
本文将介绍利用MapReduce操作HBase,借助最熟悉的单词计数案例WordCount,将WordCount的统计结果存储到HBase,而不是HDFS。
开发环境硬件环境:CentOS 6.5 服务器4台(一台为Master节点,三台为Slave节点)
软件环境:Java 1.7.0_45、Eclipse Juno Service Release 2、Hadoop-1.2.1、hbase-0.94.20。
1)输入文件
file0.txt(WordCountHbaseWriter\input\file0.txt) Hello World Bye World file1.txt(WordCountHbaseWriter\input\file1.txt) Hello Hadoop Goodbye Hadoop2)输出HBase数据库
以下为输出数据库wordcount的数据库结构,以及预期的输出结果,如下图所示:

WordCountHbaseMapper程序和WordCount的Map程序一样,Map输入为每一行数据,例如”Hello World Bye World”,通过StringTokenizer类按空格分割成一个个单词,
通过context.write(word, one);输出为一系列< key,value>键值对:<”Hello”,1><”World”,1><”Bye”,1><”World”,1>。
详细源码请参考:WordCountHbaseWriter\src\com\zonesion\hbase\WordCountHbaseWriter.java
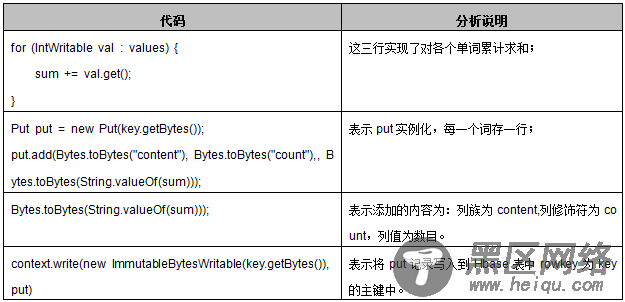
WordCountHbaseReducer继承的是TableReducer类,在Hadoop中TableReducer继承Reducer类,它的原型为TableReducer< KeyIn,Values,KeyOut>,前两个参数必须对应Map过程的输出类型key/value类型,第三个参数为ImmutableBytesWritable,即为不可变类型。reduce(Text key, Iterable< IntWritable> values,Context context)具体处理过程分析如下表所示。
详细源码请参考:WordCountHbaseWriter\src\com\zonesion\hbase\WordCountHbaseWriter.java
public static class WordCountHbaseReducer extends TableReducer<Text, IntWritable, ImmutableBytesWritable> { public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) {// 遍历求和 sum += val.get(); } Put put = new Put(key.getBytes());//put实例化,每一个词存一行 //列族为content,列修饰符为count,列值为数目 put.add(Bytes.toBytes("content"), Bytes.toBytes("count"), Bytes.toBytes(String.valueOf(sum))); context.write(new ImmutableBytesWritable(key.getBytes()), put);// 输出求和后的<key,value> } } 4、 驱动函数实现与WordCount的驱动类不同,在Job配置的时候没有配置job.setReduceClass(),而是用以下方法执行Reduce类:
TableMapReduceUtil.initTableReducerJob(tablename, WordCountHbaseReducer.class, job);
该方法指明了在执行job的reduce过程时,执行WordCountHbaseReducer,并将reduce的结果写入到表明为tablename的表中。特别注意:此处的TableMapReduceUtil是hadoop.hbase.mapreduce包中的,而不是hadoop.hbase.mapred包中的,否则会报错。
详细源码请参考:WordCountHbaseWriter\src\com\zonesion\hbase\WordCountHbaseWriter.java
特别注意:用户可先通过jps命令查看Hadoop集群和Hbase服务是否启动,如果Hadoop集群和Hbase服务已经启动,则不需要执行此操作。
2)部署源码 #设置工作环境 [hadoop@K-Master ~]$ mkdir -p /usr/hadoop/workspace/Hbase #部署源码 将WordCountHbaseWriter文件夹拷贝到/usr/hadoop/workspace/Hbase/ 路径下;… 你可以直接 下载 WordCountHbaseWriter
------------------------------------------分割线------------------------------------------
FTP地址:ftp://ftp1.linuxidc.com
用户名:ftp1.linuxidc.com
密码:
在 2015年LinuxIDC.com\3月\HBase入门基础教程
------------------------------------------分割线------------------------------------------
3)修改配置文件a) 查看hbase核心配置文件hbase-site.xml的hbase.zookeeper.quorum属性
3、部署运行 3)修改配置文件”查看hbase核心配置文件hbase-site.xml的hbase.zookeeper.quorum属性;
b) 修改项目WordCountHbaseWriter/src/config.properties属性文件
将项目WordCountHbaseWriter/src/config.properties属性文件的hbase.zookeeper.quorum属性值修改为上一步查询到的属性值,保持config.properties文件的hbase.zookeeper.quorum属性值与hbase-site.xml文件的hbase.zookeeper.quorum属性值一致;
#切换工作目录 [hadoop@K-Master ~]$ cd /usr/hadoop/workspace/Hbase/WordCountHbaseWriter #修改属性值 [hadoop@K-Master WordCountHbaseWriter]$ vim src/config.properties hbase.zookeeper.quorum=K-Master #拷贝src/config.properties文件到bin/文件夹 [hadoop@K-Master WordCountHbaseWriter]$ cp src/config.properties bin/ 4)上传输入文件 #创建输入文件夹 [hadoop@K-Master WordCountHbaseWriter]$ hadoop fs -mkdir HbaseWriter/input/ #上传文件到输入文件夹 [hadoop@K-Master WordCountHbaseWriter]$ hadoop fs -put input/file* HbaseWriter/input/ #查看上传文件是否成功 [hadoop@K-Master WordCountHbaseWriter]$ hadoop fs -ls HbaseWriter/input/ Found 2 items -rw-r--r-- 3 hadoop supergroup 22 2014-12-30 17:39 /user/hadoop/HbaseWriter/input/file0.txt -rw-r--r-- 3 hadoop supergroup 28 2014-12-30 17:39 /user/hadoop/HbaseWriter/input/file1.txt 5)编译文件 #执行编译 [hadoop@K-Master WordCountHbaseWriter]$ javac -classpath /usr/hadoop/hadoop-core-1.2.1.jar:/usr/hadoop/lib/commons-cli-1.2.jar:lib/zookeeper-3.4.5.jar:lib/hbase-0.94.20.jar -d bin/ src/com/zonesion/hbase/*.java #查看编译是否成功 [hadoop@K-Master WordCountHbaseWriter]$ ls bin/com/zonesion/hbase/ -la total 24 drwxrwxr-x 2 hadoop hadoop 4096 Dec 30 17:20 . drwxrwxr-x 3 hadoop hadoop 4096 Dec 30 17:20 .. -rw-rw-r-- 1 hadoop hadoop 3446 Dec 30 17:29 PropertiesHelper.class -rw-rw-r-- 1 hadoop hadoop 3346 Dec 30 17:29 WordCountHbaseWriter.class -rw-rw-r-- 1 hadoop hadoop 1817 Dec 30 17:29 WordCountHbaseWriter$WordCountHbaseMapper.class -rw-rw-r-- 1 hadoop hadoop 2217 Dec 30 17:29 WordCountHbaseWriter$WordCountHbaseReducer.class 6) 打包Jar文件 #拷贝lib文件夹到bin文件夹 [hadoop@K-Master WordCountHbaseWriter]$ cp –r lib/ bin/ #打包Jar文件 [hadoop@K-Master WordCountHbaseWriter]$ jar -cvf WordCountHbaseWriter.jar -C bin/ . added manifest adding: lib/(in = 0) (out= 0)(stored 0%) adding: lib/zookeeper-3.4.5.jar(in = 779974) (out= 721150)(deflated 7%) adding: lib/guava-11.0.2.jar(in = 1648200) (out= 1465342)(deflated 11%) adding: lib/protobuf-java-2.4.0a.jar(in = 449818) (out= 420864)(deflated 6%) adding: lib/hbase-0.94.20.jar(in = 5475284) (out= 5038635)(deflated 7%) adding: com/(in = 0) (out= 0)(stored 0%) adding: com/zonesion/(in = 0) (out= 0)(stored 0%) adding: com/zonesion/hbase/(in = 0) (out= 0)(stored 0%) adding: com/zonesion/hbase/WordCountHbaseWriter.class(in = 3136) (out= 1583)(deflated 49%) adding: com/zonesion/hbase/WordCountHbaseWriter$WordCountHbaseMapper.class(in = 1817) (out= 772)(deflated 57%) adding: com/zonesion/hbase/WordCountHbaseWriter$WordCountHbaseReducer.class(in = 2217) (out= 929)(deflated 58%) 7)运行实例 [hadoop@K-Master WordCountHbaseWriter]$ hadoop jar WordCountHbaseWriter.jar com.zonesion.hbase.WordCountHbaseWriter /user/hadoop/HbaseWriter/input/ ...................省略............. 14/12/30 11:23:59 INFO input.FileInputFormat: Total input paths to process : 2 14/12/30 11:23:59 INFO util.NativeCodeLoader: Loaded the native-hadoop library 14/12/30 11:23:59 WARN snappy.LoadSnappy: Snappy native library not loaded 14/12/30 11:24:05 INFO mapred.JobClient: Running job: job_201412161748_0020 14/12/30 11:24:06 INFO mapred.JobClient: map 0% reduce 0% 14/12/30 11:24:27 INFO mapred.JobClient: map 50% reduce 0% 14/12/30 11:24:30 INFO mapred.JobClient: map 100% reduce 0% 14/12/30 11:24:39 INFO mapred.JobClient: map 100% reduce 100% 14/12/30 11:24:41 INFO mapred.JobClient: Job complete: job_201412161748_0020 14/12/30 11:24:41 INFO mapred.JobClient: Counters: 28 14/12/30 11:24:41 INFO mapred.JobClient: Job Counters 14/12/30 11:24:41 INFO mapred.JobClient: Launched reduce tasks=1 14/12/30 11:24:41 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=20955 14/12/30 11:24:41 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0 14/12/30 11:24:41 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0 14/12/30 11:24:41 INFO mapred.JobClient: Launched map tasks=2 14/12/30 11:24:41 INFO mapred.JobClient: Data-local map tasks=2 14/12/30 11:24:41 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=11527 14/12/30 11:24:41 INFO mapred.JobClient: File Output Format Counters 14/12/30 11:24:41 INFO mapred.JobClient: Bytes Written=0 14/12/30 11:24:41 INFO mapred.JobClient: FileSystemCounters 14/12/30 11:24:41 INFO mapred.JobClient: FILE_BYTES_READ=104 14/12/30 11:24:41 INFO mapred.JobClient: HDFS_BYTES_READ=296 14/12/30 11:24:41 INFO mapred.JobClient: FILE_BYTES_WRITTEN=239816 14/12/30 11:24:41 INFO mapred.JobClient: File Input Format Counters 14/12/30 11:24:41 INFO mapred.JobClient: Bytes Read=50 14/12/30 11:24:41 INFO mapred.JobClient: Map-Reduce Framework 14/12/30 11:24:41 INFO mapred.JobClient: Map output materialized bytes=110 14/12/30 11:24:41 INFO mapred.JobClient: Map input records=2 14/12/30 11:24:41 INFO mapred.JobClient: Reduce shuffle bytes=110 14/12/30 11:24:41 INFO mapred.JobClient: Spilled Records=16 14/12/30 11:24:41 INFO mapred.JobClient: Map output bytes=82 14/12/30 11:24:41 INFO mapred.JobClient: Total committed heap usage (bytes)=417546240 14/12/30 11:24:41 INFO mapred.JobClient: CPU time spent (ms)=1110 14/12/30 11:24:41 INFO mapred.JobClient: Combine input records=0 14/12/30 11:24:41 INFO mapred.JobClient: SPLIT_RAW_BYTES=246 14/12/30 11:24:41 INFO mapred.JobClient: Reduce input records=8 14/12/30 11:24:41 INFO mapred.JobClient: Reduce input groups=5 14/12/30 11:24:41 INFO mapred.JobClient: Combine output records=0 14/12/30 11:24:41 INFO mapred.JobClient: Physical memory (bytes) snapshot=434167808 14/12/30 11:24:41 INFO mapred.JobClient: Reduce output records=5 14/12/30 11:24:41 INFO mapred.JobClient: Virtual memory (bytes) snapshot=2192027648 14/12/30 11:24:41 INFO mapred.JobClient: Map output records=8 8)查看输出结果 #另外开启一个终端,输入hbase shell命令进入hbase shell命令行 [hadoop@K-Master ~]$ hbase shell HBase Shell; enter 'help<RETURN>' for list of supported commands. Type "exit<RETURN>" to leave the HBase Shell Version 0.94.20, r09c60d770f2869ca315910ba0f9a5ee9797b1edc, Fri May 23 22:00:41 PDT 2014 hbase(main):002:0> scan 'wordcount' ROW COLUMN+CELL Bye column=content:count, timestamp=1419932527321, value=1 Goodbye column=content:count, timestamp=1419932527321, value=1 Hadoope column=content:count, timestamp=1419932527321, value=2 Hellope column=content:count, timestamp=1419932527321, value=2 Worldpe column=content:count, timestamp=1419932527321, value=2 5 row(s) in 0.6370 seconds