public class FileChunk { //文件名 public string FileName { get; set; } /// <summary> /// 当前分片 /// </summary> public int PartNumber { get; set; } /// <summary> /// 缓冲区大小 /// </summary> public int Size { get; set; } /// <summary> /// 分片总数 /// </summary> public int Chunks { get; set; } /// <summary> /// 文件读取起始位置 /// </summary> public int Start { get; set; } /// <summary> /// 文件读取结束位置 /// </summary> public int End { get; set; } /// <summary> /// 文件大小 /// </summary> public int Total { get; set; } }
接下来在提交控制器方法上去读取每一片数据如下
if (!IsMultipartContentType(context.Request.ContentType)) { return BadRequest(); } var boundary = GetBoundary(context.Request.ContentType); if (string.IsNullOrEmpty(boundary)) { return BadRequest(); } var reader = new MultipartReader(boundary, context.Request.Body); var section = await reader.ReadNextSectionAsync();
然后就是循环每一片(section),若不为空说明还存有分片文件,然后读取URL上的缓冲区大小,如下:
while (section != null) { //chunk为控制器方法上类FileChunk参数 var buffer = new byte[chunk.Size]; var fileName = GetFileName(section.ContentDisposition); //这里获取文件名便于查找指定文件夹下所有文件 chunk.FileName = fileName; var path = Path.Combine(_environment.WebRootPath, DEFAULT_FOLDER, fileName); using (var stream = new FileStream(path, FileMode.Append)) { int bytesRead; do { bytesRead = await section.Body.ReadAsync(buffer, 0, buffer.Length); stream.Write(buffer, 0, bytesRead); } while (bytesRead > 0); } section = await reader.ReadNextSectionAsync(); }
在利用内置APi读取FormData数据时,在.NET Core 3.x会抛出如下异常:
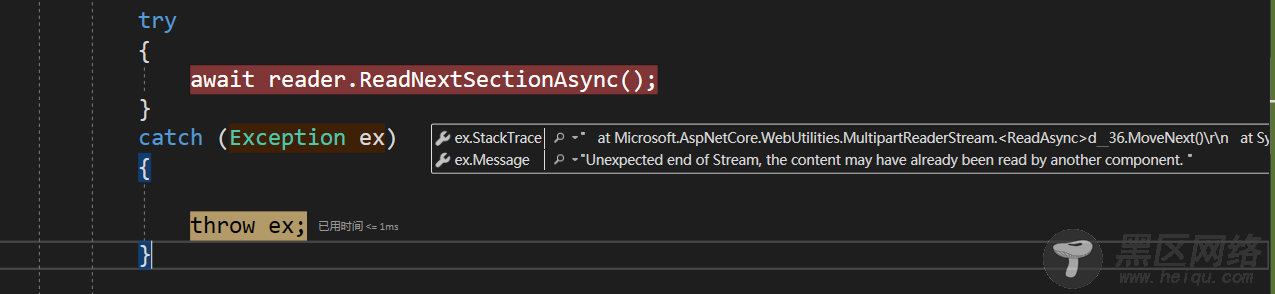
大致原因出在.NET Core内置提供了对于参数的绑定和此方法读取貌似有点冲突导致,我们实现如下特性移除对应绑定,然后将其添加到文件上传方法上即可
[AttributeUsage(AttributeTargets.Class | AttributeTargets.Method)] public sealed class DisableFormValueModelBindingAttribute : Attribute, IResourceFilter { public void OnResourceExecuting(ResourceExecutingContext context) { var factories = context.ValueProviderFactories; factories.RemoveType<FormValueProviderFactory>(); factories.RemoveType<FormFileValueProviderFactory>(); factories.RemoveType<JQueryFormValueProviderFactory>(); } public void OnResourceExecuted(ResourceExecutedContext context) { } }
所有分片文件上传完成后则是合并文件,合并的依据则是判断URL上当前分片数和分片总数是否相等,如下:
//计算上传文件大小实时反馈进度(TODO) //合并文件(可能涉及转码等) if (chunk.PartNumber == chunk.Chunks) { await MergeChunkFile(chunk); }
既然是合并文件那就需要通过分片文件名称上末尾的分片号进行排序和拿到每一个分片文件路径以便合并后删除所有分片文件,所以我们定义如下类
public class FileSort { public const string PART_NUMBER = ".partNumber-"; /// <summary> /// 文件名 /// </summary> public string FileName { get; set; } /// <summary> /// 文件分片号 /// </summary> public int PartNumber { get; set; } }
最终合并文件方法,如下:
public async Task MergeChunkFile(FileChunk chunk) { //文件上传目录名 var uploadDirectoryName = Path.Combine(_environment.WebRootPath, DEFAULT_FOLDER, chunk.FileName); //分片文件命名约定 var partToken = FileSort.PART_NUMBER; //上传文件实际名称 var baseFileName = chunk.FileName.Substring(0, chunk.FileName.IndexOf(partToken)); //根据命名约定查询指定目录下符合条件的所有分片文件 var searchpattern = $"{Path.GetFileName(baseFileName)}{partToken}*"; //获取所有分片文件列表 var filesList = Directory.GetFiles(Path.GetDirectoryName(uploadDirectoryName), searchpattern); if (!filesList.Any()) { return; } var mergeFiles = new List<FileSort>(); foreach (string file in filesList) { var sort = new FileSort { FileName = file }; baseFileName = file.Substring(0, file.IndexOf(partToken)); var fileIndex = file.Substring(file.IndexOf(partToken) + partToken.Length); int.TryParse(fileIndex, out var number); if (number <= 0) { continue; } sort.PartNumber = number; mergeFiles.Add(sort); } // 按照分片排序 var mergeOrders = mergeFiles.OrderBy(s => s.PartNumber).ToList(); // 合并文件 using var fileStream = new FileStream(baseFileName, FileMode.Create); foreach (var fileSort in mergeOrders) { using FileStream fileChunk = new FileStream(fileSort.FileName, FileMode.Open); await fileChunk.CopyToAsync(fileStream); } //删除分片文件 DeleteFile(mergeFiles); } public void DeleteFile(List<FileSort> files) { foreach (var file in files) { System.IO.File.Delete(file.FileName); } }
总结