旋钮识别: DBMS 可以有几百个旋钮,但只有一部分影响性能。OtterTune 使用一种流行的“特性-选择”技术,叫做 Lasso,来判断哪些旋钮对系统的整体性能影响最大。用这个技术处理知识库中的数据,OtterTune 得以确定 DBMS 旋钮的重要性顺序。
接着,OtterTune 必须决定在做出配置建议时使用多少个旋钮,旋钮用的太多会明显增加 OtterTune 的调优时间,而旋钮用的太少则难以找到最好的配置。OtterTune 用了一个增量方法来自动化这个过程,在一次调优过程中,逐步增加使用的旋钮。这个方法让 OtterTune 可以先用少量最重要的旋钮来探索并调优配置,然后再扩大范围考虑其他旋钮。
自动调优器: 自动调优器组件在每次观察阶段后,通过两步分析法来决定推荐哪个配置。
首先,系统使用工作负载特征化组件找到的性能数据来确认与当前的目标 DBMS 工作负载最接近的历史调优过程,比较两者的度量值以确认哪些值对不同的旋钮设置有相似的反应。
然后,OtterTune 尝试另一个旋钮配置,将一个统计模型应用到收集的数据,以及知识库中最贴近的工作负载数据。这个模型让 OtterTune 预测 DBMS 在每个可能的配置下的表现。OtterTune 调优下一个配置,在探索(收集用来改进模型的信息)和利用(贪婪地接近目标度量值)之间交替进行。
实现OtterTune 用 Python 编写。
对于工作负载特征化和旋钮识别组件,运行时性能不是着重考虑的,所以我们用 scikit-learn实现对应的机器学习算法。这些算法运行在后台进程中,把新生成的数据吸收到知识库里。
对于自动调优组件,机器学习算法就非常关键了。每次观察阶段完成后就需要运行,吸收新数据以便 OtterTune 挑选下一个旋钮来进行测试。由于需要考虑性能,我们用 TensorFlow来实现。
为了收集 DBMS 的硬件、旋钮配置和运行时性能指标,我们把 OLTP-Bench 基准测试框架集成到 OtterTune 的控制器内。
实验设计我们比较了 OtterTune 对 MySQL 和 Postgres 做出的最佳配置与如下配置方案进行了比较,以便评估:
默认: DBMS 初始配置
调优脚本: 一个开源调优建议工具做出的配置
DBA: 人类 DBA 选择的配置
RDS: 将亚马逊开发人员管理的 DBMS 的定制配置应用到相同的 EC2 实例类型。
我们在亚马逊 EC2 竞价实例上执行了所有的实验。每个实验运行在两个实例上,分别是m4.large 和 m3.xlarge 类型:一个用于 OtterTune 控制器,一个用于目标 DBMS 部署。OtterTune 调优管理器和知识库部署在本地一台 20 核 128G 内存的服务器上。
工作负载用的是 TPC-C,这是评估联机交易系统性能的工业标准。
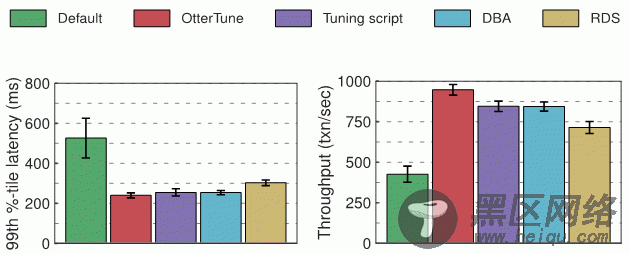
评估我们给每个实验中的数据库 —— MySQL 和 Postgres —— 测量了延迟和吞吐量,下面的图表显示了结果。第一个图表显示了“第99百分位延迟”的数量,代表“最差情况下”完成一个事务的时长。第二个图表显示了吞吐量结果,以平均每秒执行的事务数来衡量。
MySQL 实验结果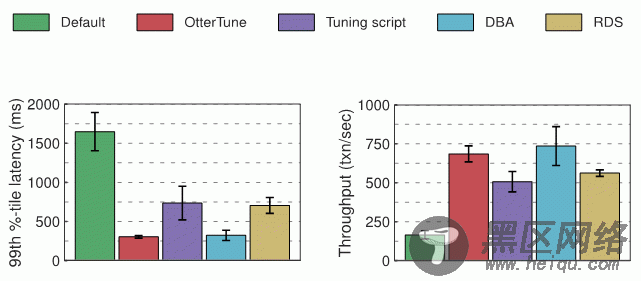
OtterTune 生成的最佳配置与调优脚本和 RDS 的配置相比,OtterTune 让 MySQL 的延迟下降了大约 60%,吞吐量提升了 22% 到 35%。OtterTune 还生成了一份几乎跟 DBA 一样好的配置。
在 TPC-C 负载下,只有几个 MySQL 的旋钮显著影响性能。OtterTune 和 DBA 的配置给这几个旋钮设置了很好的值。RDS 表现略逊一筹,因为给一个旋钮配置了欠佳的值。调优脚本表现最差,因为只修改一个旋钮。
Postgres 实验结果