
改为下面的配置。后面的配置文件的修改类似。
<property> <name>fs.defaultFS</name> <value>hdfs://Master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/usr/local/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property>3, 文件hdfs-site.xml,因为只有一个Slave,所以dfs.replication的值设为1。
<property> <name>dfs.namenode.secondary.http-address</name> <value>Master:50090</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/data</value> </property> <property> <name>dfs.replication</name> <value>1</value> </property>4, 文件mapred-site.xml,这个文件不存在,首先需要从模板中复制一份:
cp mapred-site.xml.template mapred-site.xml然后配置修改如下:
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>5, 文件yarn-site.xml:
<property> <name>yarn.resourcemanager.hostname</name> <value>Master</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>配置好后,将 Master 上的 Hadoop 文件复制到各个节点上(虽然直接采用 scp 复制也可以正确运行,但会有所不同,如符号链接 scp 过去后就有点不一样了。所以先打包再复制比较稳妥)。
cd /usr/local sudo tar -zcf ./hadoop.tar.gz ./hadoop scp ./hadoop.tar.gz Slave1:/home/hadoop在Slave1上执行:
sudo tar -zxf ~/hadoop.tar.gz -C /usr/local sudo chown -R hadoop:hadoop /usr/local/hadoop如果之前有跑过伪分布式模式,建议切换到集群模式前先删除之前的临时文件:
rm -r /usr/local/hadoop/tmp切换 Hadoop 模式应删除之前的临时文件
切换 Hadoop 的模式,不管是从集群切换到伪分布式,还是从伪分布式切换到集群,如果遇到无法正常启动的情况,可以删除所涉及节点的临时文件夹,这样虽然之前的数据会被删掉,但能保证集群正确启动。或者可以为集群模式和伪分布式模式设置不同的临时文件夹(未验证)。所以如果集群以前能启动,但后来启动不了,特别是 DataNode 无法启动,不妨试着删除所有节点(包括 Slave 节点)上的 tmp 文件夹,重新执行一次 bin/hdfs namenode -format,再次启动试试。
然后在Master节点上就可以启动hadoop了。
cd /usr/local/hadoop/ bin/hdfs namenode -format # 首次运行需要执行初始化,后面不再需要 sbin/start-dfs.sh sbin/start-yarn.sh通过命令jps可以查看各个节点所启动的进程。

可以看到Master节点启动了NameNode、SecondrryNameNode、ResourceManager进程。
通过jps查看Slave的Hadoop进程
Slave节点则启动了DataNode和NodeManager进程。
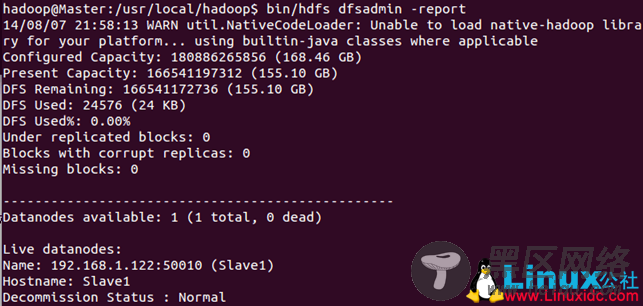
另外也可以在Master节点上通过命令bin/hdfs dfsadmin -report查看DataNode是否正常启动。例如我这边一共有1个Datanodes。
通过查看启动日志分析启动失败原因
有时Hadoop集群无法正确启动,如 Master 上的 NameNode 进程没有顺利启动,这时可以查看启动日志来排查原因,不过新手可能需要注意几点: