
3.4. 日志 3.4.1. 复制
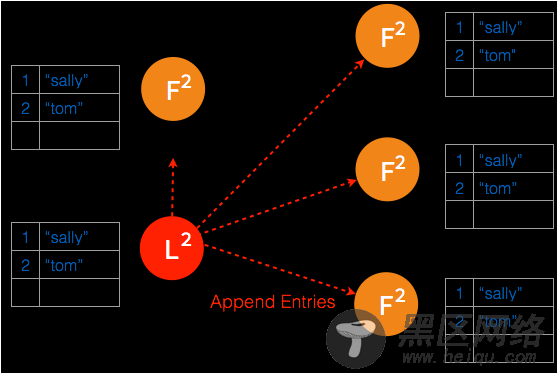
在 raft 集群中,所有日志都必须首先提交至 leader 节点。leader 在每个 heartbeat 向 follower 同步日志,follower 在收到日志之后向 leader 反馈结果,leader 在确认日志内容正确之后将此条目提交并存储于本地磁盘。

➢ 首先有一条 uncommitted 的日志条目提交至 leader 节点。
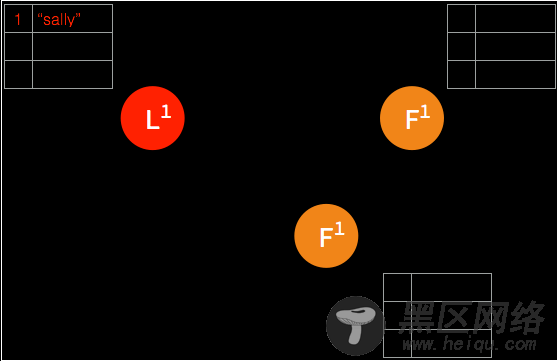
➢ 在下一个 heartbeat,leader 将此条目复制给所有的 follower。
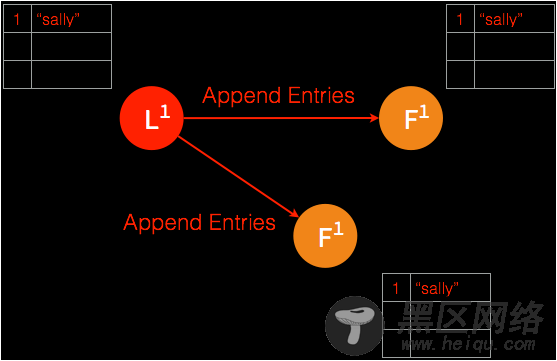
➢ 当大多数节点记录此条目之后,leader 节点认定此条目有效,将此条目设定为已提交并存储于本地磁盘。
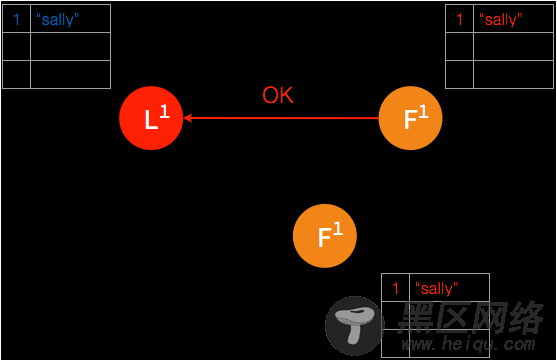

