
我们先来看一下为什么要做集群,如果我们要部署一个单节点Redis,很明显会遇到单点故障的问题。
首先能想到解决单点故障的方法,就是做主从,但是当有海量存储需求时,单一的主从结构就会出问题,说问题之前要先了解一下主从之间是如何复制的。
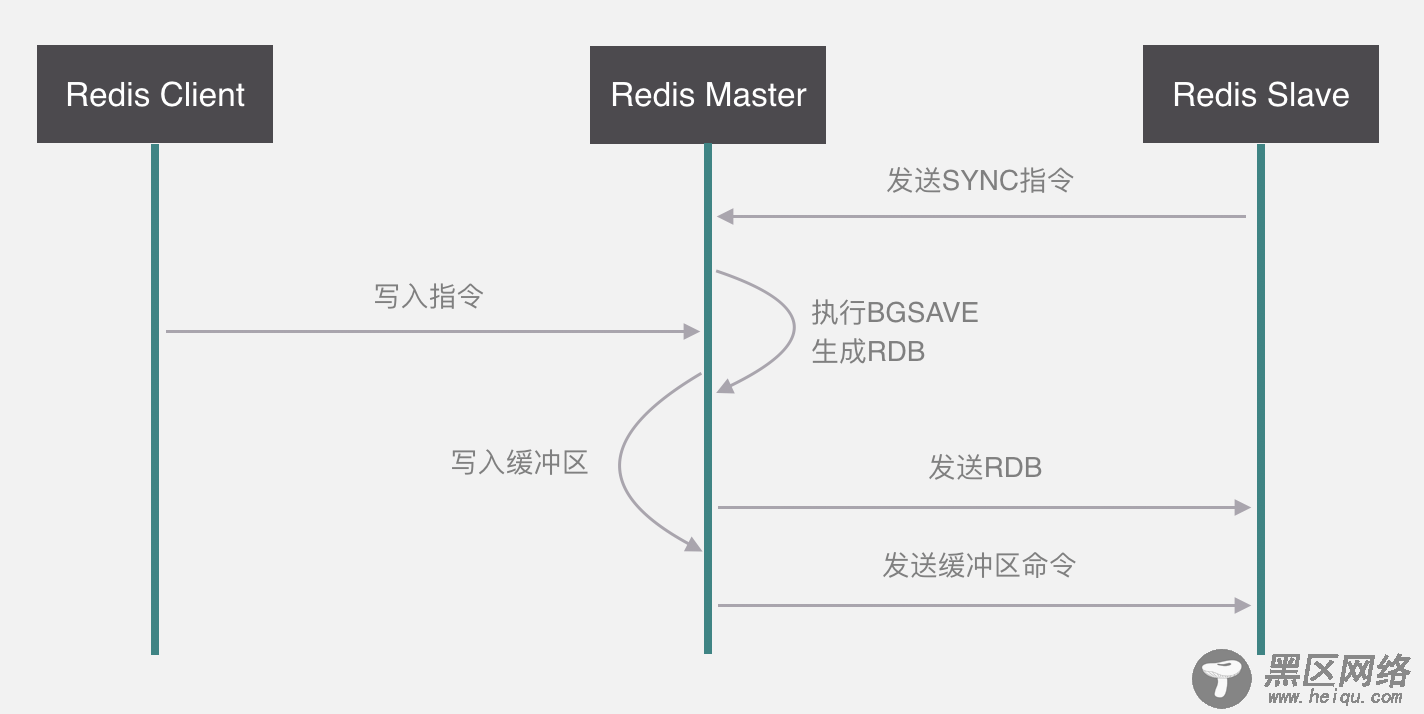
我们把Redis分为三个部分,分别是客户端、主节点以及从节点,如果从节点要同步主节点的数据,它首先会发Sync指令给主节点,主节点收到指令之后会执行BGSAVE命令生成RDB文件,这个RDB文件指的是快照文件,它是Redis两种备份方式的其中一种,另一种叫AOF,它的原理是将所有的写入指令存入文件,MySQL的binlog原理是一样的。
如果主节点在生成RDB的过程当中,客户端发来了写入指令,这个时候主节点会把指令全部写入缓冲区,等RDB生成完了,会把RDB文件发送给从节点,最后再把缓冲区的指令发送给从节点。这样就完成了整个的复制。
我们刚才说单纯地做主从是有缺陷的,这个缺陷就是如果我们要存储海量的数据,那么BGSAVE指令生成的RDB文件会非常巨大,这个文件传送给从节点也会非常慢,如果缓冲区命令很多的话,从节点同步数据时也会执行很久,所以,要解决单点问题和海量存储问题,还是要考虑做集群。
Redis集群方案目前主流的有三种,分别是Twemproxy、Codis和Redis Cluster。
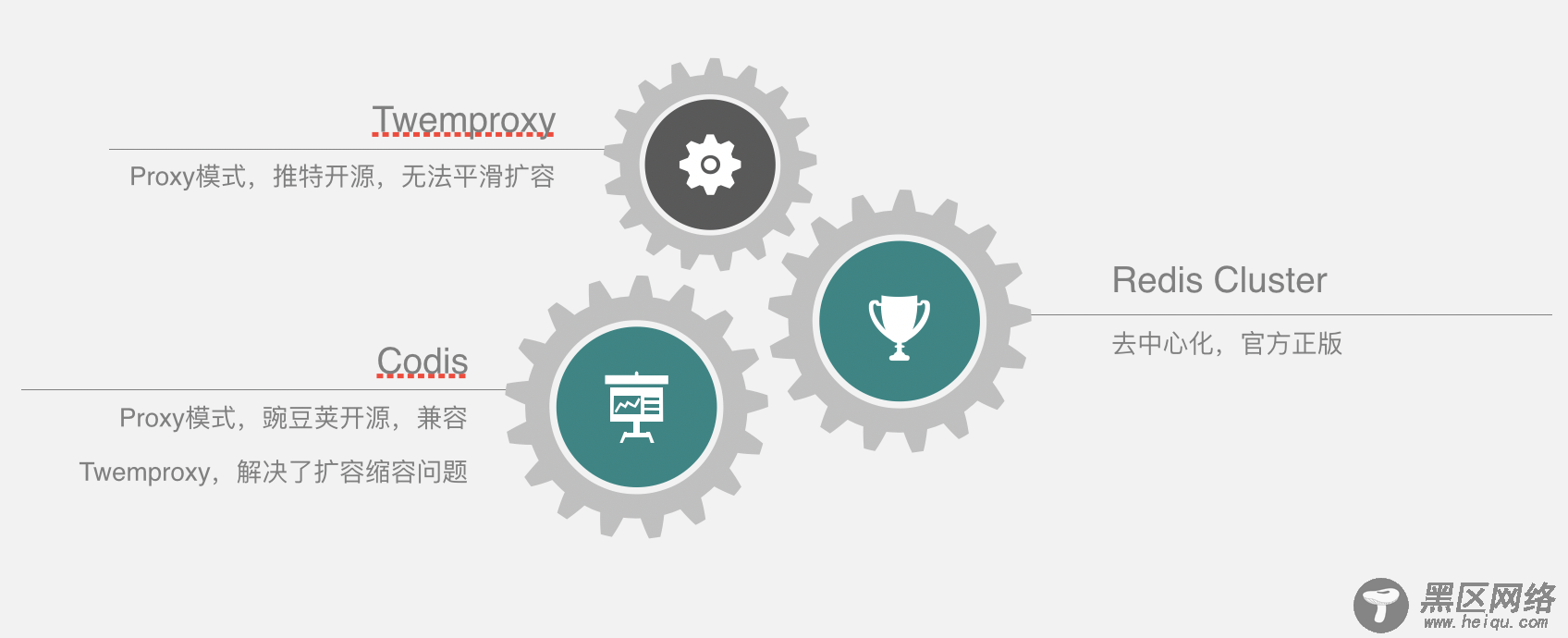
Twemproxy,是推特开源的,它最大的缺点就是无法平滑的扩缩容,而Codis解决了Twemproxy扩缩容的问题,而且兼容了Twemproxy,它是由豌豆荚开源的,和Twemproxy都是代理模式。其实Codis能发展起来的一个主要原因是它是在Redis官方集群方案漏洞百出的时候率先成熟稳定的。以现在的Redis官方集群方案,这两个好像没有太大差别了,不过我也没有去做性能测试,不清楚哪个最好。
Redis Cluster是由官方出品的,用去中心化的方式实现,不属于代理模式,今天主要讲codis,redis cluster后面也会过一下。下面,来看一下Codis的实现原理。
Codis原理我们换一种方式去讲,就按照Codis的架构演进一下,这样理解会比较清晰一点,假如现在只有一个Redis Server,怎么让它变得高可用?

开篇的时候也有讲,首先,能想到的就是做主从,这样就算主宕机了,从节点也能马上接替主节点的位置。
我们现在已经做成主从结构了,那到底是谁来负责主从之间的切换?
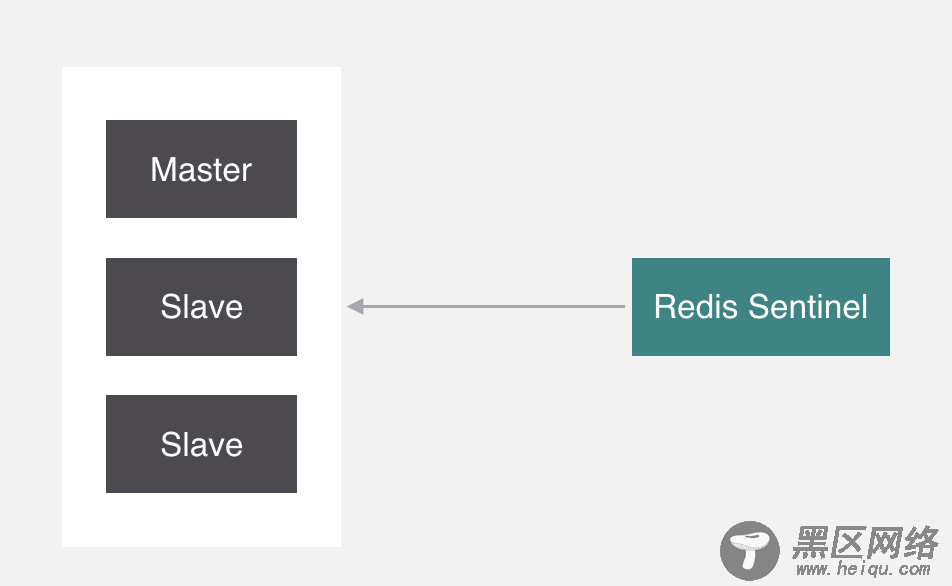
就是它,Sentinel,中文名叫哨兵,它呢,在Redis里面主要负责监控主从节点,如果主节点挂了,就会把从拉起来。但是哨兵本身也存在单点问题,所以它也需要做集群。
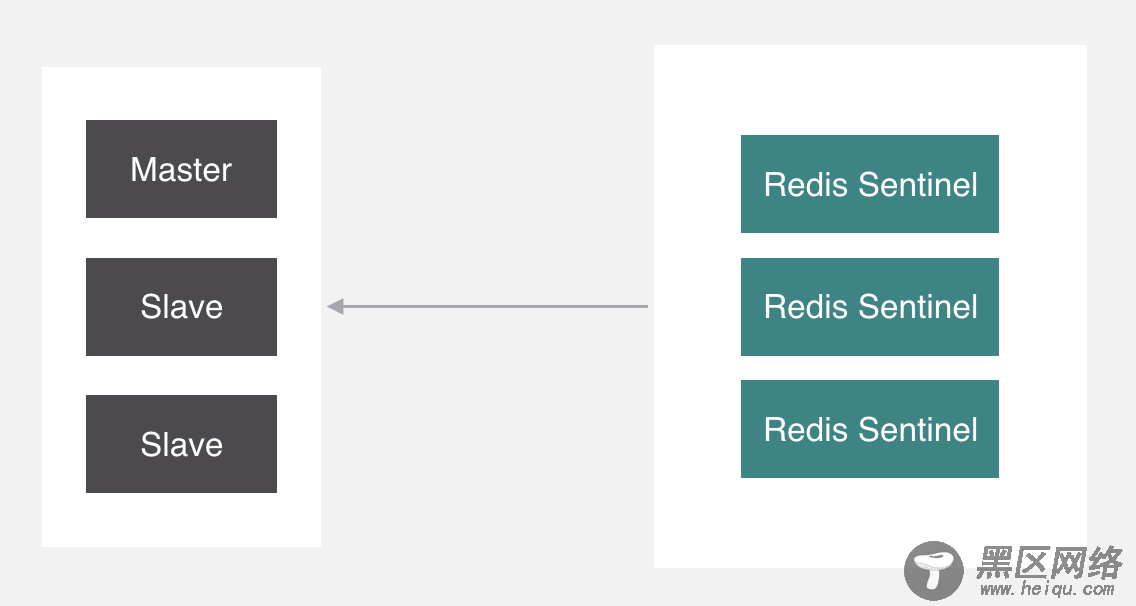
那么问题来了,哨兵是如何做主从切换呢?来看下哨兵的运行机制。
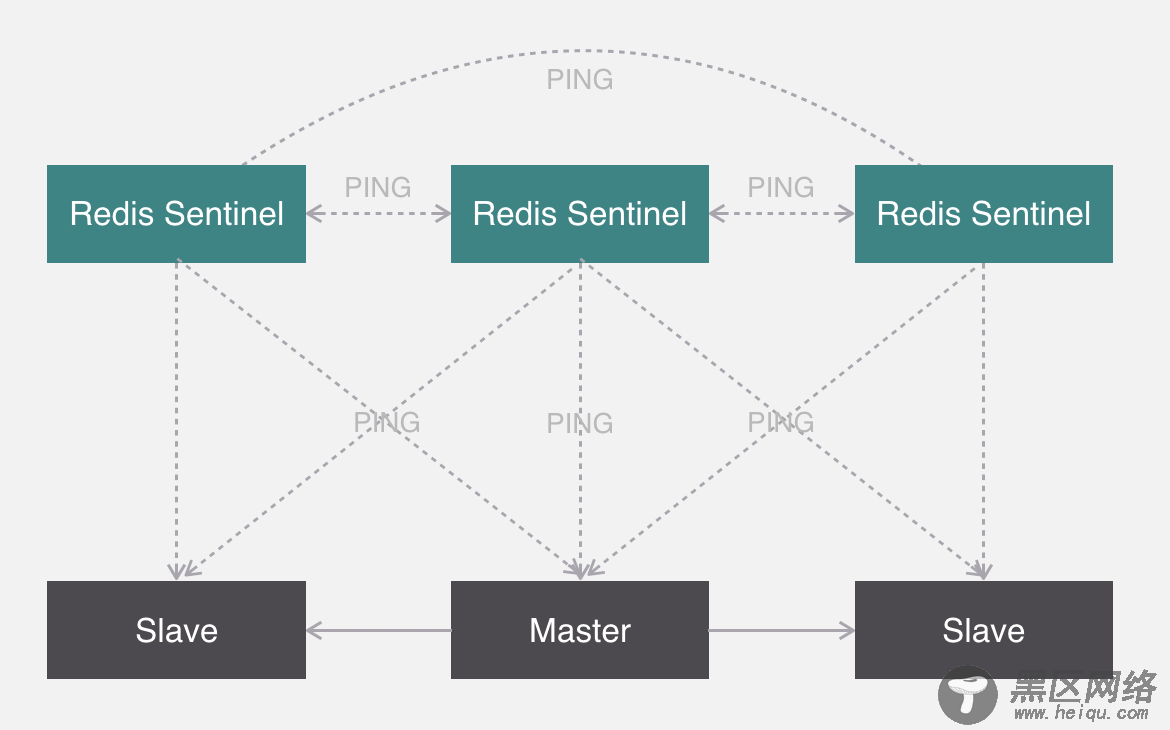
假如有三个哨兵和一主两从的节点,下面是一主多从,哨兵之间会互相监测运行状态,并且会交换一下节点监测的状态,同时哨兵也会监测主从节点的状态。
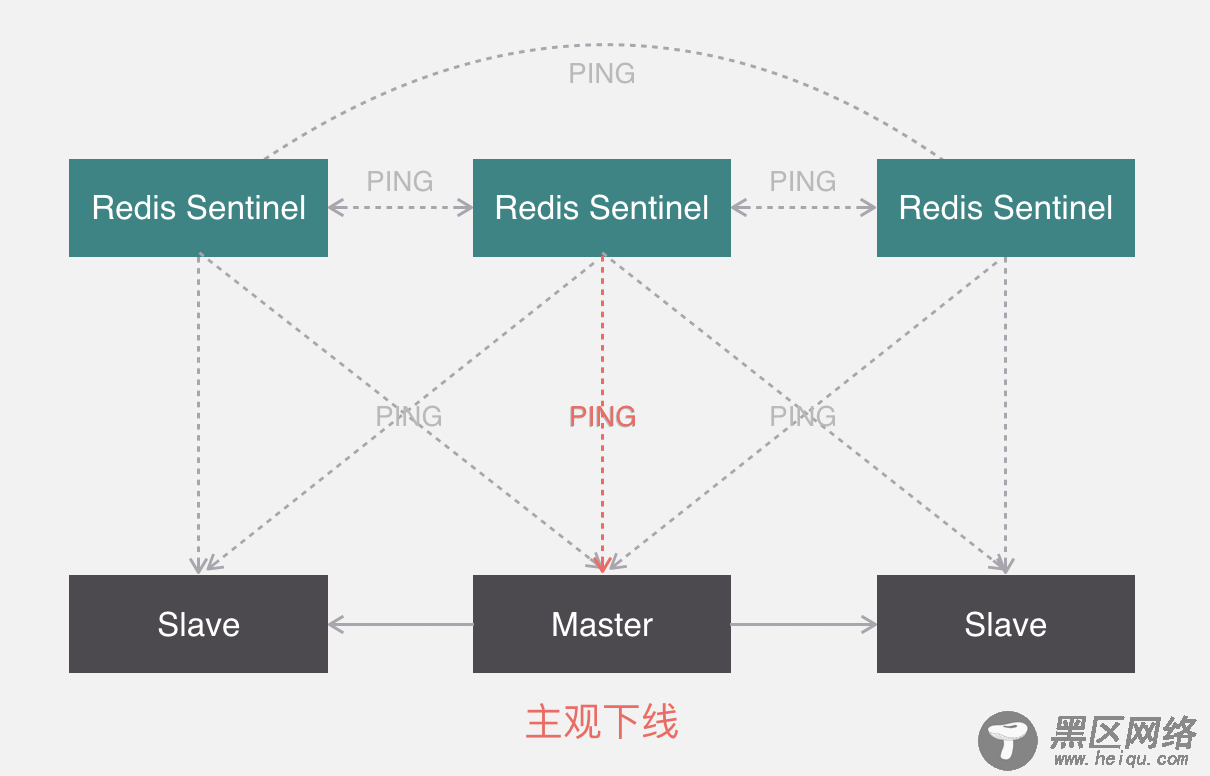
如果检测到某一个节点没有正常回复,并且距离上次正常回复的时间超过了某个阈值,那么就认为该节点为主观下线。
这个时候其他哨兵也会来监测该节点是不是真的主观下线,如果有足够多数量的哨兵都认为它确实主观下线了,那么它就会被标记为客观下线,这个时候哨兵会找下线节点的从节点,然后与其他哨兵协商出一个从节点做主节点,并将剩余的从节点指向新的主节点。

关于主从节点的切换有两个环节,第一个是哨兵要选举出领头人来负责下线机器的故障转移,第二是从Slave中选出主节点,领头人的选举规则是谁发现客观下线谁就可以马上要求其他哨兵认自己做老大,其他哨兵会无条件接受第一个发过来的人,并告知老大,如果超过一半人都同意了,那他老大的位置就坐实了。