存储非结构化数据
-eg:评论,问答
再看下数据
结构化
半结构化(我们的数据)
非结构化
海量(百T级别)
数据偶尔丢掉几条没关系
数据质量差
到目前为止我们的处理方案是:
离线分析(对实时性要求不高-Hadoop)-结构化,半结构化,非结构化
实时分析(对实时性要求极高-storm)-结构化,半结构化,非结构化
实时查找(经常性对大量数据进行count等操作-infobright,hbase)-结构化,部分支持半结构化
有时我们需要对非结构化的数据做一些实时搜索的功能keyvalue搞不定怎么办--实时搜索(巧妙设计数据结构)
我们的做法是:
倒排索引
+关键字的前缀冗余
具体关键字的前缀冗余使用redis的zset完成,其本质也是一个hashtable+跳表的所以结构
这样存的时候需要切词,存储,key和关键字映射的存储,前缀和关键字映射的存储
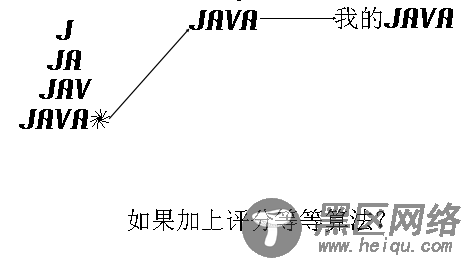
但是读的时候是非常迅速的,如下图当用户输入J 就可以很快的找到关于java等的信息(当然还需要一些评分,权重算法)
服务架构需要考虑的问题:
CPU负载和I/O负载(计算密集型和io密集型)
CPU负载-计算密集型
所谓CPU负载就是通常的web服务等,这些服务基本上只消耗cpu,所以只要增加安装相同服务的服务器,然后就可已通过负载均衡器工作了
I/O负载-io密集型
1.数据的切割和在机器间的分配策略(原则是尽量移动计算而不是移动数据)
2.如何通过多备份来确保数据的可用性(确保多备份的一致性)
3.如何使集群针对性强的响应客户端的读写请求
4.如何实现集群中单台机器的热拔插
5.好的负载均衡策略
6.网络通信延迟,因为计算机运行的速度是微秒甚至纳秒,所以毫秒级别的延迟对程序来说性能损害是极大的
ps:我们平常使用的路由器一般pps(每秒转发数为几十万左右),所以一般的千兆以太网的极限就在几十万/秒
除此之外由于正常的路由器的ARP表上限为900左右
两个原因导致一个子网中机器不能过多,当集群中机器过多时就需要进行网络的层次话
虚拟化优点
1,扩展性-可以动态的迁移和复制,使得服务器增加变得更简单
2,提高资源利用率
3,降低运维成本(远程管理,环境更单一
异常行为局部化,使得主机控制更简单)
4,提高可用性(抽象硬件差异)
5, 调整负载(软件层面对负载进行控制,当监测到负载消耗异常可重启进程或者虚拟机)
缺点
1,虚拟机本身的损耗(cpu,内存)
2,网络性能损耗近一半
3,I/O性能略微降低0.5%左右