
一、何为索引?
1、索引是帮助数据库高效获取数据的排好序的数据结构。
2、索引存储在文件中。
3、索引建多了会影响增删改效率。
(下面这张图为计算机组成原理内容,每查询一次索引节点,都会进行一次磁盘IO读取,即要寻道和旋转)
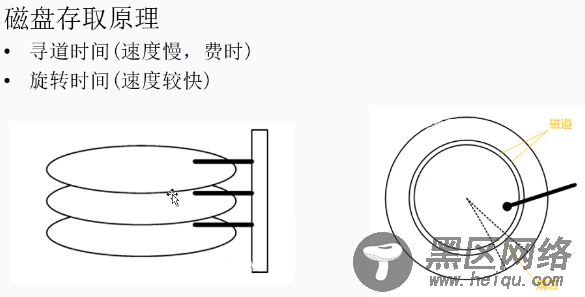
二、MySQL索引结构为什么是B+树?
MySQL 建索引可使用的数据结构有B+树和Hash两种,但是Hash用得很少, 优点是可以快速定位到某一行,缺点是不能解决范围查询问题。
对于如果不需要使用范围查询、只需要精准查询的场景,可以使用Hash索引方法,比如查电话号码。
再说说主流的索引方法B+树,先说下为什么不用别的树结构,再说为什么用B+树。
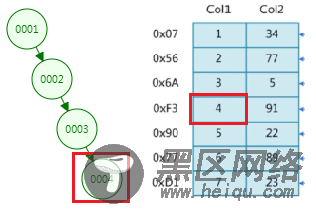
1、为什么不用二叉树?
如果碰到下面这种单边增长的极端情况,查找节点4和顺序查找没区别。(这种特殊情况的二叉树等同于链表,时间复杂度为O(n))
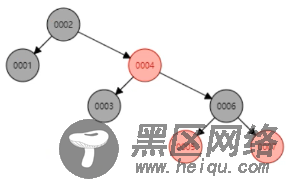
2、为什么不用红黑树?
红黑树是一颗平衡二叉树,数据量大的时候,树的深度也很深,如果树的深度有20层,而查找的数据在叶子节点,就要进行20次IO操作,性能低。
3、为什么不用B树?
B树的特点:
叶子节点具有相同的深度
叶子节点的指针为空
叶子节点中的数据key从左到右递增排列
其实B树就是在横向做了文章,一个节点可以存储更多数据(大节点包含很多小节点),这样相对来说,深度就会变浅。
提问:横向的节点怎么查,比如说查找上图中的节点77?
从磁盘中把大节点查找出来,把这个大节点加载进内存中,节点77实际上是在内存中查找的,在内存中做的是随机访问,速度很快,跟磁盘的寻道和旋转相比的话,基本可以忽略不计。
提问:为什么不可以让B树横向的度无限增大,这样不就深度为1,查找不就更快了?(度的含义:节点的数据存储个数)
本来是想通过一次IO操作把一个大节点加载进内存,如果一个大节点的数据量太大的话, 则内存和硬盘一次交互没办法交换那么多数据,假设一次只能交换1页(4k)的数据(有上限,也有可能是几十页,和计算机硬件有关),意味着CPU去硬盘上做一次IO操作只能取1页的数据,那么当一个大节点的数据量太大时,仍要进行多次IO操作。因此,度是有上限的,MySQL会根据计算机硬件自动进行度的优化,一个大节点通常为1页空间。
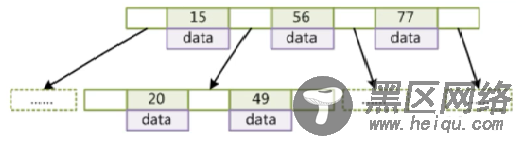
4、为什么使用B+树?(B+树是B树的变种,索引做了冗余,存了多份,但是没关系,索引只占很小空间,比如下图中的15节点)
B+树的特点:
非叶子节点不存储data,只存储key,可以增大度(相比B树,B+树的深度更浅)
叶子节点不存储指针
顺序访问指针,提高区间访问的性能(实际上是双向指针)
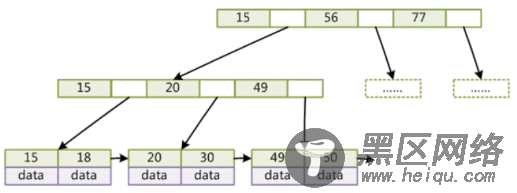
提问:为什么说B+树可以增大度?
因为非叶子节点只存储索引一个值,不存储data(B树会存储data),而大节点大小是确定的,因此节点就可以存储更多的数据,即度可以变得更大。这样既保证度可以达到最大,又保证一个大节点通过一次IO操作可以加载进内存。(非叶子节点度更大,深度更浅,只有非叶子节点才影响查找次数,叶子节点是最后一次查找,对总的查找次数是没有影响的,因此把data全部移到了叶子节点)
提问:为什么叶子节点之间还需要用指针?(一个大节点的尾节点和下一个大节点的头节点之间的指针连接)
方便范围查询。比如查找上图中key>18,如果没有指针会非常麻烦,必须从头开始查找,如果有指针,则可以直接遍历key>18的叶子节点(链表)。
B+树索引的性能分析:
一般使用磁盘I/O次数评价索引结构的优劣
预读:磁盘一般会顺序向后读取一定长度的数据(页的整数倍)放入内存
局部性原理:当一个数据被用到时,其附近的数据也通常会立马被使用