
LinkedHashMap 继承自 HashMap,在 HashMap 基础上,通过维护一条双向链表,解决了 HashMap 不能随时保持遍历顺序和插入顺序一致的问题。除此之外,LinkedHashMap 对访问顺序也提供了相关支持。在一些场景下,该特性很有用,比如缓存。在实现上,LinkedHashMap 很多方法直接继承自 HashMap,仅为维护双向链表覆写了部分方法。所以,要看懂 LinkedHashMap 的源码,需要先看懂 HashMap 的源码。关于 HashMap 的源码分析,本文并不打算展开讲了。大家可以参考我之前的一篇文章“HashMap 源码详细分析(JDK1.8)”。在那篇文章中,我配了十多张图帮助大家学习 HashMap 源码。
本篇文章的结构与我之前两篇关于 Java 集合类(集合框架)的源码分析文章不同,本文将不再分析集合类的基本操作(查找、遍历、插入、删除),而是把重点放在双向链表的维护上。包括链表的建立过程,删除节点的过程,以及访问顺序维护的过程等。好了,接下里开始分析吧。
2. 原理上一章说了 LinkedHashMap 继承自 HashMap,所以它的底层仍然是基于拉链式散列结构。该结构由数组和链表或红黑树组成,结构示意图大致如下:
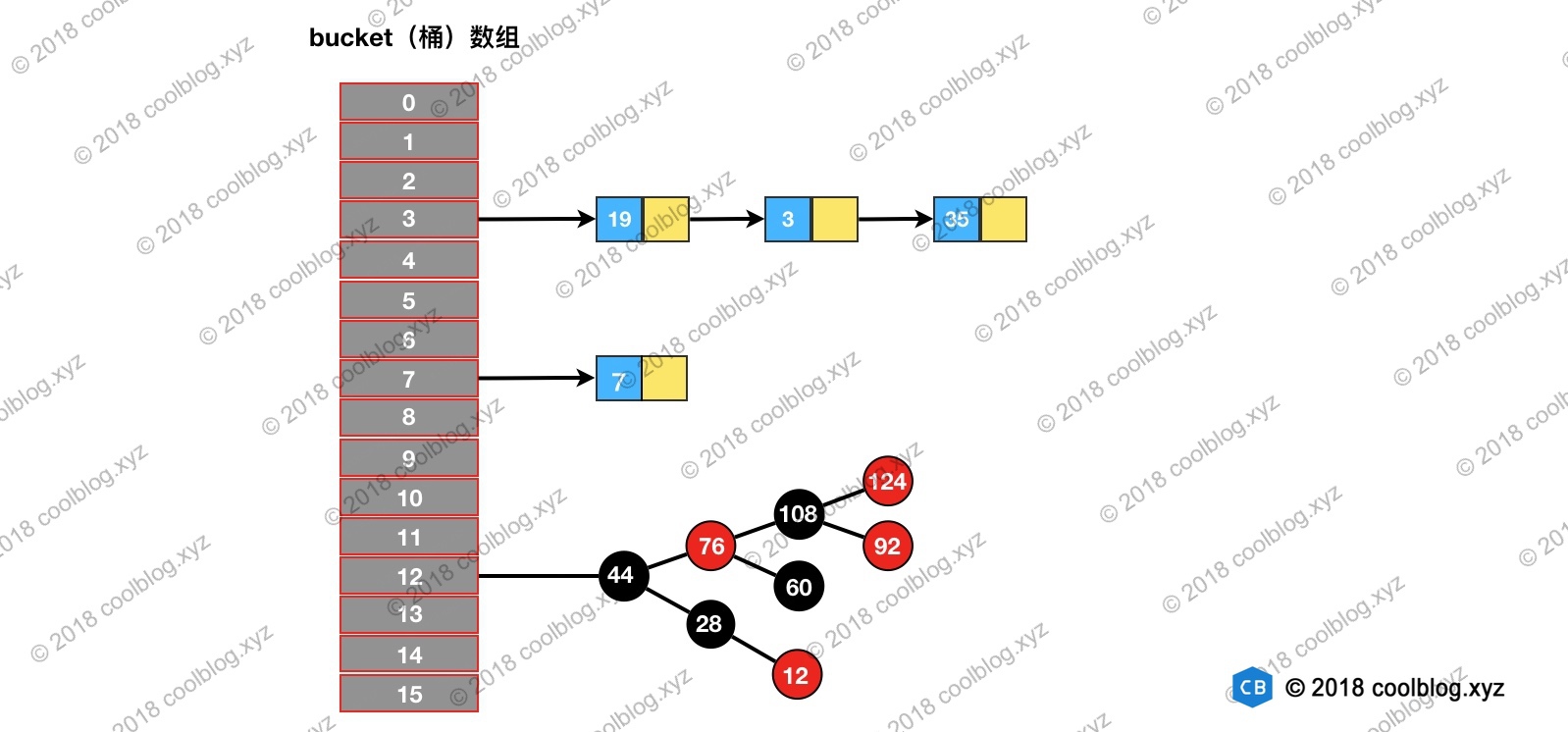
LinkedHashMap 在上面结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。同时通过对链表进行相应的操作,实现了访问顺序相关逻辑。其结构可能如下图:
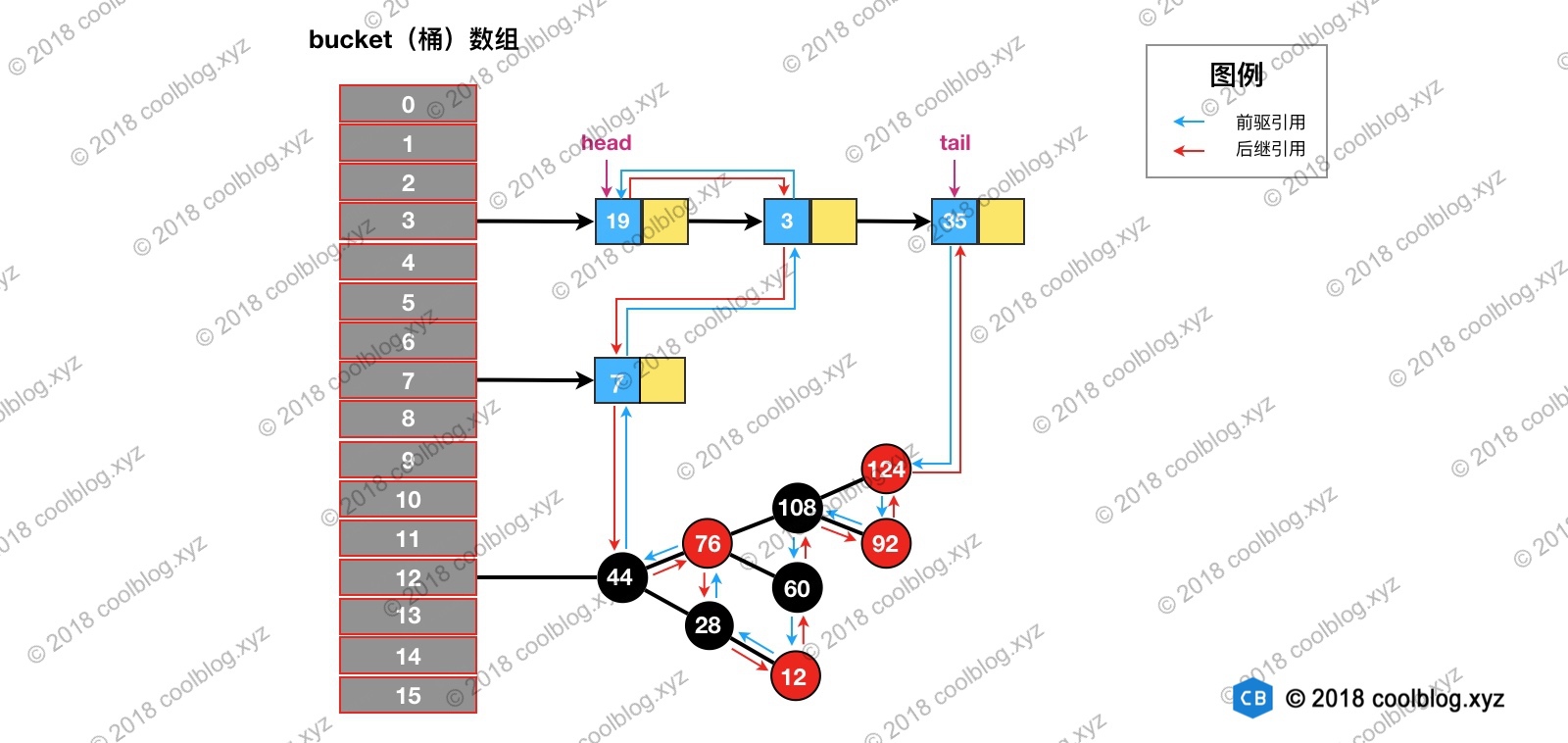
上图中,淡蓝色的箭头表示前驱引用,红色箭头表示后继引用。每当有新键值对节点插入,新节点最终会接在 tail 引用指向的节点后面。而 tail 引用则会移动到新的节点上,这样一个双向链表就建立起来了。
上面的结构并不是很难理解,虽然引入了红黑树,导致结构看起来略为复杂了一些。但大家完全可以忽略红黑树,而只关注链表结构本身。好了,接下来进入细节分析吧。
3. 源码分析 3.1 Entry 的继承体系在对核心内容展开分析之前,这里先插队分析一下键值对节点的继承体系。先来看看继承体系结构图:
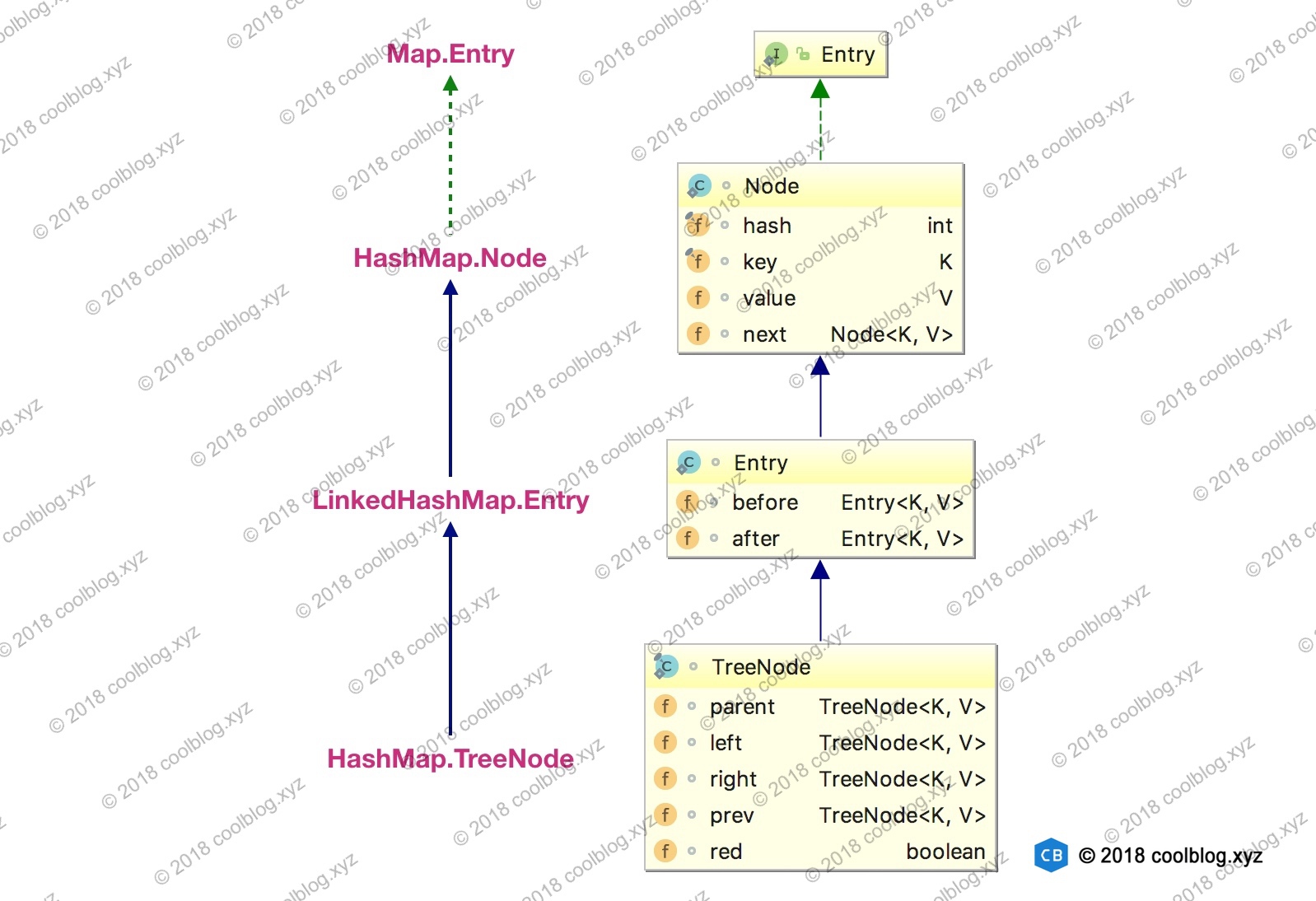
上面的继承体系乍一看还是有点复杂的,同时也有点让人迷惑。HashMap 的内部类 TreeNode 不继承它的了一个内部类 Node,却继承自 Node 的子类 LinkedHashMap 内部类 Entry。这里这样做是有一定原因的,这里先不说。先来简单说明一下上面的继承体系。LinkedHashMap 内部类 Entry 继承自 HashMap 内部类 Node,并新增了两个引用,分别是 before 和 after。这两个引用的用途不难理解,也就是用于维护双向链表。同时,TreeNode 继承 LinkedHashMap 的内部类 Entry 后,就具备了和其他 Entry 一起组成链表的能力。但是这里需要大家考虑一个问题。当我们使用 HashMap 时,TreeNode 并不需要具备组成链表能力。如果继承 LinkedHashMap 内部类 Entry ,TreeNode 就多了两个用不到的引用,这样做不是会浪费空间吗?简单说明一下这个问题(水平有限,不保证完全正确),这里这么做确实会浪费空间,但与 TreeNode 通过继承获取的组成链表的能力相比,这点浪费是值得的。在 HashMap 的设计思路注释中,有这样一段话:
Because TreeNodes are about twice the size of regular nodes, we
use them only when bins contain enough nodes to warrant use
(see TREEIFY_THRESHOLD). And when they become too small (due to
removal or resizing) they are converted back to plain bins. In
usages with well-distributed user hashCodes, tree bins are
rarely used.
大致的意思是 TreeNode 对象的大小约是普通 Node 对象的2倍,我们仅在桶(bin)中包含足够多的节点时再使用。当桶中的节点数量变少时(取决于删除和扩容),TreeNode 会被转成 Node。当用户实现的 hashCode 方法具有良好分布性时,树类型的桶将会很少被使用。
通过上面的注释,我们可以了解到。一般情况下,只要 hashCode 的实现不糟糕,Node 组成的链表很少会被转成由 TreeNode 组成的红黑树。也就是说 TreeNode 使用的并不多,浪费那点空间是可接受的。假如 TreeNode 机制继承自 Node 类,那么它要想具备组成链表的能力,就需要 Node 去继承 LinkedHashMap 的内部类 Entry。这个时候就得不偿失了,浪费很多空间去获取不一定用得到的能力。
说到这里,大家应该能明白节点类型的继承体系了。这里单独拿出来说一下,为下面的分析做铺垫。叙述略为啰嗦,见谅。
3.1 链表的建立过程链表的建立过程是在插入键值对节点时开始的,初始情况下,让 LinkedHashMap 的 head 和 tail 引用同时指向新节点,链表就算建立起来了。随后不断有新节点插入,通过将新节点接在 tail 引用指向节点的后面,即可实现链表的更新。