

本文是卡耐基梅隆大学的 Dana Van Aken、Andy Pavlo 和 Geoff Gordon 所写。这个项目展示了学术研究人员如何利用 AWS Cloud Credits for Research Program 来助力他们的科技突破的。
数据库管理系统(DBMS)是任何数据密集应用的关键部分。它们可以处理大量数据和复杂的工作负载,但同时也难以管理,因为有成百上千个“旋钮”(即配置变量)控制着各种要素,比如要使用多少内存做缓存和写入磁盘的频率。组织机构经常要雇佣专家来做调优,而专家对很多组织来说太过昂贵了。卡耐基梅隆大学数据库研究组的学生和研究人员在开发一个新的工具,名为 OtterTune,可以自动为 DBMS 的“旋钮”找到合适的设置。工具的目的是让任何人都可以部署 DBMS,即使没有任何数据库管理专长。
OtterTune 跟其他 DBMS 设置工具不同,因为它是利用对以前的 DBMS 调优知识来调优新的 DBMS,这显著降低了所耗时间和资源。OtterTune 通过维护一个之前调优积累的知识库来实现这一点,这些积累的数据用来构建机器学习(ML)模型,去捕获 DBMS 对不同的设置的反应。OtterTune 利用这些模型指导新的应用程序实验,对提升最终目标(比如降低延迟和增加吞吐量)给出建议的配置。
本文中,我们将讨论 OtterTune 的每一个机器学习流水线组件,以及它们是如何互动以便调优 DBMS 的设置。然后,我们评估 OtterTune 在 MySQL 和 Postgres 上的调优表现,将它的最优配置与 DBA 和其他自动调优工具进行对比。
OtterTune 是卡耐基梅隆大学数据库研究组的学生和研究人员开发的开源工具,所有的代码都托管在 Github 上,以 Apache License 2.0 许可证发布。
OtterTune 工作原理下图是 OtterTune 组件和工作流程
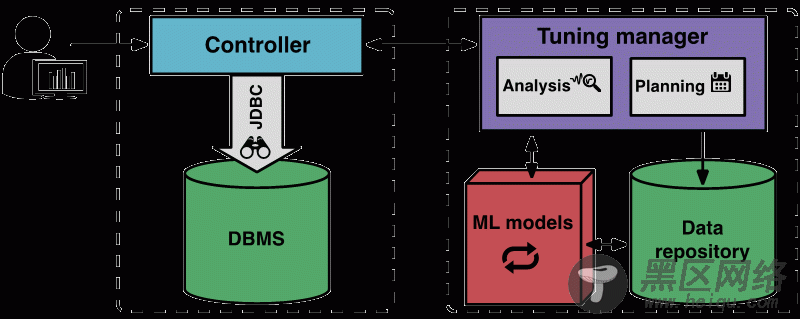
调优过程开始,用户告知 OtterTune 要调优的最终目标(比如,延迟或吞吐量),客户端控制器程序连接目标 DBMS,收集 Amazon EC2 实例类型和当前配置。
然后,控制器启动首次观察期,来观察并记录最终目标。观察结束后,控制器收集 DBMS 的内部指标,比如 MySQL 磁盘页读取和写入的计数。控制器将这些数据返回给调优管理器程序。
OtterTune 的调优管理器将接收到的指标数据保存到知识库。OtterTune 用这些结果计算出目标 DBMS 的下一个配置,连同预估的性能提升,返回给控制器。用户可以决定是否继续或终止调优过程。
注意OtterTune 对每个支持的 DBMS 版本维护了一份“旋钮”黑名单,包括了对调优无关紧要的部分(比如保存数据文件的路径),或者那些会产生严重或隐性后果(比如丢数据)的部分。调优过程开始时,OtterTune 会向用户提供这份黑名单,用户可以添加他们希望 OtterTune 避开的其它“旋钮”。
OtterTune 有一些预定假设,对某些用户可能会造成一定的限制。比如,它假设用户拥有管理员权限,以便控制器来修改 DBMS 配置。否则,用户必须在其他硬件上部署一份数据库拷贝给 OtterTune 做调优实验。这要求用户或者重现工作负载,或者转发生产 DBMS 的查询。完整的预设和限制请看我们的论文 。
机器学习流水线下图是 OtterTune ML 流水线处理数据的过程,所有的观察结果都保存在知识库中。
OtterTune 先将观察数据输送到“工作流特征化组件”(Workload Characterization component),这个组件可以识别一小部分 DBMS 指标,这些指标能最有效地捕捉到性能变化和不同工作负载的显著特征。
下一步,“旋钮识别组件”(Knob Identification component)生成一个旋钮排序表,包含哪些对 DBMS 性能影响最大的旋钮。OtterTune 接着把所有这些信息“喂”给自动调优器(Automatic Tuner),后者将目标 DBMS 的工作负载与知识库里最接近的负载进行映射,重新使用这份负载数据来生成更佳的配置。
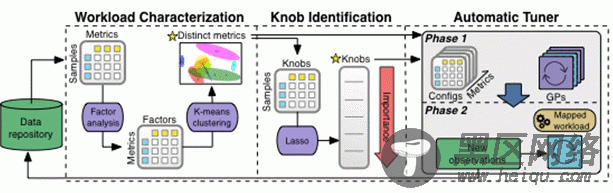
我们来深入挖掘以下机器学习流水线的每个组件。
工作负载特征化: OtterTune 利用 DBMS 的内部运行时指标来特征化某个工作负载的行为,这些指标精确地代表了工作负载,因为它们捕获了负载的多个方面行为。然而,很多指标是冗余的:有些是用不同的单位表示相同的度量值,其他的表示 DBMS 的一些独立组件,但它们的值高度相关。梳理冗余度量值非常重要,可以降低机器学习模型的复杂度。因此,我们基于相关性将 DBMS 的度量值集中起来,然后选出其中最具代表性的一个,具体说就是最接近中间值的。机器学习的后续组件将使用这些度量值。