➢ 在下一个 heartbeat,leader 通知所有 follower 提交这一日志条目并存储于各自的磁盘内。
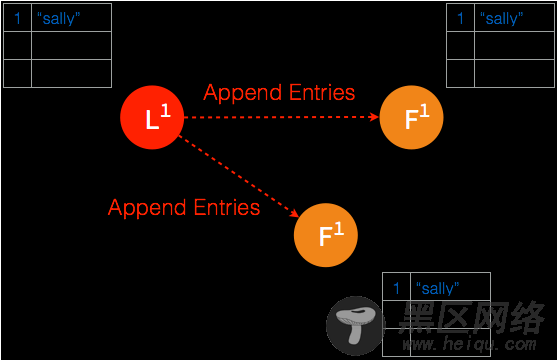
如果由于网络的隔断,造成集群中多数的节点在一段时间内无法访问到 leader 节点。按照 raft 共识算法,没有 leader 的那一组集群将会通过选举投票出新的 leader,甚至会在两个集群内产生不一致的日志条目。在集群重新完整连通之后,原来的 leader 仍会按照 raft 共识算法从步进数更高的 leader 同步日志并将自己切换为 follower。
➢ 集群的理想状态。
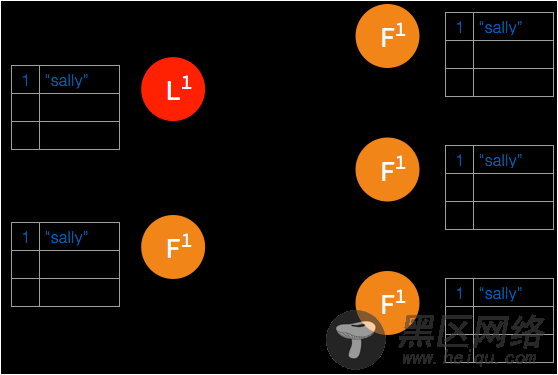
➢ 网络间隔造成大多数的节点无法访问 leader 节点。

➢ 新的日志条目添加到 leader 中。
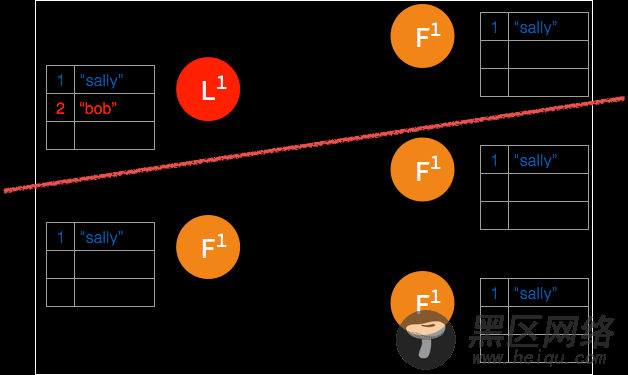
➢ leader 节点将此条日志同步至能够访问到 leader 的节点。
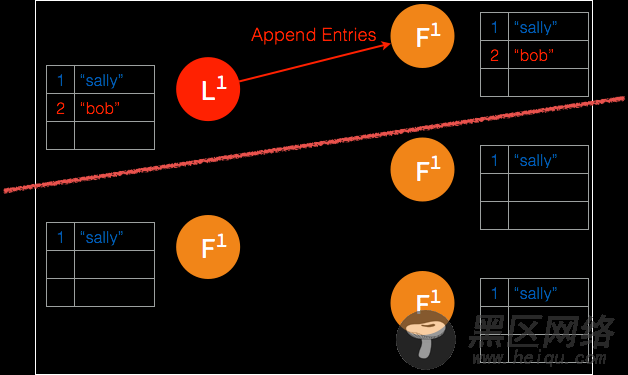
➢ follower 确认日志被记录,但是确认记录日志的 follower 数量没有超过集群节点的半数,leader 节点并不将此条日志存档。

➢ 在被隔断的这部分节点,在 election timeout 之后,followers 中产生 candidate 并发起选举。
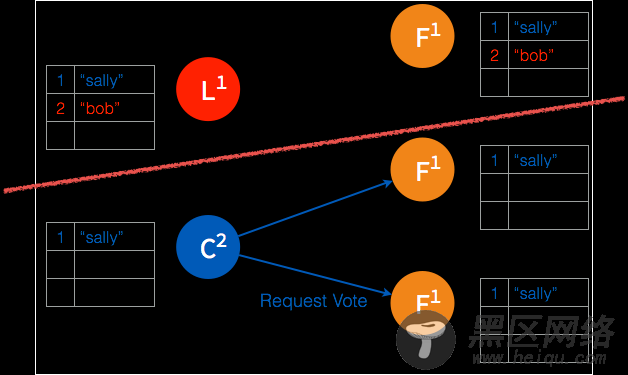
➢ 多数节点接受投票之后,candidate 成为 leader。
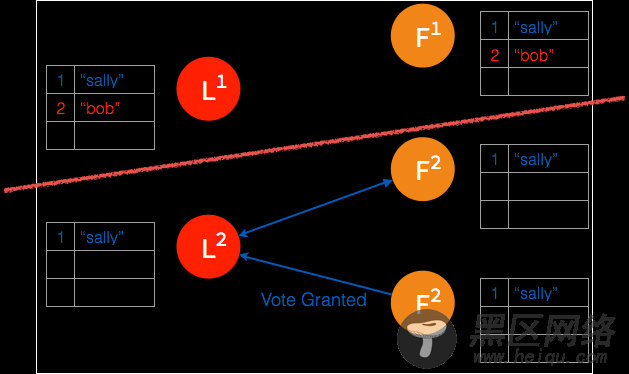
➢ 一个日志条目被添加到新的 leader。

➢ 日志被复制给新 leader 的 follower。
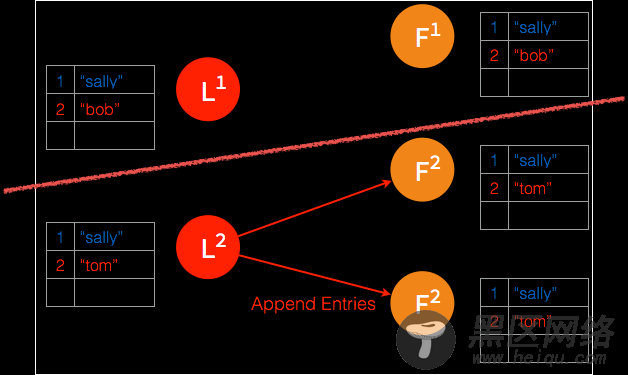
➢ 多数节点确认之后,leader 将日志条目提交并存储。
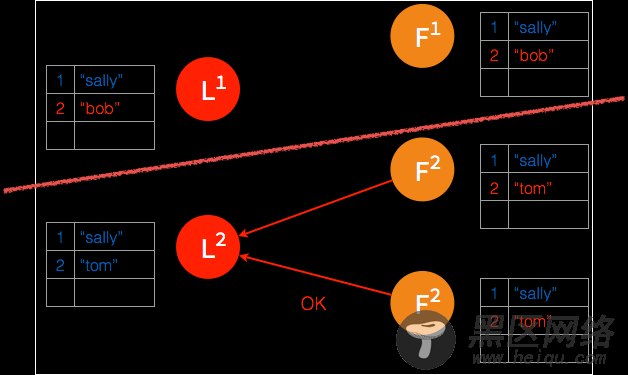
➢ 在下一个 heartbeat,leader 通知 follower 各自提交并保存在本地磁盘。

➢ 经过一段时间之后,集群重新连通到一起,集群中出现两个 leader 并且存在不一致的日志条目。
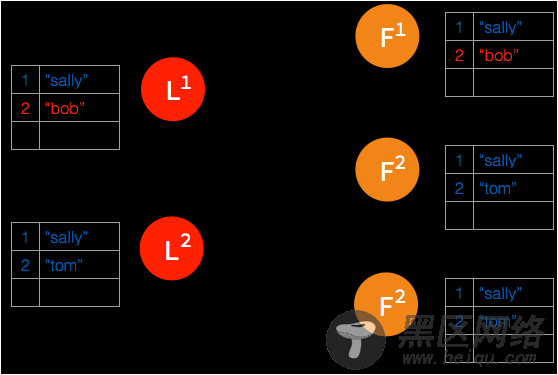
➢ 新的 leader 在下一次 heartbeat timeout 时向所有的节点发送一次 heartbeat。

➢ #1 leader 在收到步进数更高的 #2 leader heartbeat 时放弃 leader 地位并切换到 follower 状态。

➢ 节点中所有未存档的日志条目都将被丢弃。

➢ 未被复制的日志条目将会被同步给所有的 follower。
通过这种方式,只要集群中有效连接的节点超过总数的一半,集群将一直以这种规则运行下去并始终确保各个节点中的数据始终一致。