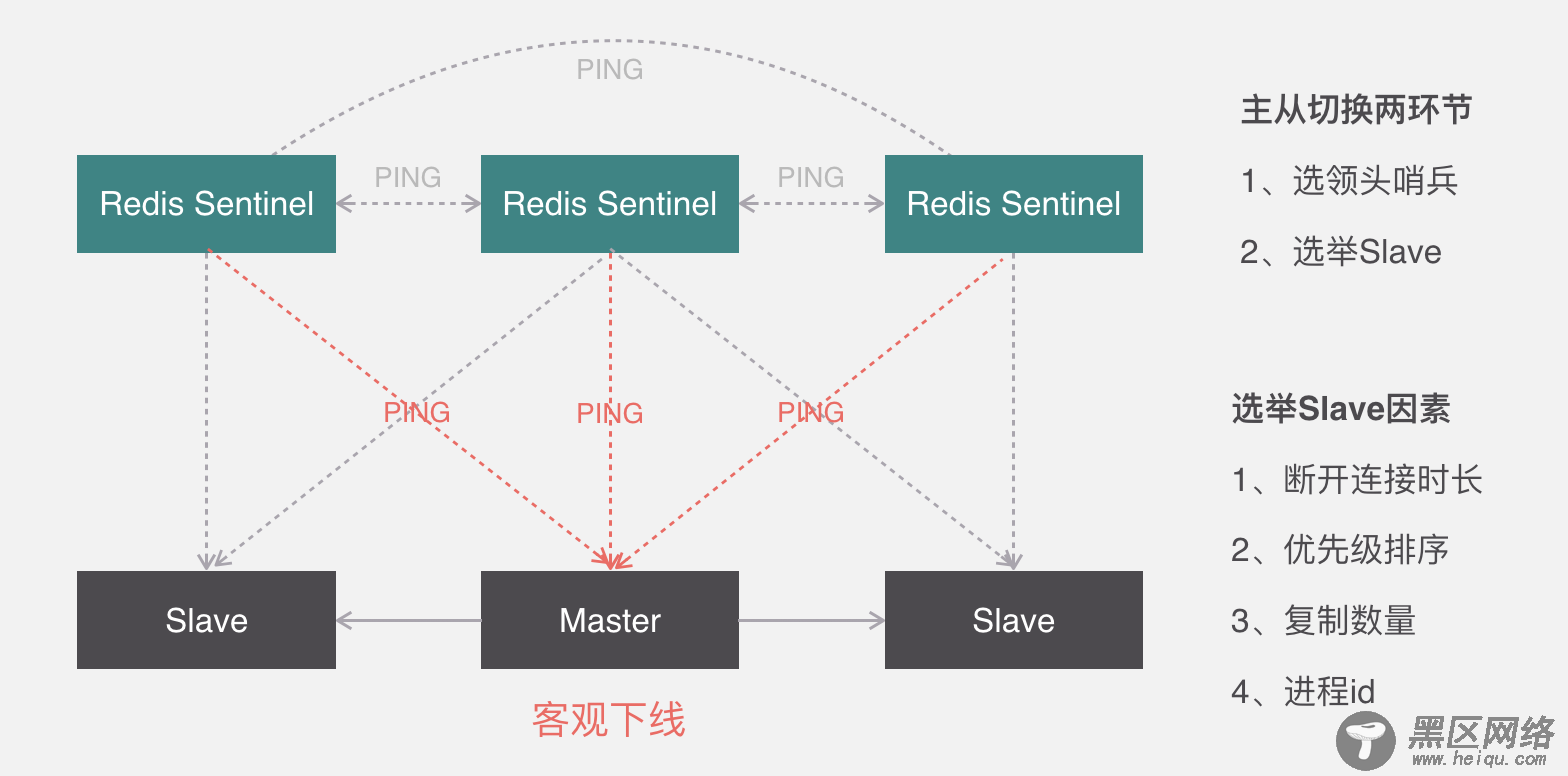
关于从节点选举,一共有四个因素影响选举的结果,分别是断开连接时长、优先级排序、复制数量、进程id,如果连接断开的比较久,超过了某个阈值,就直接失去了选举权,如果拥有选举权,那就看谁的优先级高,这个在配置文件里可以设置,数值越小优先级越高,如果优先级相同,就看谁从master中复制的数据最多,选最多的那个,如果复制数量也相同,就选择进程id最小的那个。
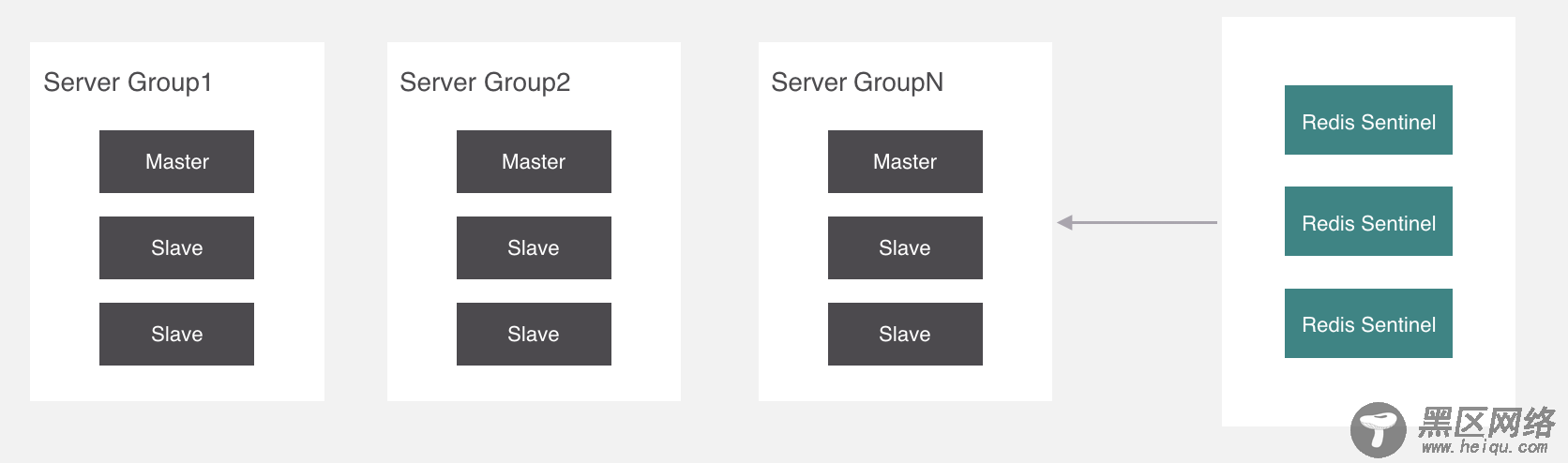
现在继续回过来,刚才讲痛点的时候说了,如果有存储海量数据的需求,同步会非常缓慢,所以我们应该把一个主从结构变成多个,把存储的key分摊到各个主从结构中来分担压力。
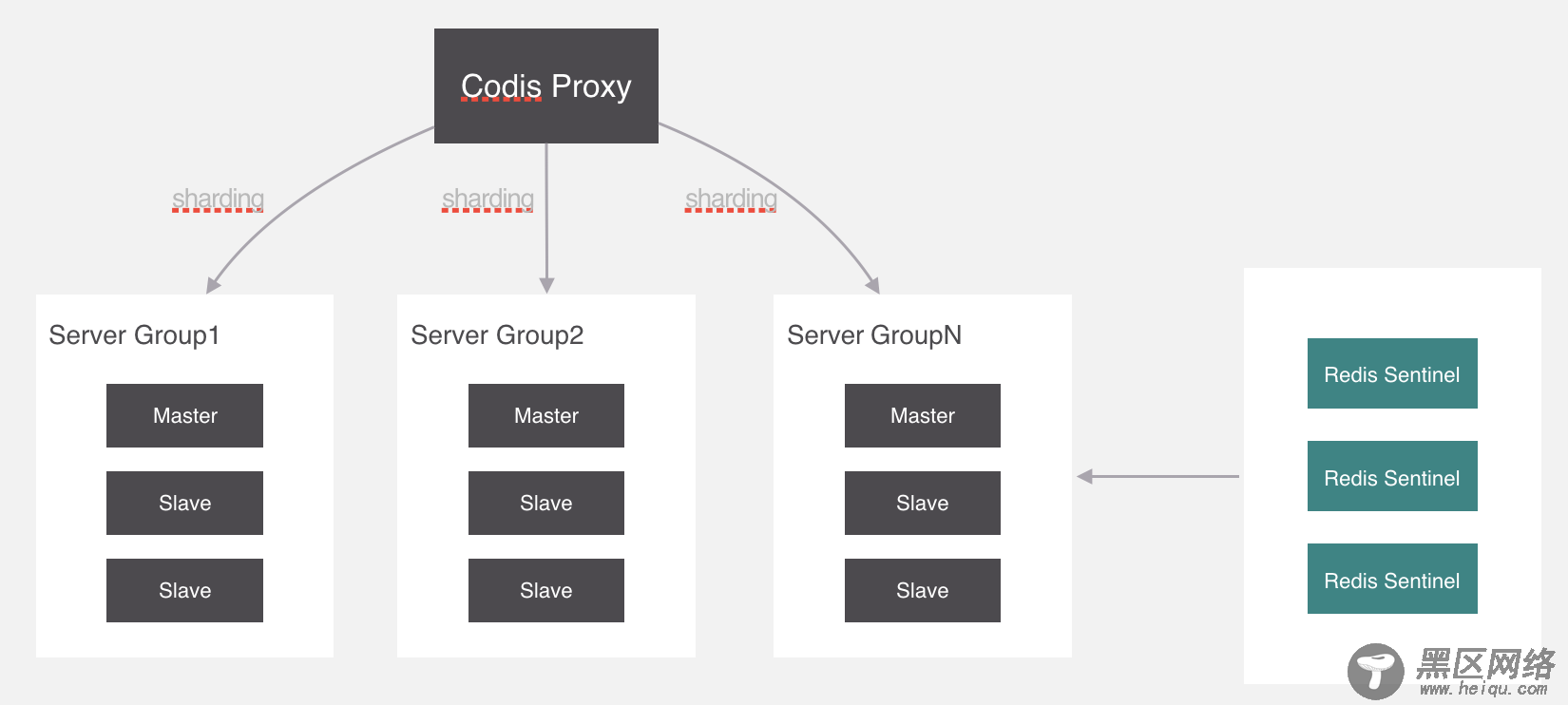
就像这样,代理通过一种算法把要操作的key经过计算后分配到各个组中,这个过程叫做分片,我们来看一下分片的实现原理。
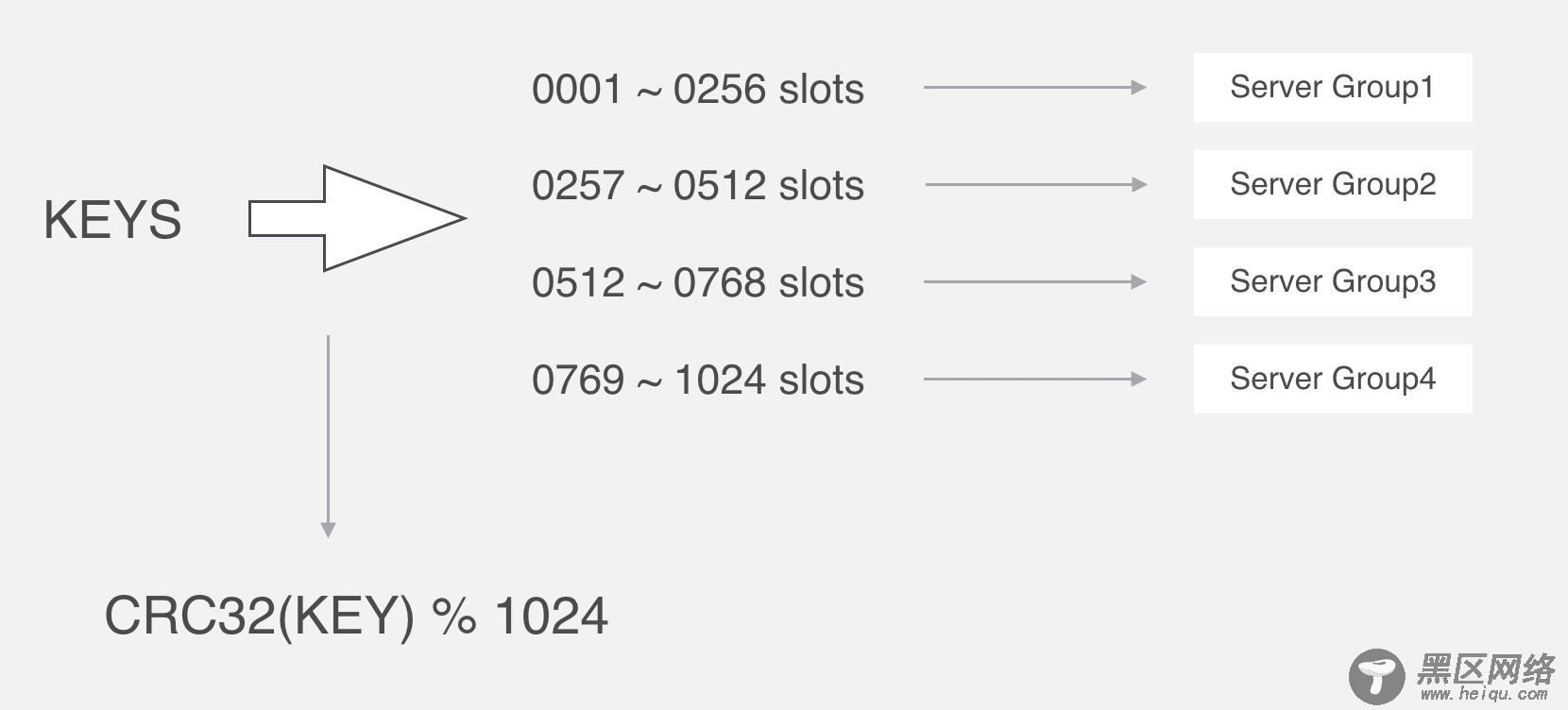
在Codis里面,它把所有的key分为1024个槽,每一个槽位都对应了一个分组,具体槽位的分配,可以进行自定义,现在如果有一个key进来,首先要根据CRC32算法,针对key算出32位的哈希值,然后除以1024取余,然后就能算出这个KEY属于哪个槽,然后根据槽与分组的映射关系,就能去对应的分组当中处理数据了。
CRC全称是循环冗余校验,主要在数据存储和通信领域保证数据正确性的校验手段,我去看了这个算法的原理,还没理解透彻,这里就先不讲了,省得误导大家。
我们继续回过来,刚才所讲的槽位和分组的映射关系就保存在codis proxy当中,但是codis proxy它本身也存在单点问题,所以需要对proxy做一个集群。
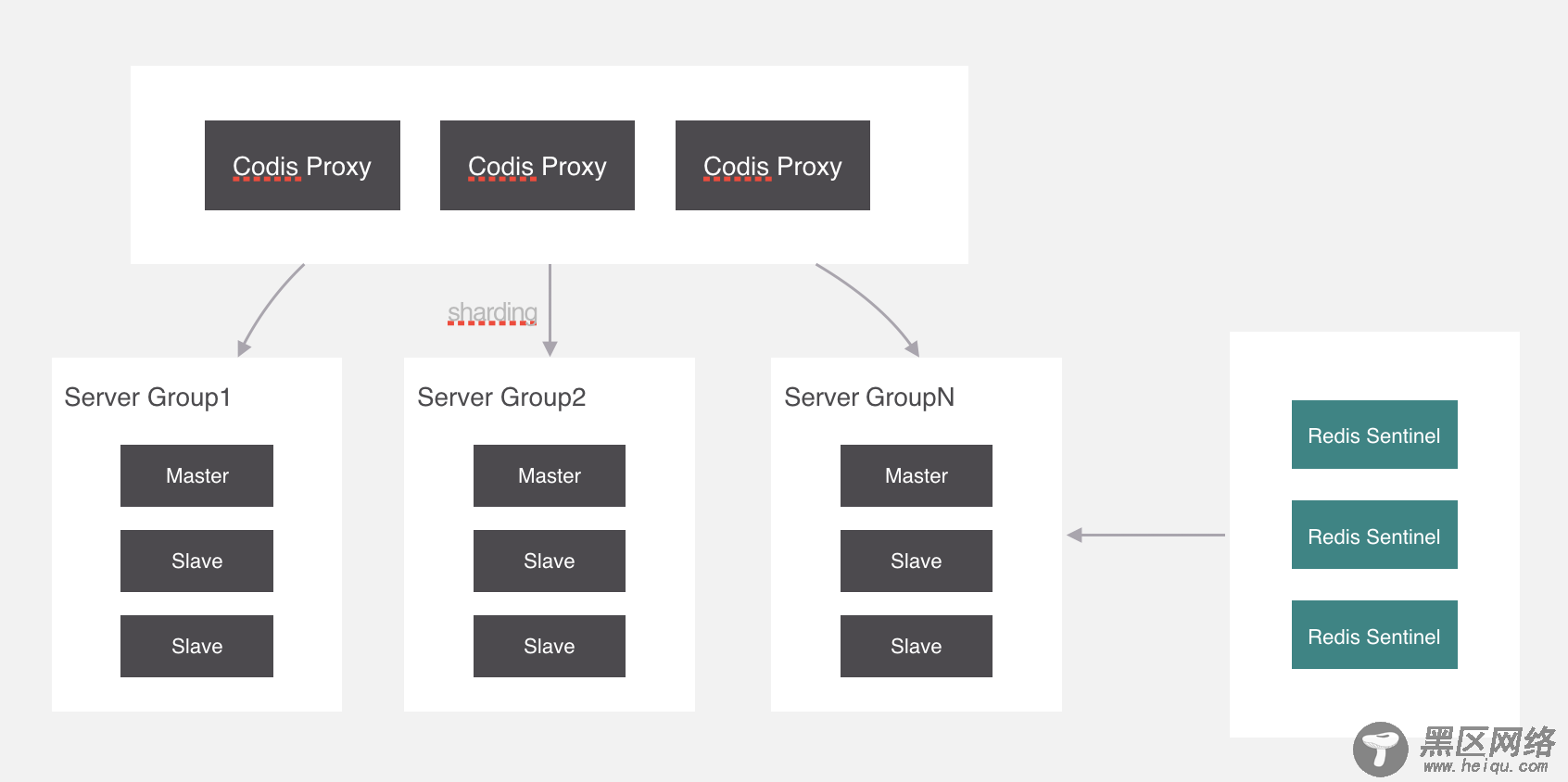
部署好集群之后,有一个问题,就是槽位的映射关系是保存在proxy里面的,不同proxy之间怎么同步映射关系?
在Codis中使用的是Zookeeper来保存映射关系,由proxy上来同步配置信息,其实它支持的不止zookeeper,还有etcd和本地文件。在zookeeper中保存的数据格式就是这个样子。除了这个还会存储一些其他的信息,比如分组信息、代理信息等,感兴趣可以自己去了解一下。
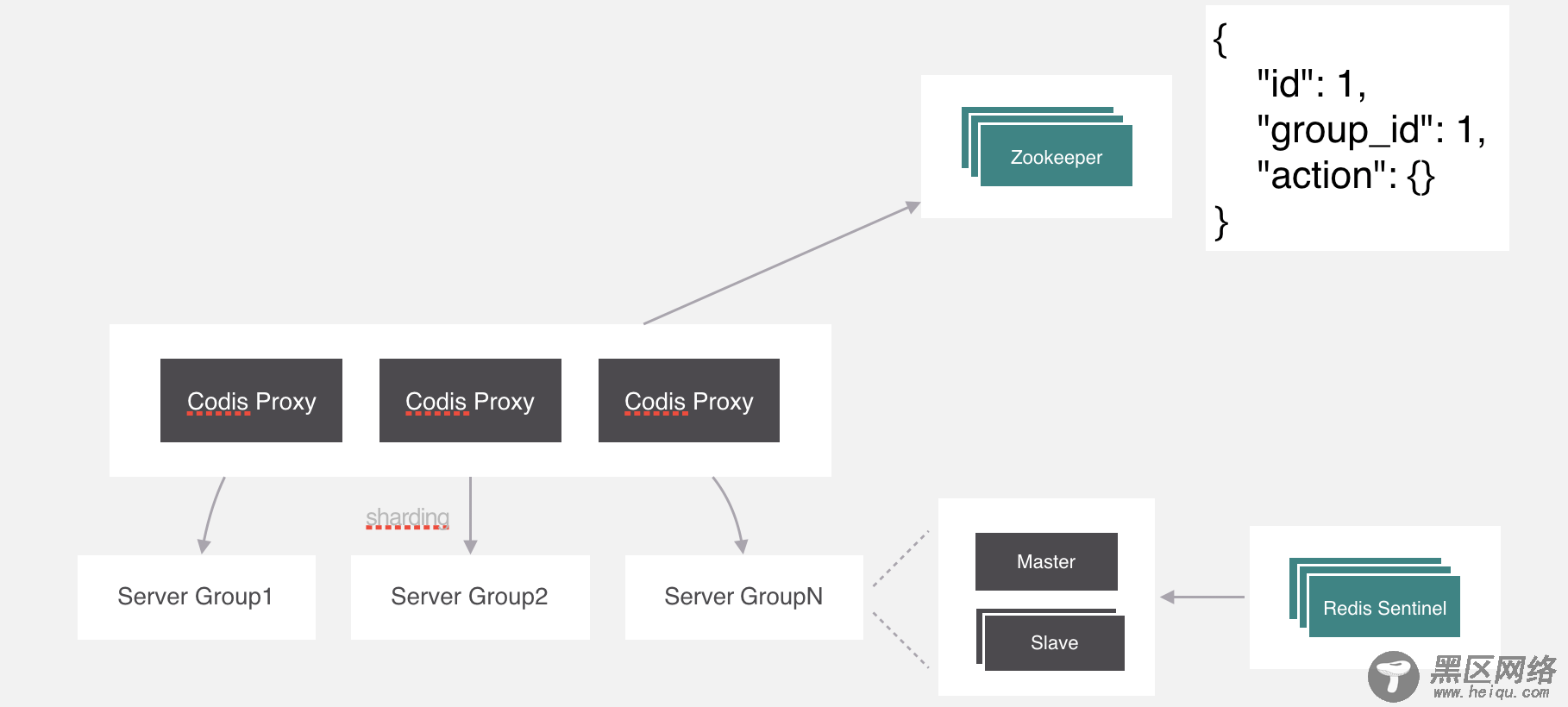
现在还有一个问题,就是codis proxy如果出现异常怎么处理,这个可能要利用一下k8s中pod的特性,在k8s里面可以设置pod冗余的数量,k8s会严格保证启动的数量与设置一致,所以只需要一个进程监测Proxy的异常,并且把它干掉就可以了,k8s会自动拉起来一个新的proxy。
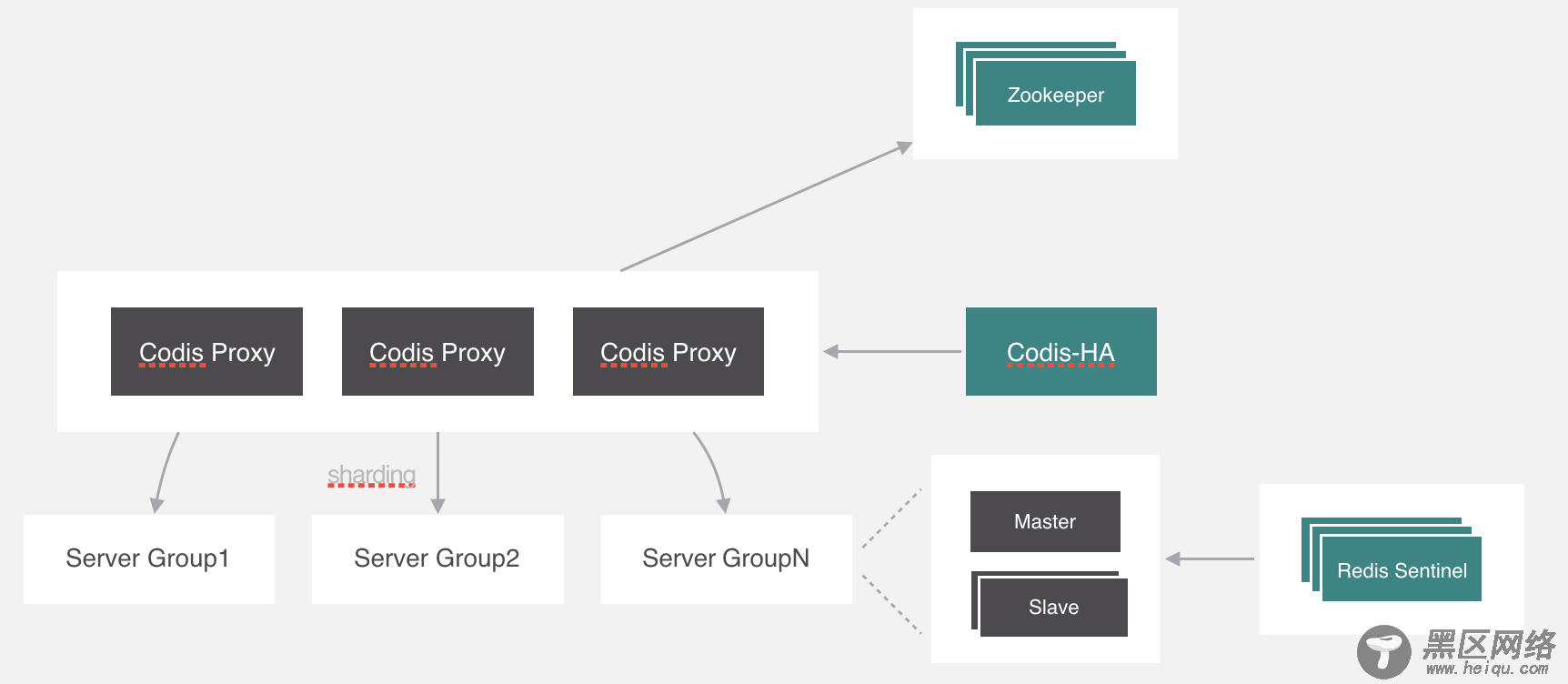
codis给这个进程起名叫codis-ha,codis-ha实时监测proxy的运行状态,如果有异常就会干掉,它包含了哨兵的功能,所以豌豆荚直接把哨兵去掉了。
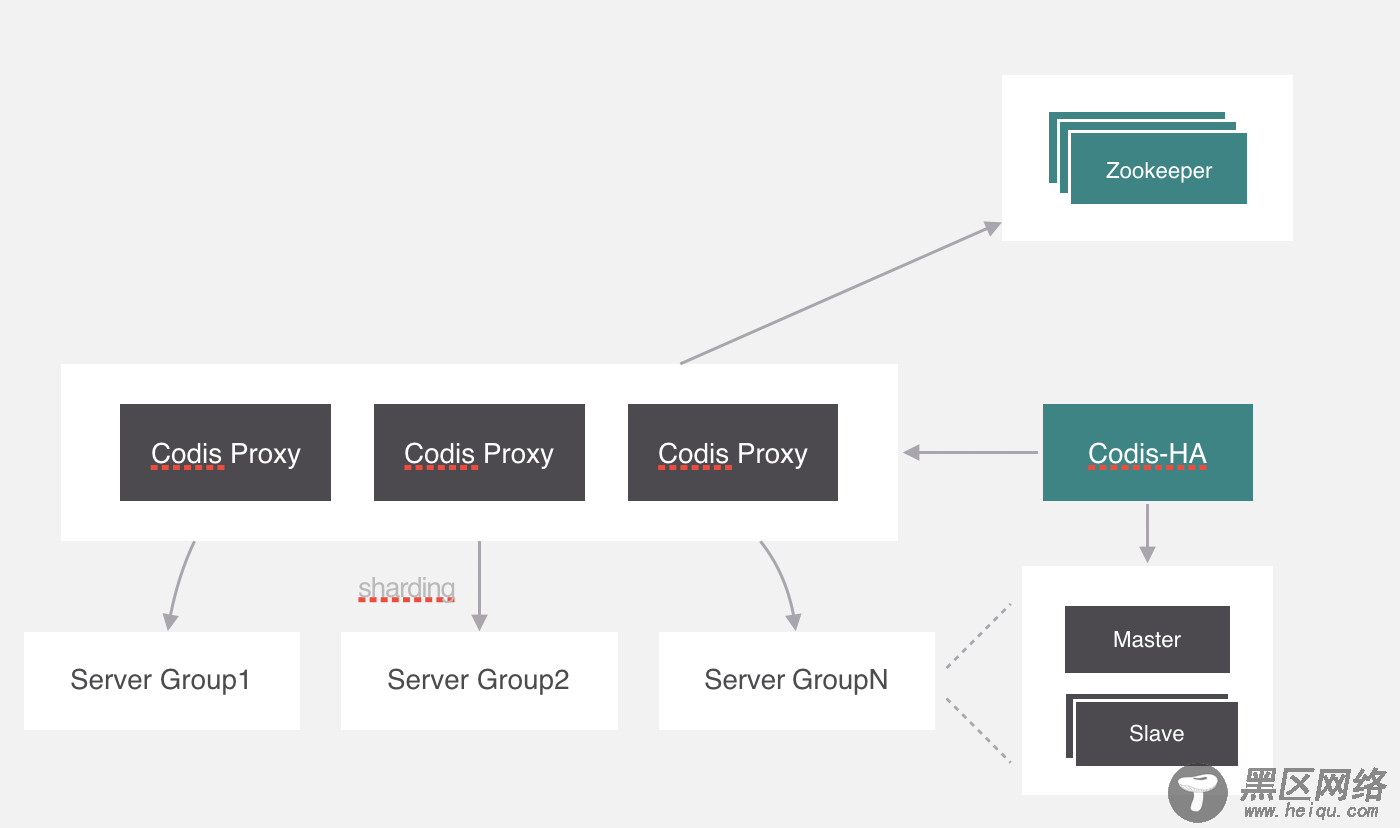
但是codis-ha在Codis整个架构中是没有办法直接操作代理和服务,因为所有的代理和服务的操作都要经过dashboard处理。所以部署的时候会利用k8s的亲和性将codis-ha与dashboard部署在同一个节点上。
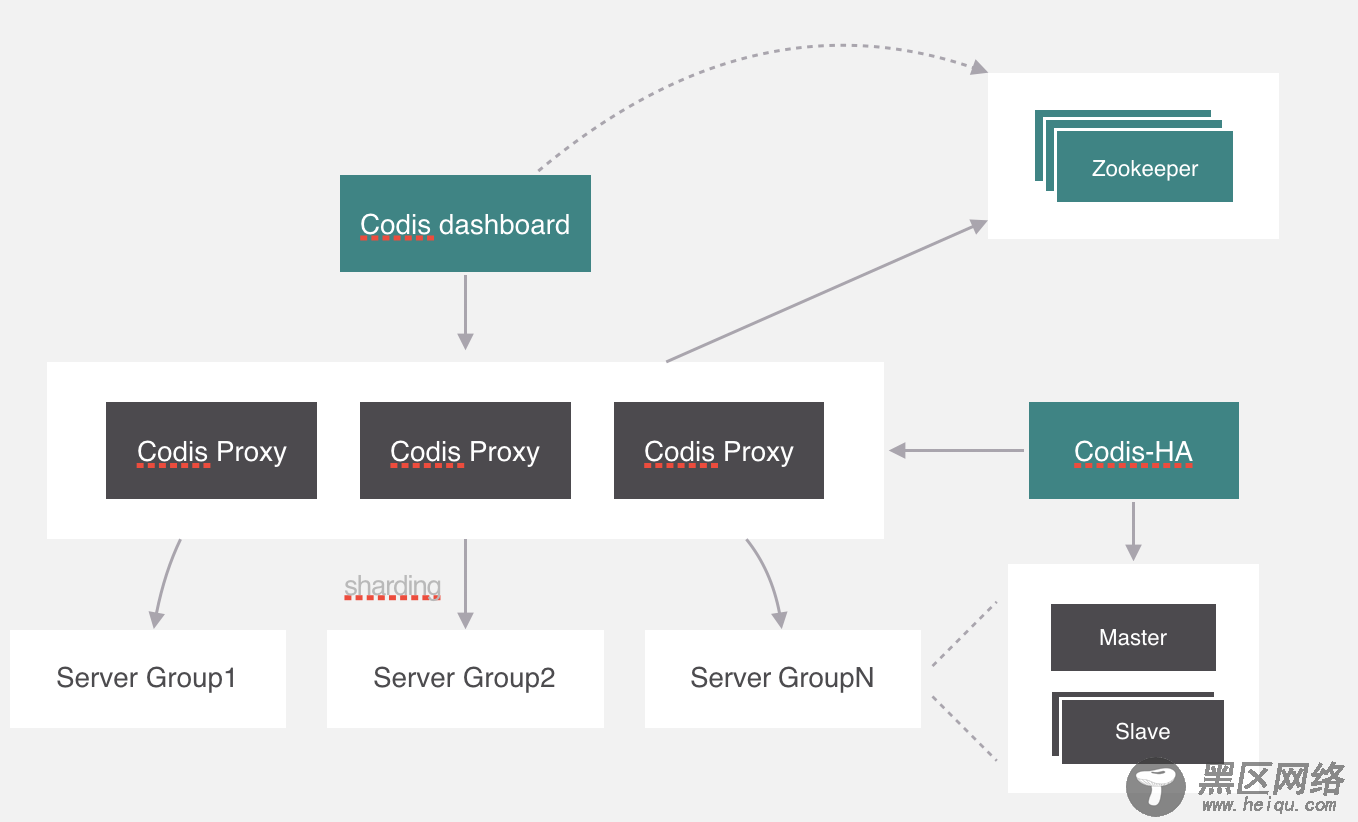
除了这些,codis自己开发了集群管理界面,集群管理可以通过界面化的方式更方便的管理集群,这个模块叫codis-fe,我们可以看一下这个界面。
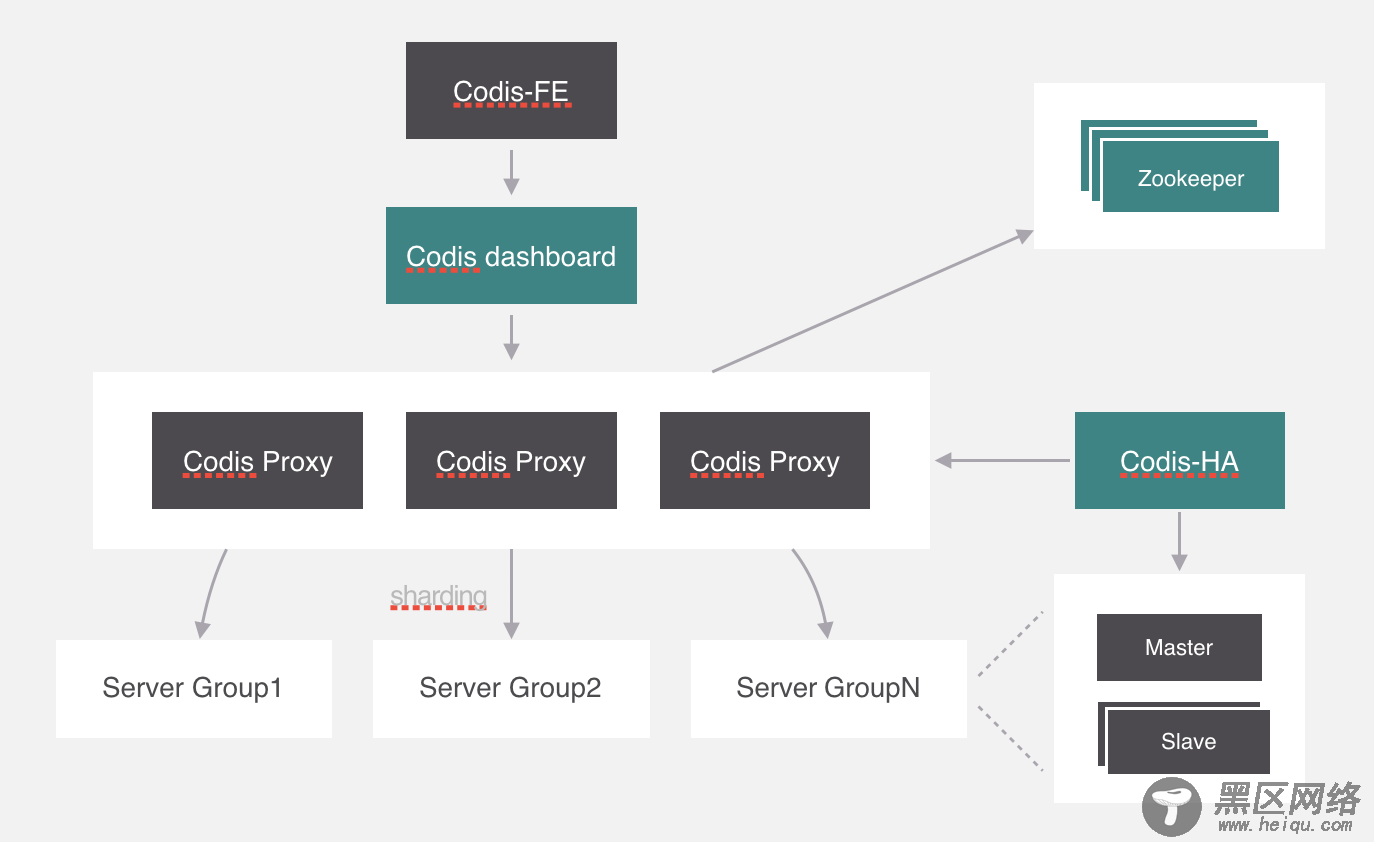
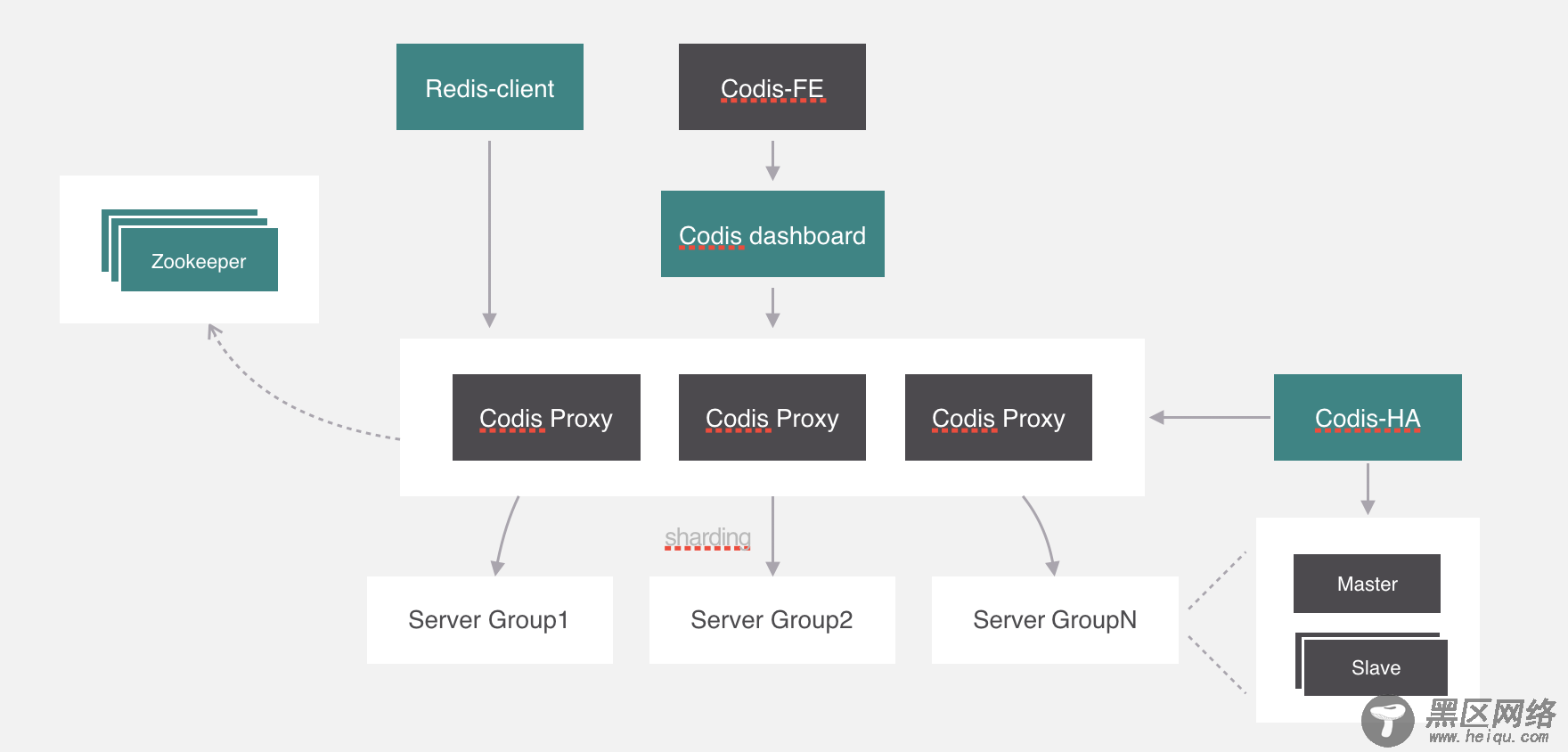
最后就是redis客户端了,这个没什么好讲的,客户端是直接通过代理来访问后端服务的。
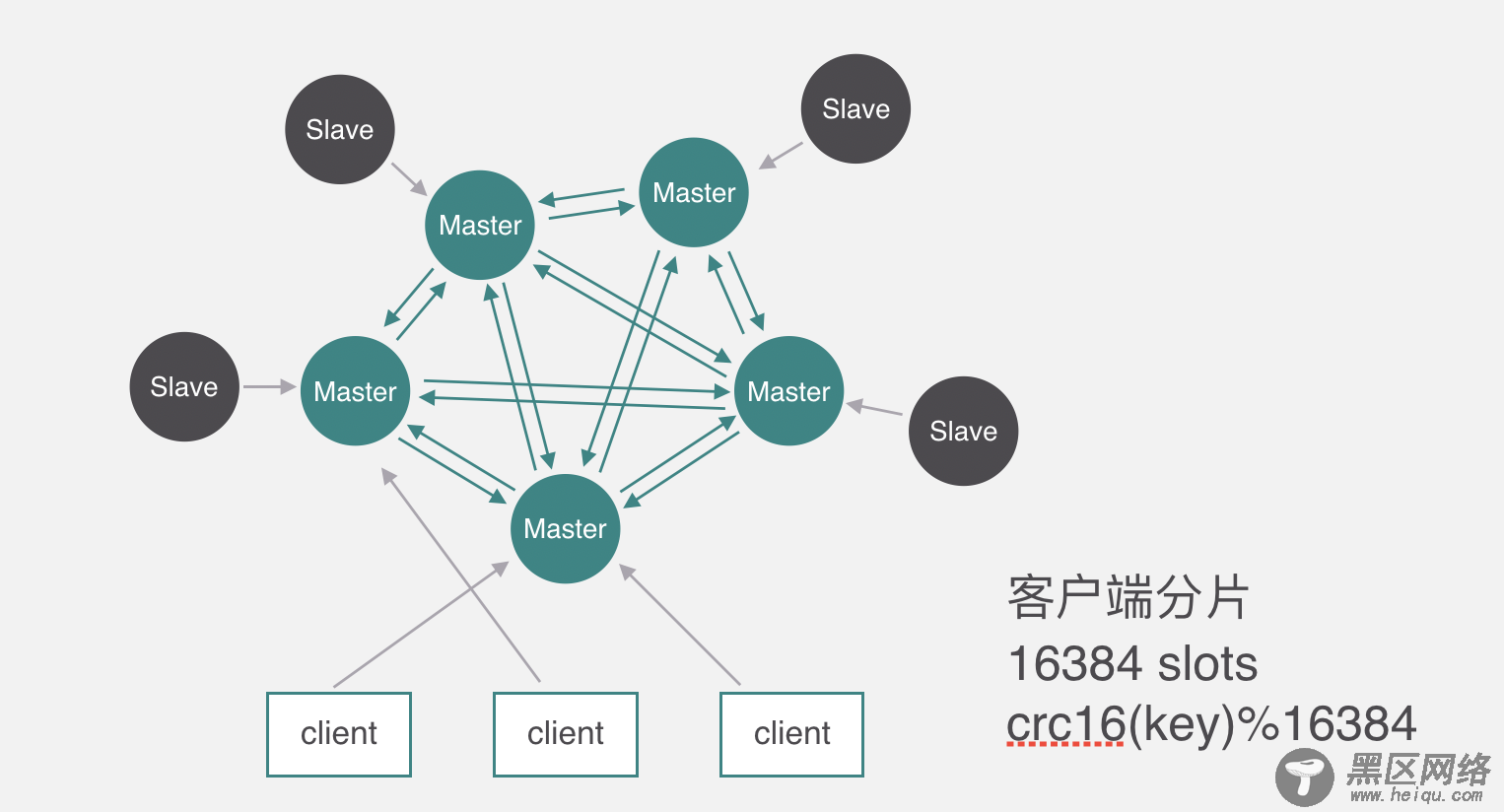
下面来看一下redis cluster的原理,它和codis不太一样,Codis它是通过代理分片的,但是Redis Cluster是去中心化的没有代理,所以只能通过客户端分片,它分片的槽数跟Codis不太一样,Codis是1024个,而Redis cluster有16384个,槽跟节点的映射关系保存在每个节点上,每个节点每秒钟会ping十次其他几个最久没通信的节点,其他节点也是一样的原理互相PING ,PING的时候一个是判断其他节点有没有问题,另一个是顺便交换一下当前集群的节点信息、包括槽与节点映射的关系等。客户端操作key的时候先通过分片算法算出所属的槽,然后随机找一个服务端请求。