
HDFS中的文件在物理上是分块存储(block),块的大小可以通过配置参数(dfs.blocksize)来规定,默认大小在hadoop2.x版本中是128M,老版本中是64M
HDFS的块比磁盘的块大,其目的是为了最小化寻址开销。如果块设置得足够大,从磁盘传输数据的时间会明显大于定位这个块开始位置所需的时间。因而,传输一个由多个块组成的文件的时间取决于磁盘传输速率。
如果寻址时间约为10ms,而传输速率为100MB/s,为了使寻址时间仅占传输时间的1%,我们要将块大小设置约为100MB。默认的块大小128MB。
块的大小:10ms*100*100M/s = 100M
4.2. HDFS写数据流程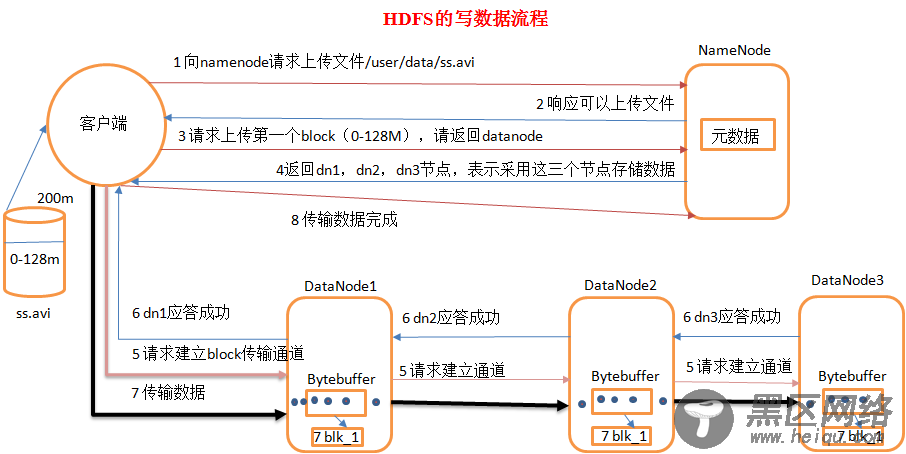
1)客户端向namenode请求上传文件,namenode检查目标文件是否已存在,父目录是否存在。
2)namenode返回是否可以上传。
3)客户端请求第一个 block上传到哪几个datanode服务器上。
4)namenode返回3个datanode节点,分别为dn1、dn2、dn3。
5)客户端请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成
6)dn1、dn2、dn3逐级应答客户端
7)客户端开始往dn1上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,dn1收到一个packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答
8)当一个block传输完成之后,客户端再次请求namenode上传第二个block的服务器。(重复执行3-7步)
4.3. HDFS读数据流程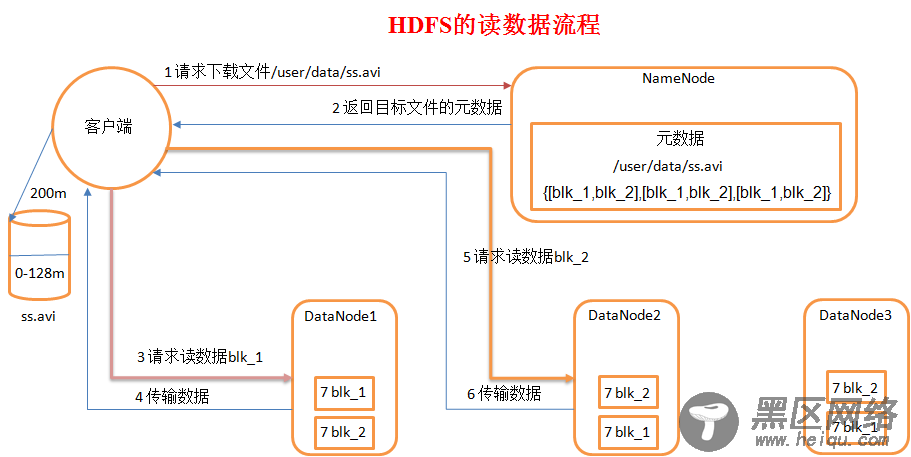
1)客户端向namenode请求下载文件,namenode通过查询元数据,找到文件块所在的datanode地址。
2)挑选一台datanode(就近原则,然后随机)服务器,请求读取数据。
3)datanode开始传输数据给客户端(从磁盘里面读取数据放入流,以packet为单位来做校验)。
4)客户端以packet为单位接收,先在本地缓存,然后写入目标文件。
5.HDFS命令1)基本语法
bin/hadoop fs 具体命令
2)常用命令实操
(1)-help:输出这个命令参数
bin/hdfs dfs -help rm
(2)-ls: 显示目录信息
hadoop fs -ls /
(3)-mkdir:在hdfs上创建目录
hadoop fs -mkdir -p /aaa/bbb/cc/dd
(4)-moveFromLocal从本地剪切粘贴到hdfs
hadoop fs - moveFromLocal /home/hadoop/a.txt /aaa/bbb/cc/dd
(5)-moveToLocal:从hdfs剪切粘贴到本地(尚未实现)
hadoop fs -help moveToLocal
-moveToLocal <src> <localdst> :
Not implemented yet
(6)--appendToFile :追加一个文件到已经存在的文件末尾
hadoop fs -appendToFile ./hello.txt /hello.txt
(7)-cat :显示文件内容
(8)-tail:显示一个文件的末尾
hadoop fs -tail /weblog/access_log.1
(9)-chgrp 、-chmod、-chown:linux文件系统中的用法一样,修改文件所属权限
hadoop fs -chmod 666 /hello.txt
hadoop fs -chown someuser:somegrp /hello.txt
(10)-copyFromLocal:从本地文件系统中拷贝文件到hdfs路径去
hadoop fs -copyFromLocal ./jdk.tar.gz /aaa/
(11)-copyToLocal:从hdfs拷贝到本���
hadoop fs -copyToLocal /user/hello.txt ./hello.txt
(12)-cp :从hdfs的一个路径拷贝到hdfs的另一个路径
hadoop fs -cp /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2
(13)-mv:在hdfs目录中移动文件
hadoop fs -mv /aaa/jdk.tar.gz /
(14)-get:等同于copyToLocal,就是从hdfs下载文件到本地
hadoop fs -get /user/hello.txt ./
(15)-getmerge :合并下载多个文件,比如hdfs的目录 /aaa/下有多个文件:log.1, log.2,log.3,...
hadoop fs -getmerge /aaa/log.* ./log.sum
(16)-put:等同于copyFromLocal
hadoop fs -put /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2
(17)-rm:删除文件或文件夹
hadoop fs -rm -r /aaa/bbb/
(18)-rmdir:删除空目录
hadoop fs -rmdir /aaa/bbb/ccc
(19)-df :统计文件系统的可用空间信息
hadoop fs -df -h /
(20)-du统计文件夹的大小信息
hadoop fs -du -s -h /user/data/wcinput
188.5 M /user/data/wcinput
hadoop fs -du -h /user/data/wcinput
188.5 M /user/data/wcinput/hadoop-2.7.2.tar.gz
97 /user/data/wcinput/wc.input
(21)-count:统计一个指定目录下的文件节点数量
hadoop fs -count /aaa/
hadoop fs -count /user/data/wcinput
1 2 197657784 /user/data/wcinput
嵌套文件层级; 包含文件的总数
(22)-setrep:设置hdfs中文件的副本数量
hadoop fs -setrep 3 /aaa/jdk.tar.gz