
《Machine Learning in Action》—— 剖析支持向量机,优化SMO
薄雾浓云愁永昼,瑞脑销金兽。
愁的很,上次不是更新了一篇关于支持向量机的文章嘛,。虽然效果还算不错,数据集基本都能够分类正确,模型训练效率的话也还说的过去,但这是基于我们训练样本数据集比较少、迭代次数比较少的前提下。
假如说我们数据集比较大,而且还需要迭代不少次数的话,上一篇文章中使用到的SMO算法的效率可就不敢恭维了,训练的速度可堪比龟龟。月黑风高夜,杀人放火天。不对不对,月黑风高夜,疯狂肝文时。既然一般的SMO算法的效率低下,那怎么说也得进一步优化才行呐。
就在前几天还听见收音机上说,国内外有许多如雷贯耳的大佬都在不断研究新算法来进一步提高SMO算法的训练效率。闻此一言,Taoye心中大喜:"如果我能蹦跶出一个新的优化算法,哥哥我声名远扬的大好机会就来了啊,雄霸天下的抱负就指日可待了啊!哈哈哈哈!!!"想法虽好,可是该怎么优化呢?在这薄雾浓云、月黑风高之夜,Taoye的思绪漫天飞,愁的很。
有心栽花花不开,无心插柳柳成荫。
明明已经知道SMO算法待优化的地方太多了,可是就是不知如何下手,想了老半天,脑阔疼的厉害。此刻实验室空无一人,Taoye转着座椅,双目望向窗外,皎洁的月光总是给人无限遐想。
罢了罢了,与其木讷在这有心栽花花不开,倒不如出去转悠转悠,说不定能捕获个意想不到的收获,给我来了无心插柳柳成荫呢?说走咱就走哇(调调有点不对劲~~),关上空调,披件外套,锁上室门,双手插袋朝外走去。
或许是空调吹太久了,亦或实验室呆太久了,出来的瞬间一股神清气爽的感觉涌上心头,五音不全的我此时还真想高歌一曲。顷之,微凉,好在出门前披了件外套。活动活动筋骨,朝湖边走去。走着走着,不知不觉来到了步行桥,风平浪静的湖面,没有一丝波纹荡起。左转,低头看着湖面中胡子拉碴且憔悴的自己,此时我的眼角又再一次。。。┭┮﹏┭┮ 。。抬头看着湖边零星几对小情侣,或有说有笑、或呢喃窃语、或打情骂俏,滋滋滋,有点儿意思,只有我只身一人还在想着如何优化SMO算法。
等会儿。。。小情侣???优化SMO???
我记得在前面那篇文章中写到的SMO算法的核心思想里,正是不断迭代成双成对的\(\alpha_i\)和\(\alpha_j\),只不过那个时候的这对“小情侣”是随意配对,所以导致的排列组合的可能性太多,从而拉低了整个模型训练的效率。假如说,我那个时候选取这对“小情侣”的时候并不是无意的,而是有意识、有条件的去选取,不就可以避开大量没必要的可能性计算么,这样一来不就可以大大提高模型的训练效率了么???
握了一棵草,乖乖,我真是个天才,这都被我想到了???心头灵光一闪,犹如饥渴春笋听到的第一声惊雷,屁颠屁颠的朝实验室跑去,而一对对小情侣异样且诧异的眼神朝我看来。。。
上述内容部分虚构,仅做引出下文之用。
在这之前,我们先静下心来分析一下上篇文章中SMO的核心算法:
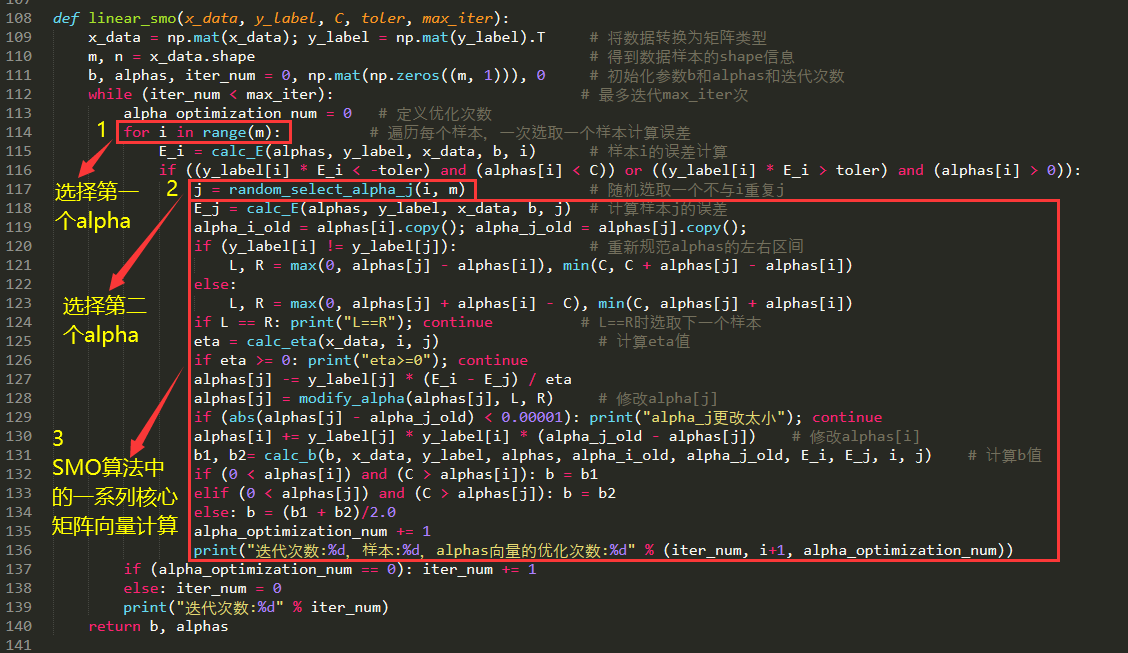
上图是我们在讲解手撕线性SVM中所写到的linear_smo方法,详细请看:。其中Taoye圈出了三个代码块来给大家介绍下:
第一个代码块,我们可以发现代码行为for i in range(m):,想必大家都知道这是一个循环语句,在这个方法中它具体表达的意思是根据样本数量一次选取索引\(i\),然后通过这个索引来确定\(\alpha_i\)的选择,所以它最终会把所有的样本都“走一遍”。
第二个代码块,是根据\(i\)的值重新在\(m\)中选取一个不与\(i\)相同的\(j\),然后根据这个\(j\)来修改对应的\(\alpha_j\)
第三个就是我们大量的矩阵、向量进行计算的代码块了,我们可以发现,无论前两个\(i、j\)的选取是怎样的,第三个代码块都会去执行、计算,然而有些计算完全是没必要的,这样就大大拉跨了整个SMO算法的效率,这可不是我们想要的。
综上,我们需要在\(\alpha\)的选取上做点文章,使其在一定的跳过第三个代码块的计算。
第一个\(\alpha_i\)的选取
在上一篇文章中,我们也有提到,大多数样本对于决策面的确定都是无用的,只有少数部分的样本点才能确定具体的决策面。而\(\alpha\)与样本之间满足如下关系: