
B+树的大节点大小设为等于一个页,每次新建大节点直接申请一个页的空间,这能保证一个大节点物理上也存储在一个页里,大节点载入只需一次IO操作
B+树的度d一般会超过100,因此高度h非常小(一般为3~5之间)
三、MySQL底层是怎么用B+树来存储数据的?
MySQL有两种常见的存储引擎:InnoDB(默认)、MyISAM(用得少,在MySQL8.0中被废弃掉了),存储引擎范围是表级别的。
1、MyISAM索引实现(非聚集)
索引文件和数据文件是分离的
索引结构的叶子节点value存储的是文件指针。
.frm是表结构文件,.MYD是数据文件(MyISAM Data),.MYI是索引文件(MyISAM Index)。
MyISAM主键索引查找流程:先通过.MYI文件找到对应索引的文件指针,再根据文件指针去.MYD文件中定位对应的那行数据。
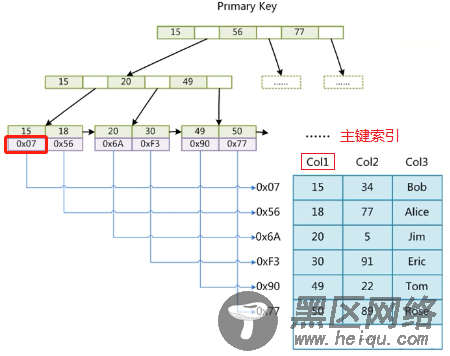
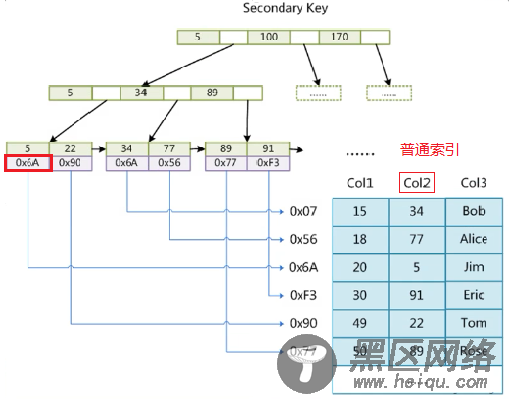
MyISAM普通索引查找流程:和主键索引查找流程一致。
2、InnoDB索引实现(聚集)
数据文件本身就是索引文件
表数据文件本身就是按B+树组织的一个索引结构文件
聚集索引的叶子节点包含了完整的数据记录
表必须有主键,且推荐使用整型的自增主键
普通索引结构叶子节点存储的是主键值
.frm是表结构文件,.ibd是数据和索引文件(InnoDB Data)
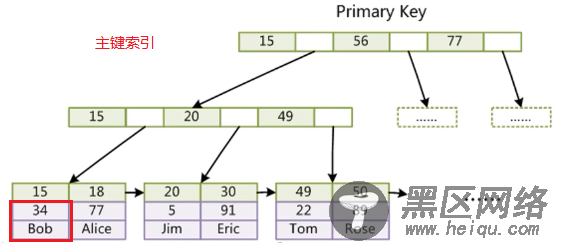
InnoDB主键索引查找流程:通过.ibd文件找到对应的索引,索引的value即为那行对应的完整数据。
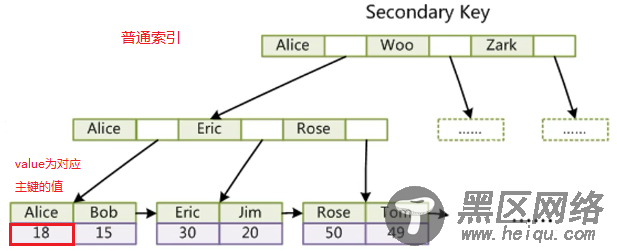
InnoDB普通索引查找流程:通过.ibd文件找到对应的索引,索引的value即为那行对应的主键的值,再根据主键值去主键索引树中找到对应的行数据。
提问:聚集索引和非聚集索引的区别?
聚集索引:表中那行数据的索引和数据都合并在一起了。
非聚集索引:表中那行数据的索引和数据是分开存储的。
提问:为什么InnoDB表必须有主键?
因为整个数据文件本身就是按照B+树组织的一个索引文件,所以必须要有主键(建InnoDB表时不指定主键,默认会从表字段中选一列作为唯一主键,如果不存在这种字段,则后台默认生成一个长整型主键字段,MyISAM可以没有)。
提问:为什么推荐使用整型的自增主键?
提高查询性能。如果是使用UUID作为主键,第一,UUID长度很长,会浪费存储空间,第二,UUID是字符串类型,比较大小要查找ASCII码表,查找速度没有整型int查找速度快,第三,UUID是随机生成无序的字符串,当数据插入时,有很大可能会导致节点位置移动,还可能造成很多其他节点位置移动,简单来说就是位置打乱了; 如果使用整型的自增主键,新插入的数据都会连续的插入到磁盘的物理空间。
提问:为什么InnoDB普通索引结构叶子节点存储的是主键值?(一致性和节省存储空间)
如果普通索引的value也存数据,那么当往有主键索引和普通索引的表中插入数据时,索引结构中key对应的value要存储两份数据,增加维护成本。
单值索引:只有一个索引,如(id),size=1
联合索引:多个索引合起来作为一个联合索引,如(id,name),size>1(单值索引是联合索引size=1的特例)
提问:联合索引的底层数据结构长什么样?
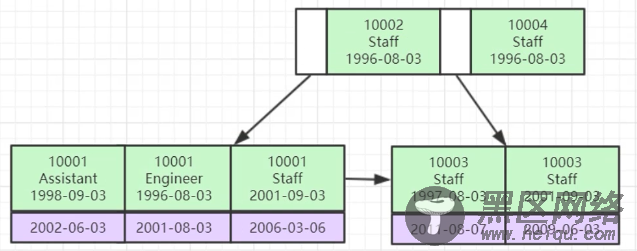
先比较id,如果id相等,再比较name,如果name也相等,则再比较date。(索引最左前缀原理,后面索引优化随笔会讲解)
Linux公社的RSS地址:https://www.linuxidc.com/rssFeed.aspx