
随着表中行数的增多,管理和性能性能影响也将随之增加。备份将要花费更多时间,恢复也将 要花费更说的时间,对整个数据表的查询也将花费更多时间。通过把一个表中的行分为几个部分,可以减少大型表的管理和性能问题,以这种方式划分发表数据的方法称为对表的分区。分区表的优势:
(1)改善查询性能:对分区对象的查询可以仅搜索自己关心的分区,提高检索速度;
(2)方便数据管理:因为分区表的数据存储在多个部分中,所以按分区加载和删除数据比在大表中加载和删除数据更容易;
(3)方便备份恢复:因为分区比被分区的表要小,所以针对分区的备份和恢复方法要比备份和恢复整个表的方法多。
一、Oracle数据库提供对表或索引的分区方法有几种:
1)范围分区
2)列表分区
3)散列分区(hash分区)
4)复合分区(子分区)
二、实例演示Oracle对表或索引的分区操作
1,创建4个测试用的表空间,每个表空间作为一个独立分区(考虑到Oracle中分区映射的实现方式,建议将表中的分区数设置为2的乘方,以便使数据均匀分布)
SYS>create tablespace partition1 datafile '/home/oracle/app/oradata/orcl/partition1.dbf' size 20m;
SYS>create tablespace partition2 datafile '/home/oracle/app/oradata/orcl/partition2.dbf' size 20m;
SYS>create tablespace partition3 datafile '/home/oracle/app/oradata/orcl/partition3.dbf' size 20m;
SYS>create tablespace partition4 datafile '/home/oracle/app/oradata/orcl/partition4.dbf' size 20m;
2,范围分区
范围分区就是对数据表中的某个值的范围进行分区,根据某个值的范围,决定将该数据存储在哪个分区上。如根据序号分区,根据业务记录的创建日期进行分区等(联通每个月的账单记录就用的分区表存储)。
需求描述:有一个物料交易表,表名:material_transactions。该表将来可能有千万级的数据记录数。要求在建该表的时候使用分区表。这时候我们可以使用序号分区三个区,每个区中预计存储三千万的数据,也可以使用日期分区,如每五年的数据存储在一个分区上。
根据交易记录的序号分区建表:----为了测试需要做以下修改:
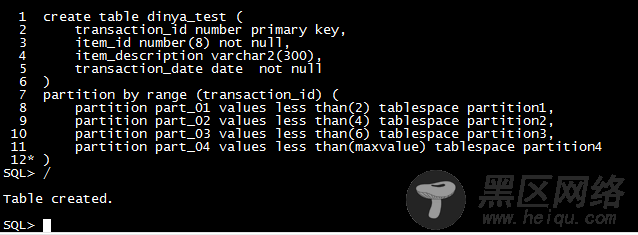
交易号小于2的记录存储在分区1上,大于等于2且小于4的交易号储存在分区2上,大于等于4且小于6的交易号储存在分区3上,大于等于6的交易号存储在分区4上。(不必为最后一个分区指定最大值,maxvalue关键字会告诉Oracle使用这个分区来存储在前面几个分区中不能储存的数据)。
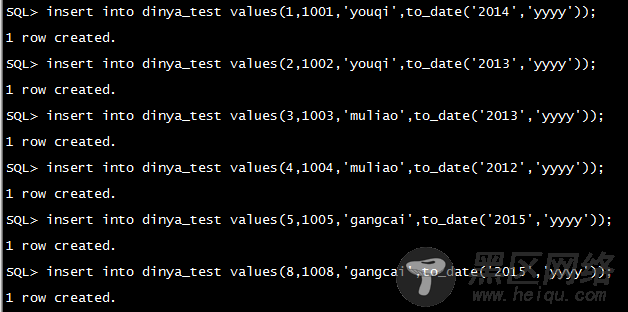
2.1,向分区表里面插入数据:
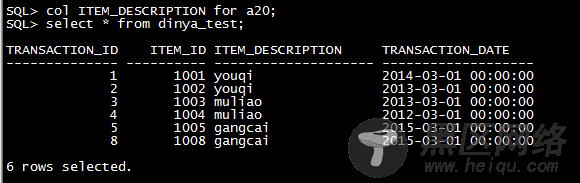
2.2,查询表数据
不指定分区:
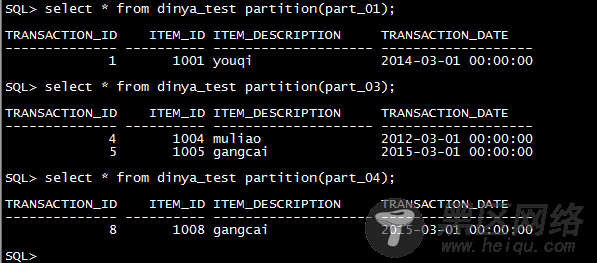
指定分区:
2.3,更改表数据

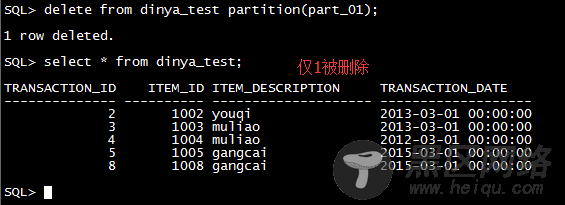
2.4,删除表数据
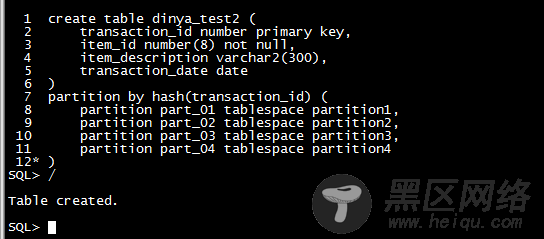
3,散列分区(hash分区)
除范围分区外,Oracle还支持散列分区。散列分区通过在分区键值上执行一个散列函数来说决定数据的物理位置。在范围分区中,分区键的连续值通常储存在相同的分区中。而在散列分区中,连续的分区键值不必储存在相同的分区中。散列分区把记录分布在比范围分区更多的分区上,这减少了I/O争用的可能性。
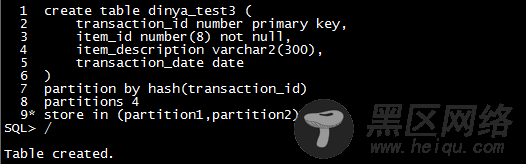
还有一种定义hash分区的方式是:partition by hash(column) partition n store in (tbs1,,,tbsm)。表空间的数目不必等于分区的数目,即n不一定等于m,如果指定的分区数目比表空间的数目多,则分区将会以循环的方式分配到表空间中,一个表空间可以含有多个分区:
4,列表分区
列表分区告诉Oracle所有可能的值,并指定应该插入相应行的分区,它适用于表的数据量很大但是某一列的值只有少量几种。
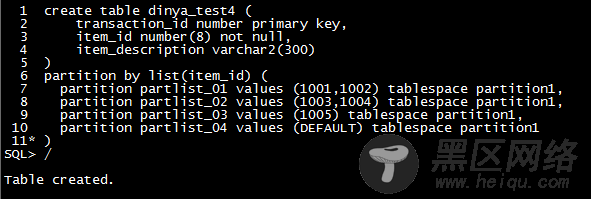
在列表分区中,可以使用关键字default来指定未列出的所有情况。(上述4个分区创建在一个表空间中)
5,复合分区(子分区)