
再看看Page的主体内容,我们主要关注行数据和索引的存储,他们都位于Page的User Records部分,User Records占据Page的大部分空间,User Records由一条一条的Record组成,每条记录代表索引树上的一个节点(非叶子节点和叶子节点)。在一个Page内部,单链表的头尾由固定内容的两条记录来表示,字符串形式的"Infimum"代表开头,"Supremum"代表结尾。这两个用来代表开头结尾的Record存储在System Records的段里,这个System Records和User Records是两个平行的段。InnoDB存在4种不同的Record,它们分别是1主键索引树非叶节点 2主键索引树叶子节点 3辅助键索引树非叶节点 4辅助键索引树叶子节点。这4种节点的Record格式有一些差异,但是它们都存储着Next指针指向下一个Record。后续我们会详细介绍这4种节点,现在只需要把Record当成一个存储了数据同时含有Next指针的单链表节点即可。

User Record在Page内以单链表的形式存在,最初数据是按照插入的先后顺序排列的,但是随着新数据的插入和旧数据的删除,数据物理顺序会变得混乱,但他们依然保持着逻辑上的先后顺序。
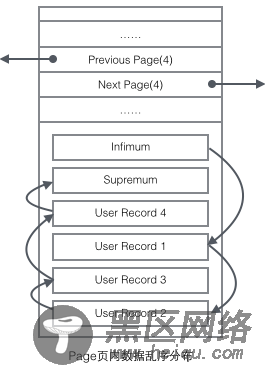
把User Record的组织形式和若干Page组合起来,就看到了稍微完整的形式。
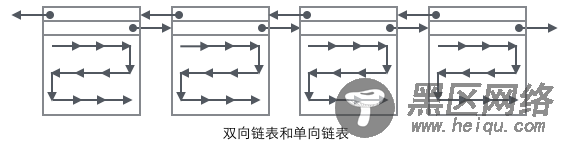
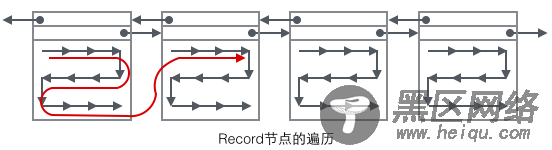
现在看下如何定位一个Record:
1 通过根节点开始遍历一个索引的B+树,通过各层非叶子节点最终到达一个Page,这个Page里存放的都是叶子节点。
2 在Page内从"Infimum"节点开始遍历单链表(这种遍历往往会被优化),如果找到该键则成功返回。如果记录到达了"supremum",说明当前Page里没有合适的键,这时要借助Page的Next Page指针,跳转到下一个Page继续从"Infimum"开始逐个查找。
详细看下不同类型的Record里到底存储了什么数据,根据B+树节点的不同,User Record可以被分成四种格式,下图种按照颜色予以区分。
1 主索引树非叶节点(绿色)
1 子节点存储的主键里最小的值(Min Cluster Key on Child),这是B+树必须的,作用是在一个Page里定位到具体的记录的位置。
2 最小的值所在的Page的编号(Child Page Number),作用是定位Record。
2 主索引树叶子节点(黄色)
1 主键(Cluster Key Fields),B+树必须的,也是数据行的一部分
2 除去主键以外的所有列(Non-Key Fields),这是数据行的除去主键的其他所有列的集合。
这里的1和2两部分加起来就是一个完整的数据行。
3 辅助索引树非叶节点非(蓝色)
1 子节点里存储的辅助键值里的最小的值(Min Secondary-Key on Child),这是B+树必须的,作用是在一个Page里定位到具体的记录的位置。
2 主键值(Cluster Key Fields),非叶子节点为什么要存储主键呢?因为辅助索引是可以不唯一的,但是B+树要求键的值必须唯一,所以这里把辅助键的值和主键的值合并起来作为在B+树中的真正键值,保证了唯一性。但是这也导致在辅助索引B+树中非叶节点反而比叶子节点多了4个字节。(即下图中蓝色节点反而比红色多了4字节)
3 最小的值所在的Page的编号(Child Page Number),作用是定位Record。