
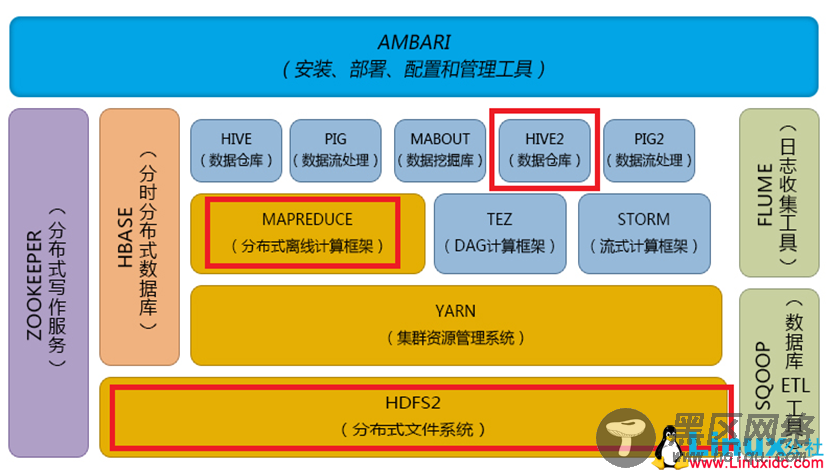
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用来开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。
Hadoop框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,MapReduce则为海量的数据提供了计算。
Hadoop体系结构:
hive:
一、什么是hive
Hive是部署在hadoop集群上的数据仓库工具。
数据库和数据仓库的区别:
数据库(如常用关系型数据库)可以支持实时增删改查。
数据仓库不仅仅是为了存放数据,它可以存放海量数据,而且可以查询、分析和计算存储在Hadoop 中的大规模数据。但他有一个弱点,他不能进行实时的更新、删除等操作。也就是一次写入多次读取。
Hive 也定义了简单的类 SQL 查询语言,称为 QL ,它允许熟悉 SQL 的用户查询数据。现在hive2.0也支持更新、索引和事务,几乎SQL的其它特征都能支持。
Hive支持SQL92大部分功能,我们暂时可以把 hive理解成一个关系型数据库,语法和MySQL是几乎是一样的。
Hive是Hadoop 上的数据仓库基础构架之一,是SQL解析引擎,它可以将SQL转换成MapReduce任务,然后在Hadoop执行。
二、hive的部署与安装
Hive只在一个节点上安装即可
1.上传tar包
apache-hive-1.2.1-bin.tar.gz
2.解压
tar -zxvf hive-0.9.0.tar.gz -C /cloud/
3.配置mysql metastore 元数据库(切换到root用户)
配置HIVE_HOME环境变量
rpm -qa | grep mysql
rpm -e mysql-libs-5.1.66-2.el6_3.i686 --nodeps
rpm -ivh MySQL-server-5.1.73-1.glibc23.i386.rpm
rpm -ivh MySQL-client-5.1.73-1.glibc23.i386.rpm
修改mysql的密码
/usr/bin/mysql_secure_installation
(注意:删除匿名用户,允许用户远程连接)
登陆mysql
mysql -u root -p
4.配置hive
cp hive-default.xml.template hive-site.xml
修改hive-site.xml(删除所有内容,只留一个<property></property>)
添加如下内容:
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://xcloud36:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123</value>
<description>password to use against metastore database</description>
</property>
5.安装hive和mysq完成后,将mysql的连接jar包拷贝到$HIVE_HOME/lib目录下
如果出现没有权限的问题,在mysql授权(在安装mysql的机器上执行)
mysql -uroot -p
#(执行下面的语句 *.*:所有库下的所有表 %:任何IP地址或主机都可以连接)
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '123' WITH GRANT OPTION;
FLUSH PRIVILEGES;
6.启动hive
进入hive的安装的home目录下的bin目录
[Neo@iZ25at60yr9Z bin]$ pwd
/home/Neo/apache-hive-1.2.1-bin/bin
执行hive脚本
[Neo@iZ25at60yr9Z bin]$ ./hive
Cannot find hadoop installation: $HADOOP_HOME or $HADOOP_PREFIX must be set or hadoop must be in the path
三、Hive的系统架构
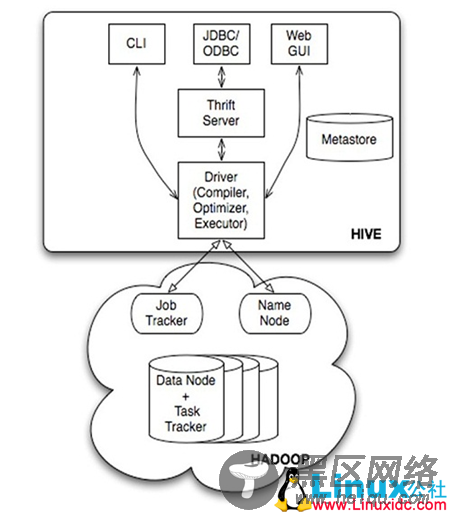
• 用户接口,包括 CLI(Shell命令行),JDBC/ODBC,WebUI
• MetaStore元数据库,通常是存储在关系数据库如 mysql, derby 中
• Driver 包含解释器、编译器、优化器、执行器
• Hadoop:用 HDFS 进行存储,利用 MapReduce 进行计算
Hive的表和数据库,对应的其实是HDFS( Hadoop分布式文件系统)的目录/文件,按表名把文件夹分开。如果是分区表,则分区值是子文件夹,可以直接在MapReduce Job里使用这些数据。
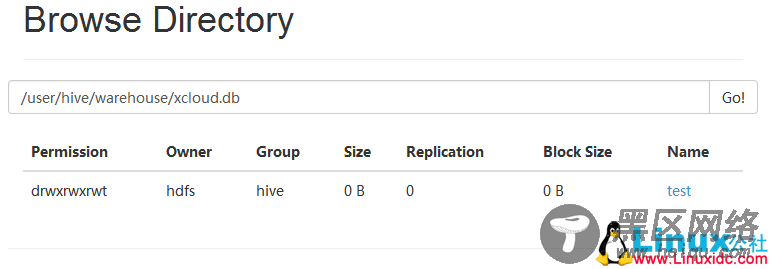
四、hive的元数据库以及数据存储方式