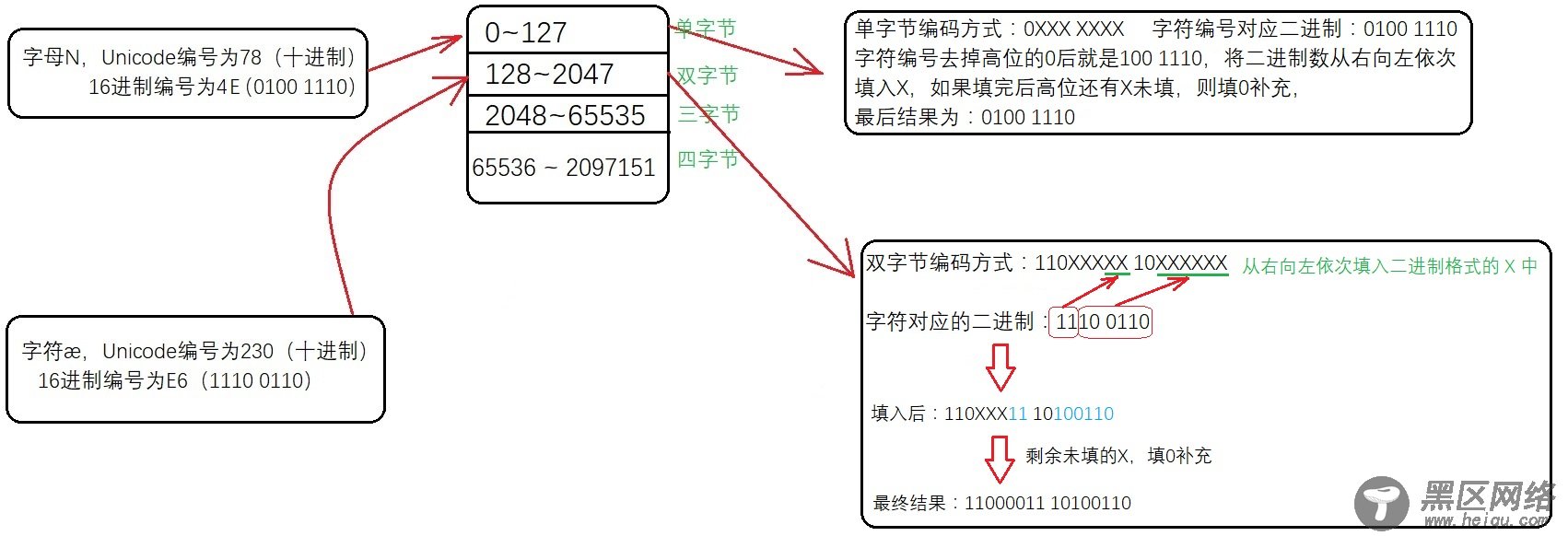
单字节可编码的Unicode码点值范围十六进制为0x0000 ~ 0x007F,十进制为0 ~ 127;
双字节可编码的Unicode码点值范围十六进制为0x0080 ~ 0x07FF,十进制为128 ~ 2047;
三字节可编码的Unicode码点值范围十六进制为0x0800 ~ 0xFFFF,十进制为2048 ~ 65535;
四字节可编码的Unicode码点值范围十六进制为0x10000 ~ 0x1FFFFF,十进制为65536 ~ 2097151
上述的编号范围几个临界值(127、2047、65535、2097151)的计算方式:
对于单字节来说除了前缀码0,有效位数为7位,(2^7-1=127)
对于双字节来说除了前缀码110和10,有效位数为16-5=11位(2^11-1=2047)
剩下的三字节和四字节就是24-8=16位(2^16-1=65535)、32-11=21位(2^21-1=2097151)
将一个字符的Unicode编号确定对应编码方式并按该编码方式存储的步骤如下:

以字母N为例,字母N的 Unicode编号为78(十进制),16进制编号为4E,78属于0~127这个范围,用单字节编码(相当于ASCII)
2、 UTF-16
编码方式:
1、对于 Unicode 编号范围在 0 ~ FFFF 之间的字符,UTF-16 使用两个字节存储,并且直接存储 Unicode 编号,不用进行编码转换,这跟 UTF-32 非常类似。
2、对于 Unicode 编号范围在 10000~10FFFF 之间的字符,UTF-16 使用四个字节存储,具体来说就是:将字符编号的所有比特位分成两部分,较高的一些比特位用一个值介于 D800~DBFF 之间的双字节存储,
较低的一些比特位(剩下的比特位)用一个值介于 DC00~DFFF 之间的双字节存储。

3、UTF-32
编码方式:
始终占用 4 个字节,足以容纳所有的 Unicode 字符,所以直接存储 Unicode 编号即可,不需要任何编码转换。浪费了空间,提高了效率。

对于上面这个字符来说对应的二进制为:0000 0000 1110 0110,经过UTF-32编码后仍然为0000 0000 1110 0110,只不过这里需要说明的是,转换成二进制后计算机存储的问题,计算机在存储器中排列字节有两种方式:
大端法和小端法,大端法就是将高位字节放到低地址处,比如 0x1234, 计算机用两个字节存储,一个是高位字节 0x12,一个是低位字节 0x34,它的存储方式为下:
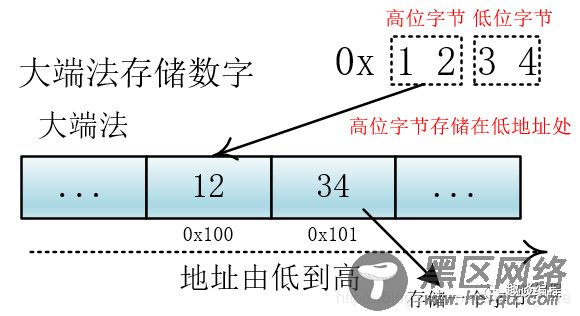
(图片来源:https://blog.csdn.net/zhusongziye/article/details/84261211)
UTF-32 用四个字节表示,处理单元为四个字节(一次拿到四个字节进行处理),如果不分大小端的话,那么就会出现解读错误,比如我们一次要处理四个字节 12 34 56 78,这四个字节是表示
0x12 34 56 78 还是表示 0x78 56 34 12?不同的解释最终表示的值不一样。我们可以根据他们高低字节的存储位置来判断他们所代表的含义,所以在编码方式中有UTF-32BE(big endian) 和 UTF-32LE(littleendian),分别对应大端和小端,来正确地解释多个字节(这里是四个字节)的含义。
(Unicode规范中定义,每一个文件的最前面分别加入一个表示编码顺序的字符,这个字符的名字叫做"零宽度非换行空格"(ZERO WIDTH NO-BREAK SPACE),用FEFF表示,这正好是两个字节,而且FF比FE大1,
如果一个文本文件的头两个字节是FE FF,就表示该文件采用大端方式;如果头两个字节是FF FE,就表示该文件采用小端方式)
Linux公社的RSS地址:https://www.linuxidc.com/rssFeed.aspx