前两天发表利用FormData进行文件上传,然后有人问要是大文件几个G上传怎么搞,常见的不就是分片再搞下断点续传,动动手差不多也能搞出来,只不过要深入的话,考虑的东西还是很多。由于断点续传之前写个几篇,这里试试利用FormData来进行分片上传。
.NET Core Web APi文件分片上传
这里我们依然是使用FormData来上传,只不过在上传之前对文件进行分片处理,如下HTML代码
<div> <div> <div> <input type="file" /> </div> </div> <div> <div> <input type="submit" value="上传" /> </div> </div> </div>
接下来则是上传脚本,如下:
$(function () { $('#submit').click(function () { UploadFile($('#file')[0].files); }); });
简单来说只需实现上述UploadFile方法,对大文件进行分片处理,然后上传就完事,文件上传后大致如下图所示,最后只需将所有文件进行合并处理为目标文件即可
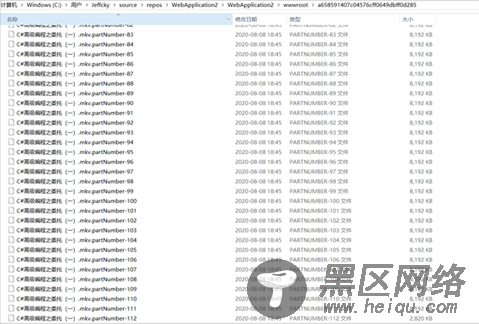
接下来我们详细讲讲如何实现,当然重点就在于如何进行分片处理,我们拿到上传目标文件,然后通过slice方法进行分片,在分片处理之前我们定义缓冲区大小(默认为8兆),然后循环遍历文件大小,然后将分片数据塞入分片数组,最后利用循环或者队列先进先出机制获取数组分片元素上传。
function UploadFile(targetFile) { // 创建上传文件分片缓冲区 var fileChunks = []; // 目标文件 var file = targetFile[0]; // 设置分片缓冲区大小 var maxFileSizeMB = 8; var bufferChunkSize = maxFileSizeMB * (1024 * 1024); // 读取文件流起始位置 var fileStreamPos = 0; // 设置下一次读取缓冲区初始大小 var endPos = bufferChunkSize; // 文件大小 var size = file.size; // 将文件进行循环分片处理塞入分片数组 while (fileStreamPos < size) { var fileChunkInfo = { file: file.slice(fileStreamPos, endPos), start: fileStreamPos, end: endPos } fileChunks.push(fileChunkInfo); fileStreamPos = endPos; endPos = fileStreamPos + bufferChunkSize; } // 获取上传文件分片总数量 var totalParts = fileChunks.length; var partCount = 0; // 循环调用上传每一片 while (chunk = fileChunks.shift()) { partCount++; // 上传文件命名约定 var filePartName = file.name + ".partNumber-" + partCount; chunk.filePartName = filePartName; // url参数 var url = 'partNumber=' + partCount + '&chunks=' + totalParts + '&size=' + bufferChunkSize + '&start=' + chunk.start + '&end=' + chunk.end + '&total=' + size; chunk.urlParameter = url; // 上传文件 UploadFileChunk(chunk); } }
上述关于分片塞入数组就不用再废话,这里我们将每一片文件命名先进行一个约定(文件名+“.partNumber” + 分片号),以便所有分片上传完成后获取按照文件名中的分片号对其进行排序合并,这也就是合并文件的依据。接下来就是上传每一片文件
function UploadFileChunk(chunk) { var data = new FormData(); data.append("file", chunk.file, chunk.filePartName); $.ajax({ url: '/api/upload/upload?' + chunk.urlParameter, type: "post", cache: false, contentType: false, processData: false, data: data, }); }
我们可以看到在URL上额外加了其他参数,为什么要加上这些参数呢?主要为解决几个问题,其一:前端确认缓冲区大小,我们获取前端确认的缓冲区大小,这样后台不用写死,更加灵活,万一后续进行了修改,谁知道呢?其二:我们怎么确定文件是否已经全部上传完了呢?在URL上我们添加分片总数和文件实际大小来完全确定文件已经全部上传和文件完整无缺。当然也额外添加了每一片读取的起始位置和结束位置,若有所需也可以利用。多余的就不用我再解释。接下来我们看看后台如何对每一片进行处理呢?在.NET Core中实际上提供了对应APi来专门读取FormData数据,利用Microsoft.AspNetCore.WebUtilities命名空间下的MultipartReader类。
首先我们判断是否请求内容是否为FormData,同时通过上下文获取上述文件读取类的参数boundary,如下:
private bool IsMultipartContentType(string contentType) { return !string.IsNullOrEmpty(contentType) && contentType.IndexOf("multipart/", StringComparison.OrdinalIgnoreCase) >= 0; } private string GetBoundary(string contentType) { var elements = contentType.Split(' '); var element = elements.Where(entry => entry.StartsWith("boundary=")).First(); var boundary = element.Substring("boundary=".Length); if (boundary.Length >= 2 && boundary[0] == '"' && boundary[boundary.Length - 1] == '"') { boundary = boundary.Substring(1, boundary.Length - 2); } return boundary; } private string GetFileName(string contentDisposition) { return contentDisposition .Split(';') .SingleOrDefault(part => part.Contains("filename")) .Split('=') .Last() .Trim('"'); }
接下来我们定义分片类而获取URL上每一片的参数,如下: