前面的python3入门系列基本上也对python入了门,从这章起就开始介绍下python的爬虫教程,拿出来给大家分享;爬虫说的简单,就是去抓取网路的数据进行分析处理;这章主要入门,了解几个爬虫的小测试,以及对爬虫用到的工具介绍,比如集合,队列,正则表达式;
用python抓取指定页面:
代码如下:
import urllib.request url= "http://www.baidu.com" data = urllib.request.urlopen(url).read()# data = data.decode('UTF-8') print(data)
urllib.request.urlopen(url) 官方文档 返回一个 http.client.HTTPResponse 对象, 这个对象又用到的read()方法;返回数据;这个函数返回一个 http.client.HTTPResponse 对象, 这个对象又有各种方法, 比如我们用到的read()方法;
查找可变网址:
import urllib import urllib.request data={} data['word']='one peace' url_values=urllib.parse.urlencode(data) url="http://www.baidu.com/s?" full_url=url+url_values a = urllib.request.urlopen(full_url) data=a.read() data=data.decode('UTF-8') print(data) ##打印出网址: a.geturl()
data是一个字典, 然后通过urllib.parse.urlencode()来将data转换为 ‘word=one+peace'的字符串, 最后和url合并为full_url
python正则表达式介绍:
队列 介绍
在爬虫的程序中用到了广度优先级算法,该算法用到了数据结构,当然你用list也可以实现队列,但是效率不高。现在在此处介绍下:在容器中有队列:collection.deque
#队列简单测试:
from collections import deque
queue=deque(["peace","rong","sisi"])
queue.append("nick")
queue.append("pishi")
print(queue.popleft())
print(queue.popleft())
print(queue)
集合介绍:
在爬虫程序中, 为了不重复爬那些已经爬过的网站, 我们需要把爬过的页面的url放进集合中, 在每一次要爬某一个url之前, 先看看集合里面是否已经存在. 如果已经存在, 我们就跳过这个url; 如果不存在, 我们先把url放入集合中, 然后再去爬这个页面.
Python 还 包 含 了 一 个 数 据 类 型—— set ( 集 合 ) 。 集 合 是 一 个 无 序 不 重 复 元素 的 集 。 基 本 功 能 包 括 关 系 测 试 和 消 除 重 复 元 素 。 集 合 对 象 还 支 持 union( 联合),intersection(交),difference(差)和 sysmmetric difference(对称差集)等数学运算。
