5. CoHadoop[7]
论文提出CoHadoop来解决Hadoop无法把相关的数据定位到同一个node集合下的性能瓶颈。CoHadoop是对Hadoop的一个轻量级扩展,目的是允许应用层能控制数据的存储。应用层通过某种方式提示CoHadoop某些集合里的文件是相关性比较大的,可能需要合并,之后CoHadoop就尝试去转移这些文件以提高一定的数据读取效率。
5.1 研究意义
Hadoop++[6]项目其实也做过类似的事,它将同一个job产生的两个file共同放置,但是当有新文件注入系统的时候,它需要对数据重新组织。
CoHadoop的改进主要给以下几个操作带来了比较大的好处:索引(indexing),聚合(grouping),聚集(aggregation),纵向存储(columnar storage),合并(join)以及sessionization。而像日志分析这样的操作,涉及到的就是把一些参考数据合并起来或者进行sessionization。这可以体现CoHadoop的改进意义所在。
以下是paper关于CoHadoop的总结:
? 这是一种很灵活,动态,轻量级的共置相关数据文件的方案,而且是直接在HDFS上实现的。
? 在日志处理方面,确定了两个用例:join和sessionization,使得在查询处理方面得到了显著的性能提高。
? 作者还研究了CoHadoop的容错,分布式数据和数据丢失。
? 在不同的场景下测试了join和sessionization的效果。
接下来还是介绍下CoHadoop的设计思想。
5.2 改进设计介绍
HDFS本身存数据的时候是有冗余的。默认是存三分拷贝。这三份复制品会存在不同的地方。最简单是存在datanode里。默认的存放方式是第一份拷贝存在新建的本地诞生的node的block里(假设足够存),这叫写“亲和”(write affinity)。HDFS然后选择同一机架上的datanode存放第二个拷贝,选择不同机架上的一个datanode存第三份拷贝。这是HDFS的本来的机制。那么为了实现相关数据的共置存储,论文修改了存放策略。
以上Hadoop现有的存放策略主要是为了负载均衡,但是当应用需要从不同的文件里去取所需的数据的时候,如果能自定义一些策略,那可能会得到显著的提升。轻量级的CoHadoop使得开发自定义的策略变得简单。虽然分区在Hadoop里实现很简单,但是共置并不容易,Hadoop也没有提供这样类似的可行性功能实现。
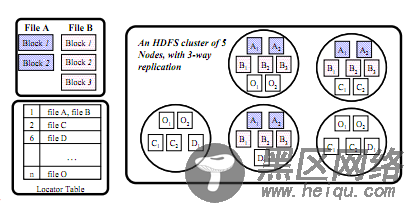
如图是CoHadoop的数据存放示意图。CoHadoop扩展了HDFS,提出了新的文件层属性——locator,并且修改了Hadoop的数据存放策略以使用这个locator。假设每个locator由一个整数值表示(也可以是别的表示方法),那么文件和locator之间可以是一个N:1的关系。每个HDFS的文件最多和一个locator关联,同一个locator可以关联很多文件。同一个locator下的文件存在同一个datanode集合里,而没有locator映射的文件依旧按照默认的Hadoop的存储机制存放。图中的A和B就属于同一个locator,A文件的两块block和B文件的三块Block结果存在了同一个datanode集合里。
为了更好地管理和跟踪这些locator和文件之间的映射信息,设计了一个新的数据结构——locatortable存在namenode里。它存放了每个locator映射的文件集。图中也可以看到。当namenode运行的时候,locator table是在内存里动态维护的,
关于数据存放策略的修改是这么做的:只要有一个新的和locator l关联的文件f被创建,会去locator table里查询是否存在一个实例是属于这个locator l的。如果不存在,就新增一条(l, f)在table里,并用HDFS默认的存放方式存这份文件的拷贝们。如果已经存在,就可以知道这个l映射的file list,如果从现有的存放了这个list内的文件的r个datanode里按一定方式(考虑空间)选出几个用于存新来的文件的拷贝的节点,存放这份文件的拷贝们。大致的意思就是这样。
关于日志的join和sessionization的改进,就不展开了。简单贴两个图。
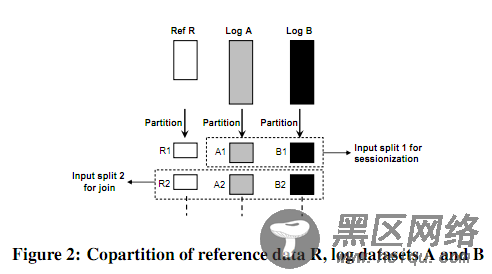
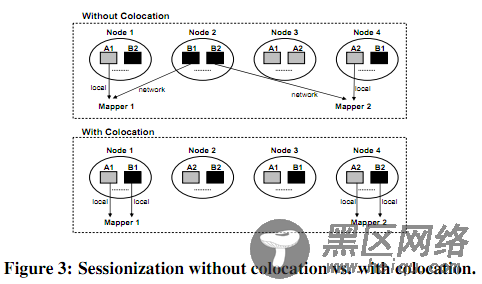
做sessionization,对于日志处理时候MapReduce计算的影响比较。