
集群中各个节点的状态随时都有可能发生变化。从实际的变化上来分类的话,节点的异常大致可以分为四种类型:
leader 不可用;
follower 不可用;
多个 candidate 或多个 leader;
新节点加入集群。
3.3.1. leader 不可用下面将说明当集群中的 leader 节点不可用时,raft 集群是如何应对的。
➢ 一般情况下,leader 节点定时发送 heartbeat 到 follower 节点。

➢ 由于某些异常导致 leader 不再发送 heartbeat ,或 follower 无法收到 heartbeat 。
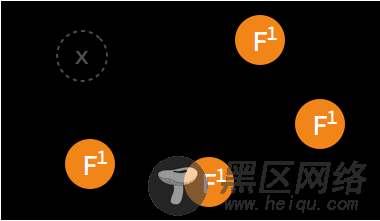
➢ 当某一 follower 发生 election timeout 时,其状态变更为 candidate,并向其他 follower 发起投票。
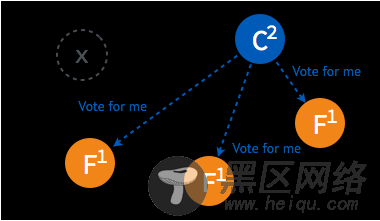
➢ 当超过半数的 follower 接受投票后,这一节点将成为新的 leader,leader 的步进数加1并开始向 follower 同步日志。
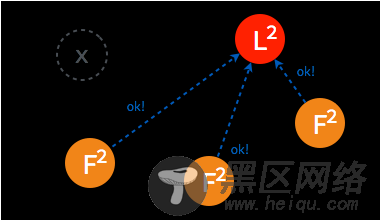
➢ 当一段时间之后,如果之前的 leader 再次加入集群,则两个 leader 比较彼此的步进数,步进数低的 leader 将切换自己的状态为 follower。

➢ 较早前 leader 中不一致的日志将被清除,并与现有 leader 中的日志保持一致。
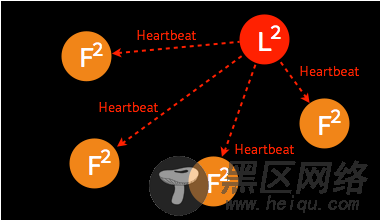
follower 节点不可用的情况相对容易解决。因为集群中的日志内容始终是从 leader 节点同步的,只要这一节点再次加入集群时重新从 leader 节点处复制日志即可。
➢ 集群中的某个 follower 节点发生异常,不再同步日志以及接收 heartbeat。
➢ 经过一段时间之后,原来的 follower 节点重新加入集群。

➢ 这一节点的日志将从当时的 leader 处同步。
在集群中出现多个 candidate 或多个 leader 通常是由于数据传输不畅造成的。出现多个 leader 的情况相对少见,但多个 candidate 比较容易出现在集群节点启动初期尚未选出 leader 的“混沌”时期。
➢ 初始状态下集群中的所有节点都处于 follower 状态。
➢ 两个节点同时成为 candidate 发起选举。
➢ 两个 candidate 都只得到了少部分 follower 的接受投票。

➢ candidate 继续向其他的 follower 询问。
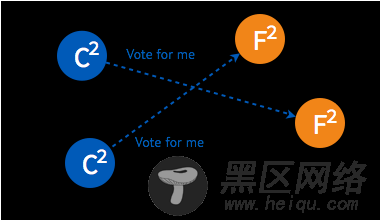
➢ 由于一些 follower 已经投过票了,所以均返回拒绝接受。
➢ candidate 也可能向一个 candidate 询问投票。
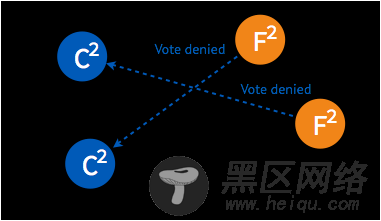
➢ 在步进数相同的情况下,candidate 将拒绝接受另一个 candidate 的请求。

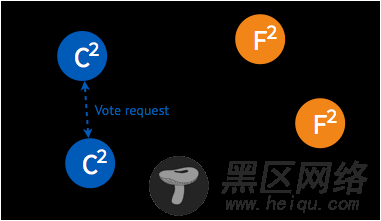
➢ 由于第一次未选出 leader,candidate 将随机选择一个等待间隔(150ms ~ 300ms)再次发起投票。
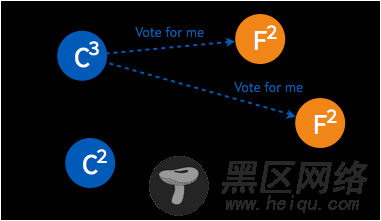
➢ 如果得到集群中半数以上的 follower 的接受,这一 candidate 将成为 leader。
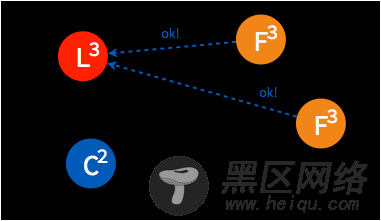
➢ 稍后另一个 candidate 也将再次发起投票。

➢ 由于集群中已经选出 leader,candidate 将收到拒绝接受的投票。
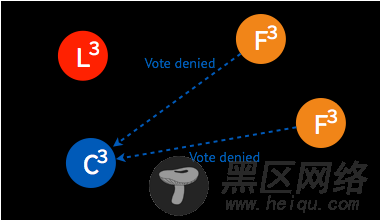
➢ 在被多数节点拒绝之后,并已知集群中已存在 leader 后,这一 candidate 节点将终止投票请求、切换为 follower,从 leader 节点同步日志。
