
实验七、数据挖掘之K-means聚类算法 一、实验目的 1. 理解K-means聚类算法的基本原理 2. 学会用python实现K-means算法 二、实验工具 1. Anaconda 2. sklearn 3. matplotlib 三、实验简介 1 K-means算法简介
k-means算法是一种聚类算法,所谓聚类,即根据相似性原则,将具有较高相似度的数据对象划分至同一类簇,将具有较高相异度的数据对象划分至不同类簇。聚类与分类最大的区别在于,聚类过程为无监督过程,即待处理数据对象没有任何先验知识,而分类过程为有监督过程,即存在有先验知识的训练数据集。
2 K-means算法原理k-means算法中的k代表类簇个数,means代表类簇内数据对象的均值(这种均值是一种对类簇中心的描述),因此,k-means算法又称为k-均值算法。k-means算法是一种基于划分的聚类算法,以距离作为数据对象间相似性度量的标准,即数据对象间的距离越小,则它们的相似性越高,则它们越有可能在同一个类簇。数据对象间距离的计算有很多种,k-means算法通常采用欧氏距离来计算数据对象间的距离
四、实验内容 1. 随机生成100个数,并对这100个数进行k-mean聚类(k=3,4,5,6)(并用matplot画图) 1) 随机创建100个样本的二维数据作为训练集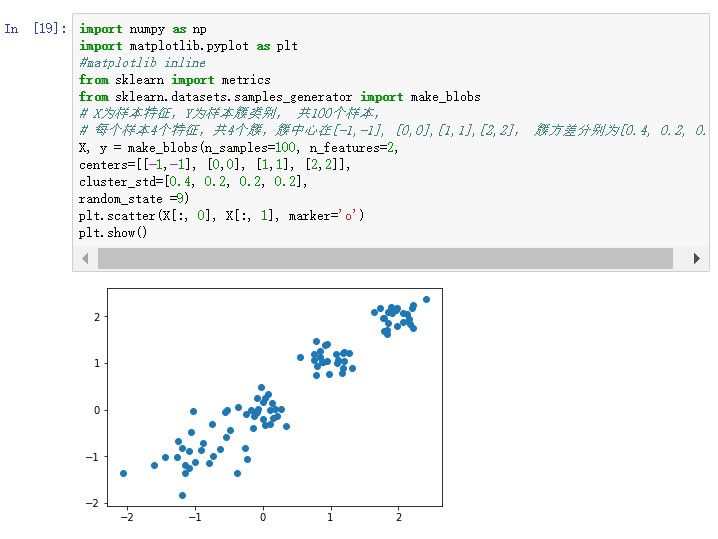
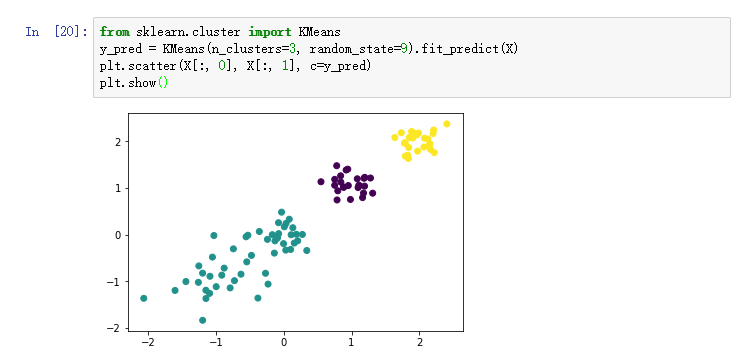
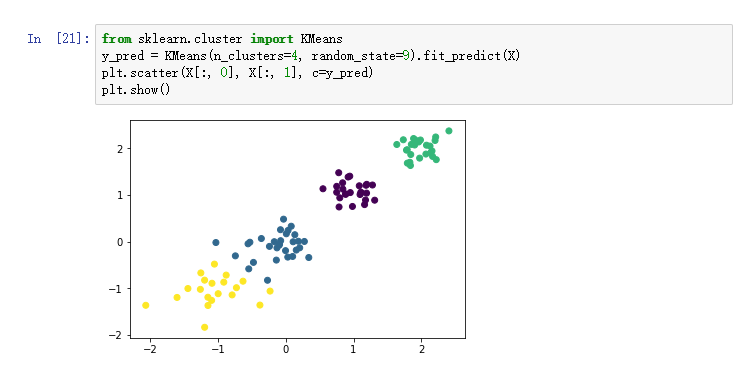
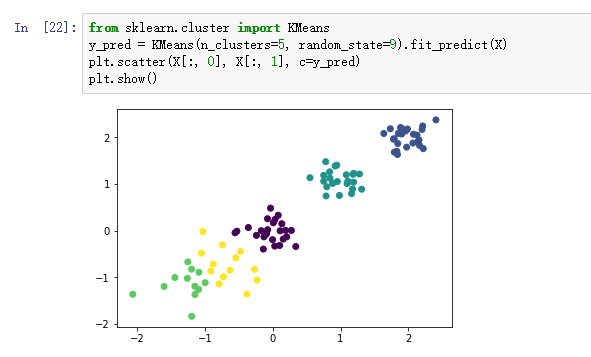

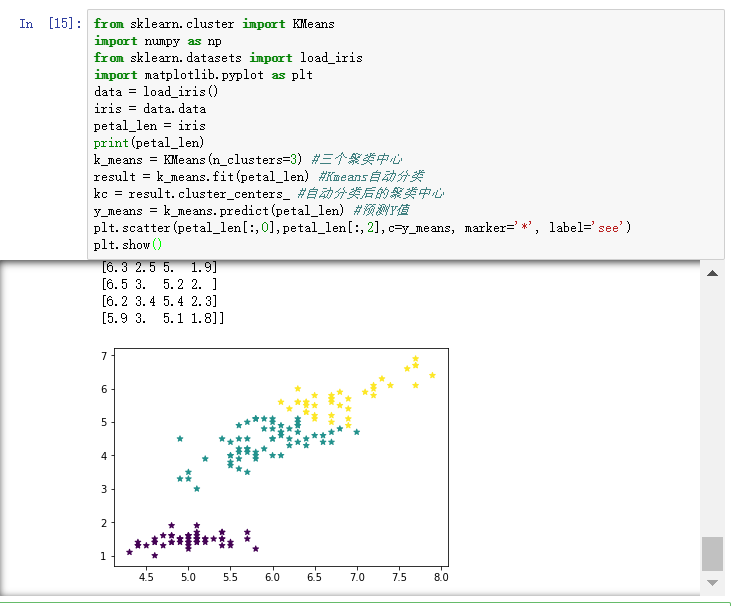
通过本次实验的学习与操作,我掌握了KMeans算法的基本原理,以及使用sklearn方便的进行聚类构造的方法。并且使用matplot画图,形象直观地看出了K=3,4,5时不同的簇分布情况。