
《OpenGL编程指南(原书第8版)》针对OpenGL4.3版本的各种特性进行了全新阐述,并全面介绍了OpenGL和OpenGL着色语言,第一次将着色器的技术与函数功能为中心的经典技术介绍相结合,呈现最新的OpenGL编程技术。
概述由于图形处理器每秒能够进行数以亿计次的计算,它已成为一种性能十分惊人的器件。过去,这种处理器主要被设计用于承担实时图形渲染中海量的数学运算。然而,其潜在的计算能力也可用于处理与图形无关的任务,特别是当无法很好地与固定功能的图形管线结合的时候。为了使得这种应用成为可能,OpenG引入一种特殊的着色器:计算着色器。计算着色器可以认为是一个只有一级的管线,没有固定的输入和输出,所有默认的输入通过一组内置变量来传递。当需要额外的输入时,可以通过那些固定的输入输出来控制对纹理和缓冲的访问。所有可见的副作用是图像存储,原子操作,以及对原子计数器的访问。然而加上通用的显存读写操作,这些看上去似乎有限的功能使计算着色器获得一定程度的灵活性,同时摆脱图形相关的束缚,以及打开广阔的应用空间。
OpenGL中的计算着色器和其他着色器很相似。它通过glCreateShader() 函数创建,用glCompilerShader()进行编译,通过glAttachShader()对程序进行绑定,最后按通用的做法用glLinkProgram()对这些程序进行链接。计算着色器使用GLSL编写,原则上,所有其他图形着色器(比如顶点着色器,几何着色器或者片元着色器)能够使用的功能它都可以使用。当然,这不包括诸如几何着色器中的EmitVertex()或者EndPrimitive()等功能,以及其他类似的与图形管线特有的内建变量。另一方面,计算着色器也包含一些独有的内置变量和函数,这些变量和函数在OpenGL管线的其他地方无法访问。
工作组及其执行正如图形着色器被置于管线的不同阶段用来操作与图形相关的单元一样,将计算着色器被有效地放入一个一级的计算管线中,然后处理与计算相关的单元。按照这种类比,顶点着色器作用于每个顶点,几何着色器作用于每个图元,而片元着色器则作用于每个片元。图形硬件主要通过并行来获得性能,这种并行则通过大量的顶点、图元和片元流过相应的管线阶段而得以实现。而在计算着色器中,这种并行性则显得更为直接,任务以组为单位进行执行,我们称为工作组(work group)。拥有邻居的工作组被称为本地工作组(local workgroup), 这些组可以组成更大的组,称为全局工作组(global workgroup),而其通常作为执行命令的一个单位。
计算着色器会被全局工作组中每一个本地工作组中的每一个单元调用一次,工作组的每一个单元称为工作项(work item),每一次调用称为一次执行。执行的单元之间可以通过变量和显存进行通信,且可执行同步操作保持一致性。图12-1 对这种工作方式进行了说明。在这个简化的例子中,全局工作组包含16个本地工作组, 而每个本地工作组又包含16个执行单元,排成4*4的网格。每个执行单元拥有一个2维向量表示的索引值。
尽管在图12-1中,全局和本地工作组都是2维的,而事实上它们是3维的,为了能够在逻辑上适应1维、2维的任务,只需要把额外的那2维或1维的大小设为0即可。计算着色器的每一个执行单元本质上是相互独立的,可以并行地在支持OpenGL的GPU硬件上执行。实际中,大部分OpenGL硬件都会把这些执行单元打包成较小的集合(lockstep),然后把这些小集合拼起来组成本地工作组。本地工作组的大小在计算着色器的源代码中用输入布局限定符来设置。全局工作组的大小则是本地工作组大小的整数倍。当计算着色器执行的时候,它可以内置变量来知道当前在本地工作组中的相对坐标、本地工作组的大小, 以及本地工作组在全局工作组中的相对坐标。基于这些还能进一步获得执行单元在全局工作组中的坐标等。着色器根据这些变量来决定应该负责计算任务中的哪些部分,同时也能知道一个工作组中的其他执行单元,以便于共享数据。
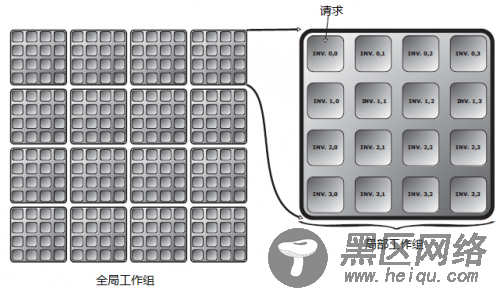
图12-1 计算工作量的图示
输入布局限定符在计算着色器中声明本地工作组的大小,分别使用local_size_x、local_size_y以及local_size_z,它们的默认值都是1。举例来说如果忽略local_size_z,就会创建N * M的2维组。比如在例子12.1中就声明了一个本地工作组大小为16 * 16的着色器。
例12.1简单的本地工作组声明
