3. Hadoop在Facebook变得实时[4]
论文主要解释了Facebook引进Hadoop的原因。结合自己的需求,Facebook对hadoop进行了更实时的改进。
3.1 HDFS与MySQL的性能互补
HDFS适合大块地读取数据(推荐节点是64M),它关于随机读取的工作的accesslatency比较大,所以一般会用大规模的MySQL集群结合memcached这样的缓存工具来做处理。在Facebook中,从Hadoop中产生的类似中间结果的数据会装载到MySQL集群或者memcached中去,用来被web层使用。
同时,HDFS的顺序读取性能很好。Facebook需求写方面的高吞吐量,代价低的弹性存储,同时要求低延迟和硬盘上高效的顺序和随机读取。MySQL存储引擎被证明有比较高的随机读取能力,但是随机写吞吐率比较差。因此,Facebook决定采用Hadoop和HBase来平衡顺序和随机读取的性能,而不是只采用MySQL集群来不断尝试一种难以把握的balance。具体Facebook的需求将在下一节仔细剖析。
3.2 Facebook需求
Facebook认为,用他们已有的基于MySQL集群的一些解决方案来处理问题已经遇到了瓶颈。之前的用例对工作量的扩展是有挑战性的。在一个RDBMS的环境下解决非常高的写吞吐量,大数据,不可预测增长及其他问题变得十分困难。
3.3 选择Hadoop和HBase原因
采用Hadoop和HBase来解决以上需求的存储系统方案的原因可以总结为以下几点:
? 弹性:需要能够用最小的开销和零宕机修复时间来对存储系统增量式地扩容。这里的扩容应该指的是可以比较方便地实时增加服务器台数来应对一些高峰或者突发服务需求。
? 高的写吞吐量
? 高效的硬盘随机读写
? 高可用性和容灾
? 错误隔离:当局部数据库挂掉或者服务器不能提供服务的时候,让最少的用户受到影响。HDFS应对这样的场景还是很不错的。
? 读写改的原子性:底层存储系统针对高并发量的需求
? 范围扫描:指特定场景下高效获取一个范围结果集。
HBase已经以key-value存储的方式提供了高一致性的高写吞吐,且在大规模数据传送和快速随机写以及流式读方面表现优异。它同时保证了行层次的原子性。从数据模型的角度看,面向列的实现给数据存储带来了极高的灵活性,“宽”行允许在一个table内存放百万数量级的被索引的值。
虽然HDFS的核心namenode的宕机会带来巨大影响,但是Facebook有信心打造一个在合理时限内的高可用的NameNode。根据一些实践测试,Facebook对HDFS进行了设计和改进,主要针对namenode。将在下节展开。
3.4 实时HDFS
HDFS刚开始是为了支持MapReduce这样的并行应用的数据存取的,是面向批处理系统的,所以在实时方面讲本身可能是存在不足的。Facebook主要改造在于一个高可用的AvatarNode。
我们知道HDFS的namenode一旦挂掉,整个集群就得等到namenode再次启动才能继续运行提供服务,所以需要这个热备份——AvatarNode的设计。在HDFS启动的时候,namenode是从一个叫fsimage的文件里读取文件系统的元数据的。元数据信息包括了HDFS上所有文件和目录的名字和元数据。但是namenode不会持续地去存每一块block的位置信息。所以冷启动namenode的时候包括两部分:首先读文件系统镜像;然后,大部分datanode汇报进程上的block信息,以此来恢复集群上每一块已知block的位置信息。这样的冷启动会花很长时间。
虽然一个备用的可用node可以避免failover时候去读磁盘上的fsimage,但是依然需要从datanodes里获取block信息。所以,时间相对还是偏长。于是诞生了AvatarNode。
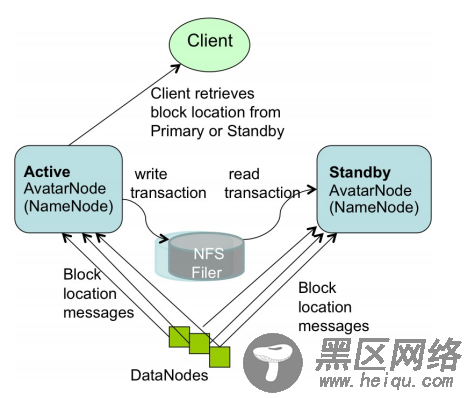
如图所示。HDFS拥有两个AvatarNode——Active AvatarNode和Standby AvatarNode。他们形成了一对“主被动热备份”(active-passive-hot-standby)。AvatarNode是对NameNode的包装。Facebook的HDFS集群都采用NFS来存一份文件系统镜像的备份和一份事物日志的备份。Active AvatarNode把自己处理的事务写进NFS里的事务日志。同时,StandbyAvatarNode打开NFS上同一份事务日志,然后在自己的命名空间内开始执行事务,以保证自己的命名空间尽可能和初始信息接近。Standby AvatarNode同时照顾到初始信息的核查并创建新的文件系统镜像,和HDFS相比就没有了分离的SecondNameNode。
Datanodes同时和两个AvatarNode交流。这保证了Standby处也获得到最新的block状态信息,以在分钟时间级内转化成为Activer的Node(之前说namenode的冷启动的时长问题可以解决了)。Avatar DataNode相互之间输送心跳,block信息汇报和接受到的block。Avatar DataNodes集成了Zookeeper,因此他们知道主节点信息,会执行主节点发送的复制/删除命令(基于Zookeeper的leader selection和heartbeat机制),而来自Standby AvatarNode的复制/删除请求是忽略的。
对于事务日志的记录,还进行了一些改进。
i. 为了让故障和失效尽可能透明,Standby必须知道失效发生时的block位置信息,所以对每一块block分配记录一个额外的记录日志。这样允许客户端在发生失效的时刻前还是一直在写文件。
ii. 当Standby向正在被Active写事务记录的日志里读取事务信息的时候,有可能读到的是一个局部的事务。为了避免这样的问题,给每个要写进日志里的事务增加记录事务长度信息,事务id和校验和。
要了解更具体的信息,可以从原paper中获得更多具体的情况。
4. HadoopDB[6]
HadoopDB简单介绍下设计理念和他的架构。
4.1 HadoopDB理念
HadoopDB是一个混合系统。基本思想是用MapReduce作为与正在运行着单节点DBMS实例的多样化节点的通信层。查询语言用SQL表示,并用现有工具翻译成MapReduce可以接受的语言,使得尽可能多的任务可以被推送到每个高性能的单节点数据库上。这样基于MapReduce的并行化的数据库代价几乎是零。因为MapReduce是现有的。
HadoopDB背后的一些主要思想包括以下两个关键字:share-nothing MPP架构和parallel databases。
4.2 HadoopDB架构介绍

作为一个混合的系统,让我们看看HadoopDB由哪些部分构成:HDFS,MapReduce,SMS Planner,DB Connector等等。HadoopDB的核心框架还是Hadoop,具体就是存储层HDFS,和处理层MapReduce。关于HDFS上namenode,datanode各自处理任务,数据备份存储机制以及MapReduce内master-slave架构,jobtracker和tasktracker各自的工作机制和任务负载分配,数据本地化特性等内容就不详细说了。下面对主要构成部件做简单介绍:
1. Databae Connector:承担的是node上独立数据库系统和TaskTracker之间的接口。图中可以看到每个single的数据库都关联一个datanode和一个tasktracker。他传输SQL语句,得到一些KV返回值。扩展了Hadoop的InputFormat,使得与MapReduce框架实现无缝拼接。
2. Catalog:维持数据库的元数据信息。包括两部分:数据库的连接参数和元数据,如集群中的数据集,复本位置,数据分区属性。现在是以XML来记录这些元数据信息的。由JobTracker和TaskTracker在必要的时候来获取相应信息。
3. Data Loader:主要职责涉及根据给定的分区key来装载数据,对数据进行分区。包含自身两个主要Hasher:Global Hasher和Local Hasher。简单地说,Hasher无非是为了让分区更加均衡。
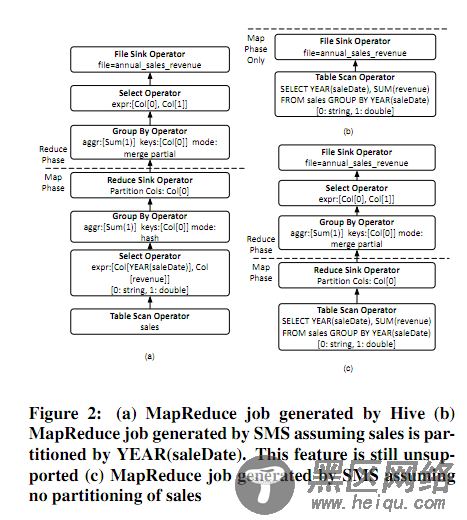
4. SMS Planner:SMS是SQL to MapReduce to SQL的缩写。HadoopDB通过使他们能执行SQL请求来提供一个并行化数据库前端做数据处理。SMS是扩展了Hive。关于Hive我在这里不展开介绍了。总之是关于一种融入到MapReduce job内的SQL的变种语言,来连接HDFS内存放文件的table。可以贴个图看下。不详细说了。