这里我们会看到+?懒惰限定符。title=""([\s\S]+?)"" 这里+?的下一个字符为"双引号,"双引号在匹配字符串后面还有三个。+?懒惰限定符会尽可能少重复,所他会匹配最前面那个"双引号。如果我们不使用+?懒惰限定符他会匹配到:淘宝网 - 淘!我喜欢" target= 会尽可能多重复匹配。
3组:是第三个括号[(\S+)]所匹配的内容信息。内容为:淘宝。
说明:反义元字符所对应的元字符都能组合匹配任意字符。如:[\w\W],[\s\S],[\d\D]..
(?<name>exp) 分组取名
当我们匹配分组信息过多后,在某种场合只需取当中某几组信息。这时我们可以对分组取名。通过分组名称来快速提取对应信息。
string Resume = "基本信息姓名:CK|求职意向:.NET软件工程师|性别:男|学历:本专|出生日期:1988-08-08|户籍:湖北.孝感|E - Mail:9245162@qq.com|手机:15000000000"; RegexStr = @"姓名:(?<name>[\S]+)\|\S+性别:(?<sex>[\S]{1})\|学历:(?<xueli>[\S]{1,10})\|出生日期:(?<Birth>[\S]{10})\|[\s\S]+手机:(?<phone>[\d]{11})"; Match matc = Regex.Match(Resume, RegexStr); Console.WriteLine("姓名:{0},手机号:{1}", matc.Groups["name"].ToString(), matc.Groups["phone"].ToString());
显示结果:
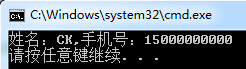
通过(?<name>exp)可以很轻易为分组取名。然后通过Groups["name"]取得分组值。
获得页面中A标签中href值
string PageInfo = @"<hteml> <divdiv1""> <a href=""https://www.baidu.con"" target=""_blank"">百度</a> <a href=""https://www.taobao.con"" target=""_blank"">淘宝</a> <a href=""https://www.cnblogs.com"" target=""_blank"">博客园</a> <a href=""https://www.google.con"" target=""_blank"">google</a> </div> <divdiv2""> <a href=""https://www.jb51.net/zufang/"">整租</a> <a href=""https://www.jb51.net/hezu/"">合租</a> <a href=""https://www.jb51.net/qiuzu/"">求租</a> <a href=""https://www.jb51.net/ershoufang/"">二手房</a> <a href=""https://www.jb51.net/shangpucz/"">商铺出租</a> </div> </hteml>"; RegexStr = @"<a[^>]+href=""(?<href>[\S]+?)""[^>]*>(?<text>[\S]+?)</a>"; MatchCollection mc = Regex.Matches(PageInfo, RegexStr); foreach (Match item in mc) { Console.WriteLine("href:{0}--->text:{1}",item.Groups["href"].ToString(),item.Groups["text"].ToString()); }
显示结果:
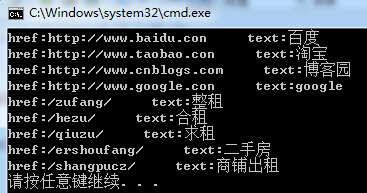
Replace 替换字符串
用户在输入信息时偶尔会包含一些敏感词,这时我们需要替换这个敏感词。
string PageInputStr = "靠.TMMD,今天真不爽...."; RegexStr = @"靠|TMMD|妈的"; Regex rep_regex = new Regex(RegexStr); Console.WriteLine("用户输入信息:{0}", PageInputStr); Console.WriteLine("页面显示信息:{0}", rep_regex.Replace(PageInputStr, "***"));
显示结果:
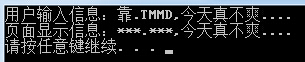
对一些敏感词直接替换成***代替。
Split 拆分字符串
string SplitInputStr = "1xxxxx.2ooooo.3eeee.4kkkkkk."; RegexStr = @"\d"; Regex spl_regex = new Regex(RegexStr); string[] str = spl_regex.Split(SplitInputStr); foreach (string item in str) { Console.WriteLine(item); }
显示结果:
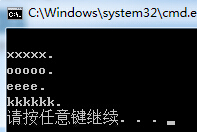
根据数字截取字符串。
首先,我们先看几个实际的例子:
1. 验证输入字符是否
javascript:
var ex = "^\\w+$";
var re = new RegExp(ex,"i");
return re.test(str);
VBScript
Dim regEx,flag,ex
ex = "^\w+$"
Set regEx = New RegExp
regEx.IgnoreCase = True
regEx.Global = True
regEx.Pattern = ex
flag = regEx.Test( str )
C#
System.String ex = @"^\w+$";
System.Text.RegularExpressions.Regex reg = new Regex( ex );
bool flag = reg.IsMatch( str );
2. 验证邮件格式
C#
System.String ex = @"^\w+@\w+\.\w+$";
System.Text.RegularExpressions.Regex reg = new Regex( ex );
bool flag = reg.IsMatch( str );
3. 更改日期的格式(用 dd-mm-yy 的日期形式代替 mm/dd/yy 的日期形式)
C#
String MDYToDMY(String input)
{
return Regex.Replace(input,
"\\b(?\\d{1,2})/(?\\d{1,2})/(?\\d{2,4})\\b",
"${day}-${month}-${year}");
}
4. 从 URL 提取协议和端口号
C#
String Extension(String url)
{
Regex r = new Regex(@"^(?\w+)://[^/]+?(?:\d+)?/",
RegexOptions.Compiled);
return r.Match(url).Result("${proto}${port}");
}
这里的例子可能是我们在网页开发中,通常会碰到的一些正则表达式,尤其在第一个例子中,给出了使用javascript,vbScript,C#等不同语言的实现方式,大家不难看出,对于不同的语言来说,正则表达式没有区别,只是正则表达式的实现类不同而已。而如何发挥正则表达式的公用,也要看实现类的支持。
(摘自msdn: Microsoft .NET 框架 SDK 提供大量的正则表达式工具,使您能够高效地创建、比较和修改字符串,以及迅速地分析大量文本和数据以搜索、移除和替换文本模式。ms-help://MS.VSCC/MS.MSDNVS.2052/cpgenref/html/cpconregularexpressionslanguageelements.htm)
下面我们逐个来分析这些例子:
1-2,这两个例子很简单,只是简单的验证字符串是否符合正则表达式规定的格式,其中使用的语法,在第一篇文章中都已经介绍过了,这里做一下简单的描述。
第1个例子的表达式: ^\w+$
^ -- 表示限定匹配开始于字符串的开始
\w – 表示匹配英文字符
+ -- 表示匹配字符出现1次或多次
$ -- 表示匹配字符到字符串结尾处结束
验证形如asgasdfs的字符串
第2个例子的表达式: ^\w+@\w+.\w+$
^ -- 表示限定匹配开始于字符串的开始
\w – 表示匹配英文字符
+ -- 表示匹配字符出现1次或多次
@ -- 匹配普通字符@
\. – 匹配普通字符.(注意.为特殊字符,因此要加上\转译)
$ -- 表示匹配字符到字符串结尾处结束
验证形如dragontt@sina.com的邮件格式
第3 个例子中,使用了替换,因此,我们还是先来看看正则表达式中替换的定义:
(ms-help://MS.VSCC/MS.MSDNVS.2052/cpgenref/html/cpconsubstitutions.htm)
替换
字符
含义
$123
替换由组号 123(十进制)匹配的最后一个子字符串。
${name}
替换由 (? ) 组匹配的最后一个子字符串。
$$
替换单个“$”字符。
$&
替换完全匹配本身的一个副本。
$`
替换匹配前的输入字符串的所有文本。
$'
替换匹配后的输入字符串的所有文本。
$+
替换最后捕获的组。
$_
替换整个输入字符串。
分组构造
(ms-help://MS.VSCC/MS.MSDNVS.2052/cpgenref/html/cpcongroupingconstructs.htm)
分组构造
定义
( )
捕获匹配的子字符串(或非捕获组;有关更多信息,请参阅正则表达式选项中的 ExplicitCapture 选项。)使用 () 的捕获根据左括号的顺序从 1 开始自动编号。捕获元素编号为零的第一个捕获是由整个正则表达式模式匹配的文本。
(?<name> )
将匹配的子字符串捕获到一个组名称或编号名称中。用于 name 的字符串不能包含任何标点符号,并且不能以数字开头。可以使用单引号替代尖括号,例如 (?'name')。
(?<name1-name2> )
平衡组定义。删除先前定义的 name2 组的定义并在 name1 组中存储先前定义的 name2 组和当前组之间的间隔。如果未定义 name2 组,则匹配将回溯。由于删除 name2 的最后一个定义会显示 name2 的先前定义,因此该构造允许将 name2 组的捕获堆栈用作计数器以跟踪嵌套构造(如括号)。在此构造中,name1 是可选的。可以使用单引号替代尖括号,例如 (?'name1-name2')。
(?: )
非捕获组。
(?imnsx-imnsx: )
应用或禁用子表达式中指定的选项。例如,(?i-s: ) 将打开不区分大小写并禁用单行模式。有关更多信息,请参阅正则表达式选项。
(?= )
零宽度正预测先行断言。仅当子表达式在此位置的右侧匹配时才继续匹配。例如,\w+(?=https://www.jb51.net/article/\d) 与后跟数字的单词匹配,而不与该数字匹配。此构造不会回溯。
(?! )
零宽度负预测先行断言。仅当子表达式不在此位置的右侧匹配时才继续匹配。例如,\b(?!un)\w+\b 与不以 un 开头的单词匹配。
(?<= )
零宽度正回顾后发断言。仅当子表达式在此位置的左侧匹配时才继续匹配。例如,(?<=19)99 与跟在 19 后面的 99 的实例匹配。此构造不会回溯。
(?
零宽度负回顾后发断言。仅当子表达式不在此位置的左侧匹配时才继续匹配。
(?> )
非回溯子表达式(也称为贪婪子表达式)。该子表达式仅完全匹配一次,然后就不会逐段参与回溯了。(也就是说,该子表达式仅与可由该子表达式单独匹配的字符串匹配。)
我们还是先简单的了解一下这两个概念:
分组构造:
最基本的构造方式就是(),在左右括号中括起来的部分,就是一个分组;
更进一步的分组就是形如:(?<name> )的分组方式,这种方式与第一种方式的不同点,就是对分组的部分进行了命名,这样就可以通过该组的命名来获取信息;
(还有形如(?= )等等的分组构造,我们这篇的例子中也没有使用到,下次我们在来介绍)
替换:
上面提到了两种基本的构造分组方式()以及(?<name> ),通过这两种分组方式,我们可以得到形如$1,${name}的匹配结果。
这样说,可能概念上还是有些模糊,我们还是结合上面的例子来说:
第三个例子的正则表达式为:\\b(?\\d{1,2})/(?\\d{1,2})/(?\\d{2,4})\\b
(解释一下,为什么这里都是\\一起用:这里是C#的例子,在C#语言中\是转译字符,要想字符串中的\不转译,就需要使用\\或者在整个字符串的开始加上@标记,即上面等价与
@”\b(?\d{1,2})/(?\d{1,2})/(?\d{2,4}\b”)
\b -- 是一种特殊情况。在正则表达式中,除了在 [] 字符类中表示退格符以外,\b 表示字边界(在 \w 和 \W 字符之间)。在替换模式中,\b 始终表示退格符
(?\d{1,2}) – 构造一个名为month的分组,这个分组匹配一个长度为1-2的数字
/ -- 匹配普通的/字符
(?\d{1,2}) --构造一个名为day的分组,这个分组匹配一个长度为1-2的数字
/ -- 匹配普通的/字符
(?\d{2,4}\b”) --构造一个名为year的分组,这个分组匹配一个长度为2-4的数字
这里还不能够看出这些分组的作用,我们接着看这一句
${day}-${month}-${year}
${day} – 获得上面构造的名为day的分组匹配后的信息
- -- 普通的-字符
${month} --获得上面构造的名为month的分组匹配后的信息
- -- 普通的-字符
${year} --获得上面构造的名为year的分组匹配后的信息
举例来说:
将形如04/02/2003的日期使用例3种的方法替换
(?\d{1,2}) 分组将匹配到04由${month}得到这个匹配值
(?\d{1,2}) 分组将匹配到02由${day}得到这个匹配值
(?\d{1,2}) 分组将匹配到2003由${year}得到这个匹配值
了解了这个例子后,我们在来看第4个例子就很简单了。
第4个例子的正则
^(?\w+)://[^/]+?(?:\d+)?/
^ -- 表示限定匹配开始于字符串的开始
(?\w+) – 构造一个名为proto的分组,匹配一个或多个字母
: -- 普通的:字符
// -- 匹配两个/字符
[^/] – 表示这里不允许是/字符
+? – 表示指定尽可能少地使用重复但至少使用一次匹配
(?:\d+) – 构造一个名为port的分组,匹配形如:2134(冒号+一个或多个数字)
? – 表示匹配字符出现0次或1次
/ -- 匹配/字符
最后通过${proto}${port}来获取两个分组构造的匹配内容
(有关Regex对象的用法,参考
ms-help://MS.VSCC/MS.MSDNVS.2052/cpref/html/frlrfSystemTextRegularExpressionsRegexMembersTopic.htm)
您可能感兴趣的文章: