
update tb_bank set account = account+100 where id=1; 2 select * from tb_bank where id=1;//查询结果:1100
⑤ session1第二次查询:
select * from tb_bank where id=1;//查询结果:1100。和③中查询结果对比,session1两次查询结果不一致。
查看查询结果可知,session1在开启事务期间发生重复读结果不一致,所以可以看到read commit事务隔离级别是不可重复读的。显然这种结果不是我们想要的。
(2)repeatable-read可重复读重置数据,使数据恢复到account=1000
① 新建两个session,分别设置
set session transaction isolation level repeatable read;
重复(1)中的②③④
⑤ session1第二次查询:
select * from tb_bank where id=1;//查询结果为:1000
从结果可知,repeatable-read的隔离级别下,多次读取结果是不受其他事务影响的。是可重复读的。到这里产生了一个疑问,那session1在读到的结果中依然是session2更新前的结果,那session1中继续转入100能得到正确的1200的结果吗?
继续操作:
⑥ session1转入100:
update tb_bank set account=account+100 where id=1;
到这里感觉自己被骗了,锁,锁,锁。session1的更新语句被阻塞了。只有session2中的update语句commit之后,session1中才能继续执行。session的执行结果是1200,这时发现session1并不是用1000+100计算的,因为可重复读的隔离级别下使用了MVCC机制,select操作不会更新版本号,是快照读(历史版本)。insert、update和delete会更新版本号,是当前读(当前版本)。
3、通过sql演示-----repeatable-read的幻读在业务逻辑中,通常我们先获取数据库中的数据,然后在业务中判断该条件是否符合自己的业务逻辑,如果是的话,那么就可以插入一部分数据。但是mysql的快照读可能在这个过程中会产生意想不到的结果。
场景模拟:
session1开启事务,先查询有没有小张的账户信息,没有的话就插入一条。这是session2也执行和session1同样的操作。
准备工作:插入两条数据
INSERT INTO `demo`.`tb_bank`(`id`, `name`, `account`) VALUES (2, '小红', 800); INSERT INTO `demo`.`tb_bank`(`id`, `name`, `account`) VALUES (3, '小磊', 6000);
(1)repeatable-read的幻读① 新建两个session都执行
set session transaction isolation level repeatable read; start transaction; select * from tb_bank;//查询结果:(这一步很重要,直接决定了快照生成的时间)
结果都是:
② session2插入数据
INSERT INTO `demo`.`tb_bank`(`id`, `name`, `account`) VALUES (4, '小张', 8000); 2 select * from tb_bank;
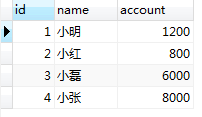
结果数据插入成功。此时session2提交事务
commit;
③ session1进行插入
插入之前我们先看一下当前session1是否有id=4的数据
select * from tb_bank;
结果session1中没有该条记录,这时按照我们通常的业务逻辑,此时应该是能成功插入id=4的数据。继续执行:
INSERT INTO `demo`.`tb_bank`(`id`, `name`, `account`) VALUES (4, '小张', 8000);
结果插入失败,提示该条已经存在,但是我们查询里面并没有这一条数据啊。为什么会插入失败呢?