string RegexStr = string.Empty; #region 字符串匹配 RegexStr = "^[0-9]+$"; //匹配字符串的开始和结束是否为0-9的数字[定位字符] Console.WriteLine("判断'R1123'是否为数字:{0}", Regex.IsMatch("R1123", RegexStr)); Console.WriteLine("判断'1123'是否为数字:{0}", Regex.IsMatch("1123", RegexStr)); RegexStr = @"\d+"; //匹配字符串中间是否包含数字(这里没有从开始进行匹配噢,任意位子只要有一个数字即可) Console.WriteLine("'R1123'是否包含数字:{0}", Regex.IsMatch("R1123", RegexStr)); Console.WriteLine("'博客园'是否包含数字:{0}", Regex.IsMatch("博客园", RegexStr)); //感谢@zhoumy的提醒..已修改错误代码 RegexStr = @"^Hello World[\w\W]*"; //已Hello World开头的任意字符(\w\W:组合可匹配任意字符) Console.WriteLine("'HeLLO WORLD xx hh xx'是否已Hello World开头:{0}", Regex.IsMatch("HeLLO WORLD xx hh xx", RegexStr, RegexOptions.IgnoreCase)); Console.WriteLine("'LLO WORLD xx hh xx'是否已Hello World开头:{0}", Regex.IsMatch("LLO WORLD xx hh xx", RegexStr,RegexOptions.IgnoreCase)); //RegexOptions.IgnoreCase:指定不区分大小写的匹配。 #endregion
显示结果:
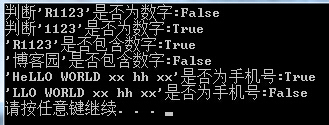
字符串查找:
实例代码:
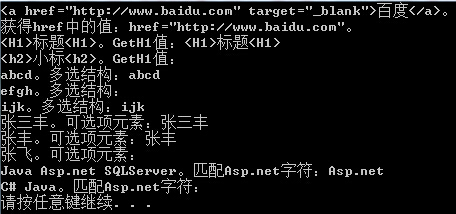
string RegexStr = string.Empty; #region 字符串查找 string LinkA = "<a href=https://www.jb51.net/article/\"http://www.baidu.com\" target=https://www.jb51.net/article/\"_blank\">百度</a>"; RegexStr = @"href=""[\S]+"""; // ""匹配" Match mt = Regex.Match(LinkA, RegexStr); Console.WriteLine("{0}。", LinkA); Console.WriteLine("获得href中的值:{0}。", mt.Value); RegexStr = @"<h[^23456]>[\S]+<h[1]>"; //<h[^23456]>:匹配h除了2,3,4,5,6之中的值,<h[1]>:h匹配包含括号内元素的字符 Console.WriteLine("{0}。GetH1值:{1}", "<H1>标题<H1>", Regex.Match("<H1>标题<H1>", RegexStr, RegexOptions.IgnoreCase).Value); Console.WriteLine("{0}。GetH1值:{1}", "<h2>小标<h2>", Regex.Match("<h2>小标<h2>", RegexStr, RegexOptions.IgnoreCase).Value); //RegexOptions.IgnoreCase:指定不区分大小写的匹配。 RegexStr = @"ab\w+|ij\w{1,}"; //匹配ab和字母 或 ij和字母 Console.WriteLine("{0}。多选结构:{1}", "abcd", Regex.Match("abcd", RegexStr).Value); Console.WriteLine("{0}。多选结构:{1}", "efgh", Regex.Match("efgh", RegexStr).Value); Console.WriteLine("{0}。多选结构:{1}", "ijk", Regex.Match("ijk", RegexStr).Value); RegexStr = @"张三?丰"; //?匹配前面的子表达式零次或一次。 Console.WriteLine("{0}。可选项元素:{1}", "张三丰", Regex.Match("张三丰", RegexStr).Value); Console.WriteLine("{0}。可选项元素:{1}", "张丰", Regex.Match("张丰", RegexStr).Value); Console.WriteLine("{0}。可选项元素:{1}", "张飞", Regex.Match("张飞", RegexStr).Value); /* 例如: July|Jul 可缩短为 July? 4th|4 可缩短为 4(th)? */ //匹配特殊字符 RegexStr = @"Asp\.net"; //匹配Asp.net字符,因为.是元字符他会匹配除换行符以外的任意字符。这里我们只需要他匹配.字符即可。所以需要转义\.这样表示匹配.字符 Console.WriteLine("{0}。匹配Asp.net字符:{1}", "Java Asp.net SQLServer", Regex.Match("Java Asp.net SQLServer", RegexStr).Value); Console.WriteLine("{0}。匹配Asp.net字符:{1}", "C# Java", Regex.Match("C# Java", RegexStr).Value); #endregion
显示结果:
贪婪与懒惰
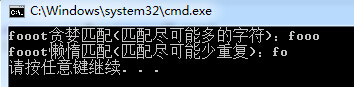
string f = "fooot"; //贪婪匹配 RegexStr = @"f[o]+"; Match m1 = Regex.Match(f, RegexStr); Console.WriteLine("{0}贪婪匹配(匹配尽可能多的字符):{1}", f, m1.ToString()); //懒惰匹配 RegexStr = @"f[o]+?"; Match m2 = Regex.Match(f, RegexStr); Console.WriteLine("{0}懒惰匹配(匹配尽可能少重复):{1}", f, m2.ToString());
显示结果:
从上面的例子中我们不难看出贪婪与懒惰的区别,他们的名子取的都很形象。
贪婪匹配:匹配尽可能多的字符。
懒惰匹配:匹配尽可能少的字符。
(exp)分组
在做爬虫时我们经常获得A中一些有用信息。如href,title和显示内容等。
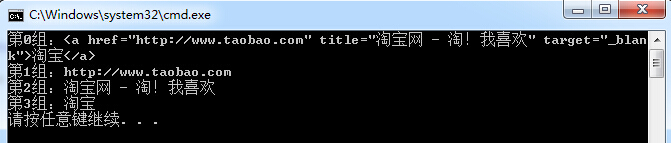
string TaobaoLink = "<a href=https://www.jb51.net/article/\"http://www.taobao.com\" title=https://www.jb51.net/article/\"淘宝网 - 淘!我喜欢\" target=https://www.jb51.net/article/\"_blank\">淘宝</a>"; RegexStr = @"<a[^>]+href=""(\S+)""[^>]+title=""([\s\S]+?)""[^>]+>(\S+)</a>"; Match mat = Regex.Match(TaobaoLink, RegexStr); for (int i = 0; i < mat.Groups.Count; i++) { Console.WriteLine("第"+i+"组:"+mat.Groups[i].Value); }
显示结果:
在正则表达式里使用()包含的文本自动会命名为一个组。上面的表达式中共使用了4个()可以认为是分为了4组。
输出结果共分为:4组。
0组:为我们所匹配的字符串。
1组:是我们第一个括号[href=""(\S+)""]中(\S+)所匹配的网址信息。内容为:。
2组:是第二个括号[title=""([\s\S]+?)""]中所匹配的内容信息。内容为:淘宝网 - 淘!我喜欢。