提到大数据存储nosql是不得不提的一个部分CAP,BASE,ACID这些原理在过去的一些年对其有着一定的指导作用(近年来随着各种实时计算模型的发展,CAP也被渐渐打破)
CAP:(Consistency-Availability-Partition Tolerance
数据一致性(C):等同于所有节点访问同一份最新的数据副本;
对数据更新具备高可用性(A):在可写的时候可读, 可读的时候可写,最少的停工时间
能容忍网络分区(P)
eg:
传统数据库一般采用CA即强一致性和高可用性
nosql,云存储等一般采用降低一致性的代价来获得另外2个因素
ACID:按照CAP分法ACID是许多CA型关系数据库多采用的原则:
A:Atomicity原子性,事务作为最小单位,要么不执行要么完全执行
C:Consistency一致性,一个事务把一个对象从一个合法状态转到另一个合法状态,如果交易失败,把对象恢复到前一个合法状态。即在事务开始之前和事务结束以后,数据库的完整性约束没有被破坏
I:Isolation独立性(隔离性),事务的执行是互不干扰的,一个事务不可能看到其他事务运行时,中间某一时刻的数据。
D:Durability:事务完成以后,该事务所对数据库所作的更改便持久的保存在数据库之中,并不会被回滚
BASE:一般是通过牺牲强一致性,来换取可用性和分布式
BA:Basically Aavilable基本可用:允许偶尔的失败,只要保证绝大多数情况下系统可用
S:Soft State软状态:无连接?无状态?
E:Eventual Consistency最终一致性:要求数据在一定的时间内达到一致性
以云存储为例:目前的云存储多以整体上采用BASE局部采用ACID,由于使用分布式使用多备份所以多采用最终一致性
Nosql常见的数据模型有key/value和Schema Free(自由列表模式)两种,
key/value,每条记录由2个域组成,一个作为主键,一个存储记录的数据(mongodb)
Schema Free, 每条记录有一个主键,若干条列组成,有点类似关系型数据库(hbase)
在实现这些模型的时候基本使用2种实现方式:哈希加链表,或者B+树的方式
哈希加链表:通过将key进行哈希来确定存储位置,相同哈希值的数据存储成链表
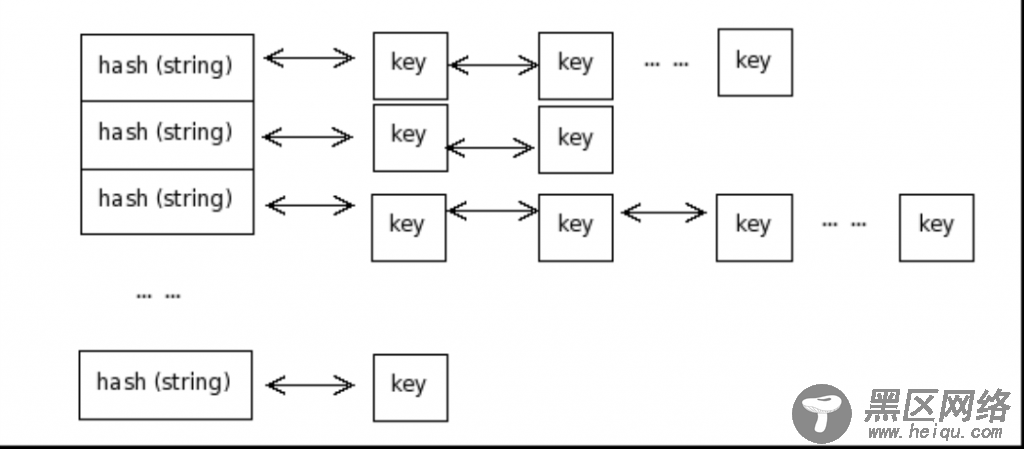
基本的hash寻址算法有除法散列法,平方散列法,斐波那契(Fibonacci)散列法等,但是java是这样做的
static int indexFor(int h, int length) {
return h & (length-1);
}
java会用key的hashcode值与数组的槽数-1进行与运算
这里会有一个问题只有当数组的槽数为2的n次方-1,其二进制全是1的(如2的2次方-1=11)的时候哈希值产生碰撞的概率是最小的
所以在java中hashmap的数组的初始大小是16(2的4次方)
hashmap的问题
hashmap的resize:
当不断put数据使数据慢慢变大的时候,刚开始的数组已经不能满足需求了,我们需要扩大数组的槽数
hashmap中有loadFactor属性,该属性默认为0.75,即元素个数达到数组的百分之七十五的时候,数组槽数会进行翻倍,并且之前已存入的数据会重新进行计算。
so:如果我们可以预估我们会在hashmap中存放1000个数据,那么我们就要确保数组的槽数乘上0.75大于1000,我们得到1366,如果我们这样写new HashMap(1366),java会自动帮我们转换成new HashMap(2048)(2的n次方)
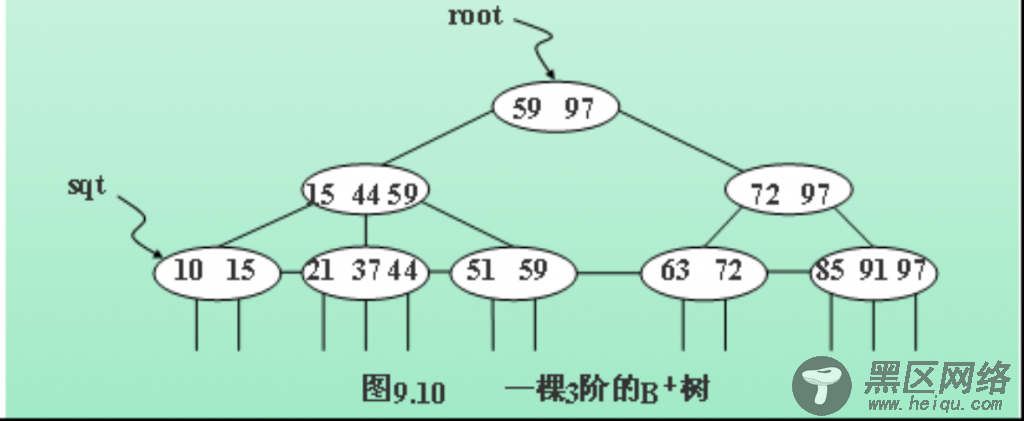
B+树:B+树的特点
1.节点中关键字数量与字节点数相同。
2.所有叶子结点中包含全部指向记录的指针
3.叶子结点按照自小而大顺序链接
5通常在B+树上有两个头指针,一个指向根结点,一个指向关键字最小的叶子结点
(爬虫会有深度优先,广度优先的算法)
来自百度的图
so:hash查找单条非常快
b+树,范围查找很快(深度优先,广度优先的遍历等)