大括号或 set() 函数可以用来创建集合。 注意:想要创建空集合,你必须使用set() 而不是 {} 。{}用于创建空字典;
集合的创建演示如下:
a={"peace","peace","rong","rong","nick"}
print(a)
"peace" in a
b=set(["peace","peace","rong","rong"])
print(b)
#演示联合
print(a|b)
#演示交
print(a&b)
#演示差
print(a-b)
#对称差集
print(a^b)
#输出:
{'peace', 'rong', 'nick'}
{'peace', 'rong'}
{'peace', 'rong', 'nick'}
{'peace', 'rong'}
{'nick'}
{'nick'}
正则表达式
在爬虫时收集回来的一般是字符流,我们要从中挑选出url就要求有简单的字符串处理能力,而用正则表达式可以轻松的完成这一任务;
正则表达式的步骤:1,正则表达式的编译 2,正则表达式匹配字符串 3,结果的处理
下图列出了正则表达式的语法:
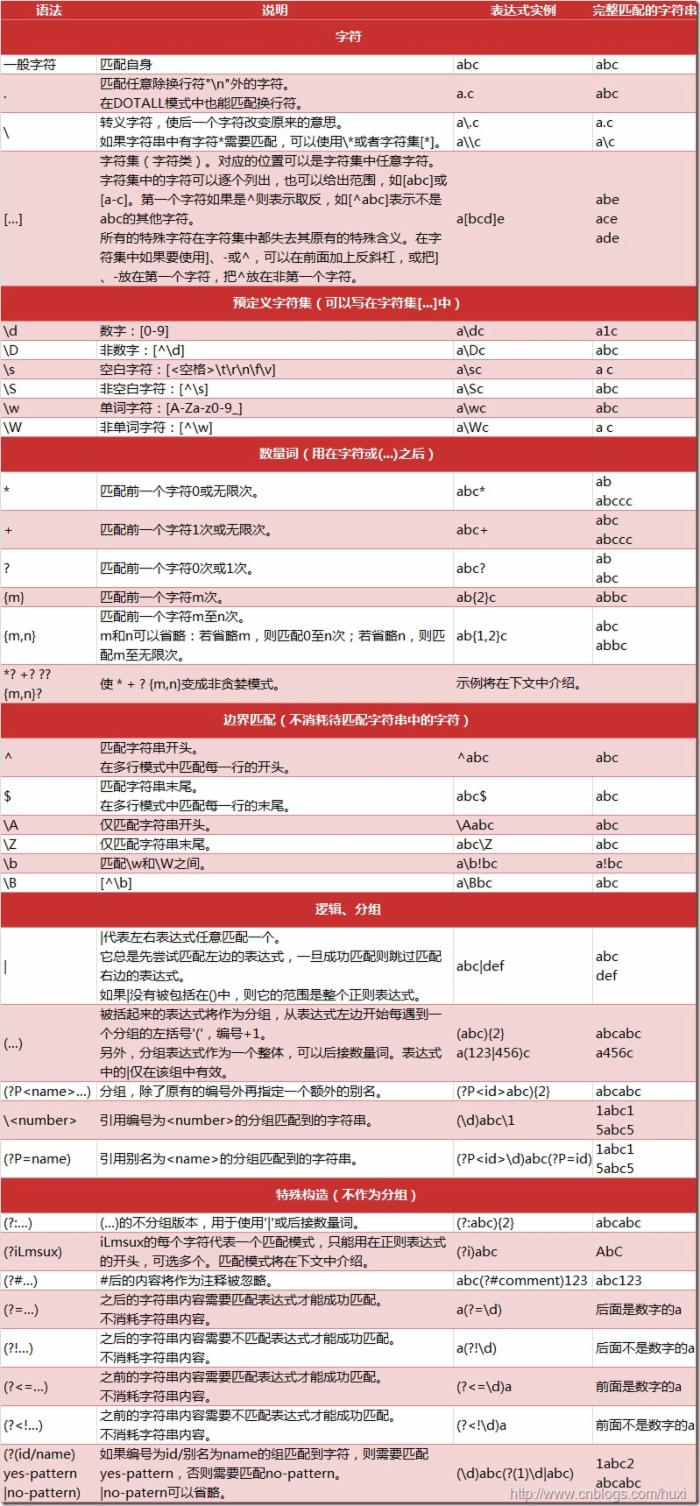
在pytho中使用正则表达式,需要引入re模块;下面介绍下该模块中的一些方法;
1.compile和match
re模块中compile用于生成pattern的对象,再通过调用pattern实例的match方法处理文本最终获得match实例;通过使用match获得信息;
import re # 将正则表达式编译成Pattern对象 pattern = re.compile(r'rlovep') # 使用Pattern匹配文本,获得匹配结果,无法匹配时将返回None m = pattern.match('rlovep.com') if m: # 使用Match获得分组信息 print(m.group()) ### 输出 ### # rlovep re.compile(strPattern[, flag]):
这个方法是Pattern类的工厂方法,用于将字符串形式的正则表达式编译为Pattern对象。 第二个参数flag是匹配模式,取值可以使用按位或运算符'|'表示同时生效,比如re.I | re.M。另外,你也可以在regex字符串中指定模式,比如re.compile('pattern', re.I | re.M)与re.compile('(?im)pattern')是等价的。
可选值有:
re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)
M(MULTILINE): 多行模式,改变'^'和'$'的行为(参见上图)
S(DOTALL): 点任意匹配模式,改变'.'的行为
L(LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定
U(UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性
X(VERBOSE): 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。
Match:Match对象是一次匹配的结果,包含了很多关于此次匹配的信息,可以使用Match提供的可读属性或方法来获取这些信息。
属性: