对于逆序肯定环视(?<=Expression)来说,当子表达式Expression匹配成功时,(?<=Expression)匹配成功,并报告(?<=Expression)匹配当前位置成功。
对于逆序否定环视(?<!Expression)来说,当子表达式Expression匹配成功时,(?<!Expression)匹配失败;当子表达式Expression匹配失败时,(?<!Expression)匹配成功,并报告(?<!Expression)匹配当前位置成功;
顺序环视相当于在当前位置右侧附加一个条件,所以它的匹配尝试是从当前位置开始的,然后向右尝试匹配,直到某一位置使得匹配成功或失败为止。而逆序环视的特殊处在于,它相当于在当前位置左侧附加一个条件,所以它不是在当前位置开始尝试匹配的,而是从当前位置左侧某一位置开始,匹配到当前位置为止,报告匹配成功或失败。
顺序环视尝试匹配的起点是确定的,就是当前位置,而匹配的终点是不确定的。逆序环视匹配的起点是不确定的,是当前位置左侧某一位置,而匹配的终点是确定的,就是当前位置。
所以顺序环视相对是简单的,而逆序环视相对是复杂的。这也就是为什么大多数语言和工具都提供了对顺序环视的支持,而只有少数语言提供了对逆序环视支持的原因。
JavaScript中只支持顺序环视,不支持逆序环视。
Java中虽然顺序环视和逆序环视都支持,但是逆序环视只支持长度确定的表达式,逆序环视中量词只支持“?”,不支持其它长度不定的量词。长度确定时,引擎可以向左查找固定长度的位置作为起点开始尝试匹配,而如果长度不确定时,就要从位置0开始尝试匹配,处理的复杂度是显而易见的。
目前只有.NET中支持不确定长度的逆序环视。
逆序环视匹配过程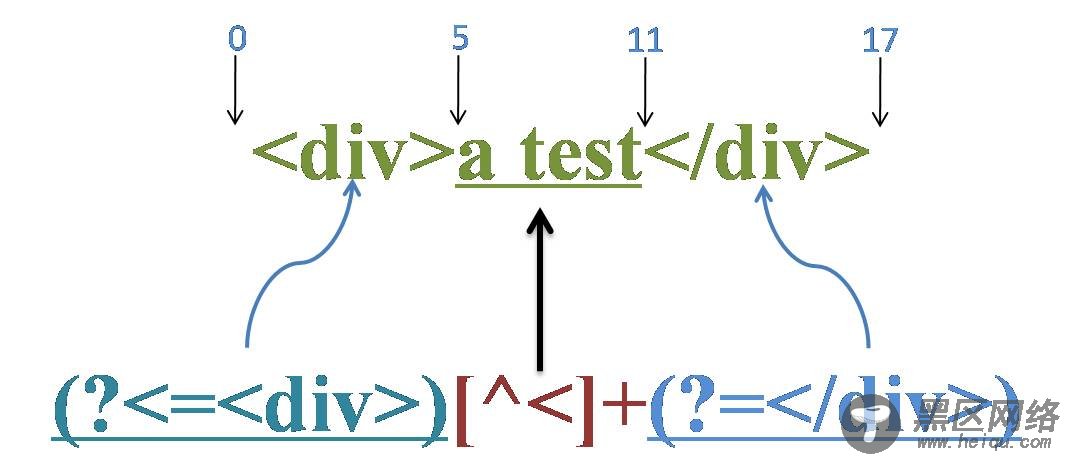
源字符串:<div>a test</div>
正则表达式:(?<=<div>)[^<]+(?=</div>)
这个正则的意义就是匹配<div>和</div>标签之间的内容,而不包括<div>和</div>标签本身。
匹配过程:
首先由“(?<=<div>)”取得控制权,从位置0开始匹配,由于位置0是起始位置,左侧没有任何内容,所以“<div>”必然匹配失败,从而环视表达式“(?<=<div>)”匹配失败,导致整个表达式在位置0处匹配失败。第一轮迭代匹配失败,正则引擎向前传动,由位置1处开始尝试第二次迭代匹配。
直到传动到位置5,“(?<=<div>)”取得控制权,向左查找5个位置,由位置0开始匹配,由“<div>”匹配“<div>”成功,从而“(?<=<div>)”匹配成功,匹配的结果为位置5,控制权交给“[^<]+”;“[^<]+”从位置5开始尝试匹配,匹配“a test”成功,控制权交给“(?=</div>)”;由“</div>”匹配“</div>”成功,从而“(?=</div>)”匹配成功,匹配结果为位置11。
此时正则表达式匹配完成,报告匹配成功。匹配结果为“a test”,开始位置为5,结束位置为11。其中“(?<=<div>)”匹配位置5,“[^<]+”匹配“a test”,“(?=</div>)”匹配位置11。
逆序否定环视的匹配过程与上述过程类似,区别只是当Expression匹配失败时,逆序否定表达式(?<!Expression)才匹配成功。
到此环视的匹配原理已基本讲解完,环视也就没有什么秘密可言了,所需要的,也只是多加练习而已。
3 环视应用今天写累了,暂时就给出一个环视的综合应用实例吧,至于环视的应用场景和技巧,后面再整理。
需求:数字格式化成用“,”的货币格式。
正则表达式:(?<=\d)(?<!\.\d*)(?=(?:\d{3})+(?:\.\d+|$))