
但是他有一个缺点,alpine 上并没有 glibc 库,他所使用的是一个 musl libc 的小体积替代版,但是 Java 是必须依赖的 glibc 的,不过早就有大神了解了这点,在 GitHub 上已经提供了预编译的 glibc 库,名字为alpine-pkg-glibc,装上这个库就可以完美支持 Java,同时还能够保持体积很小。
Rancher 的高可用性安装 Rancher 的方式有两种:单节点安装和高可用集群安装。一般单节点安装仅适用于测试或者 demo 环境,所以要正式投入使用的话,还是推荐高可用集群的安装方式。
我们一开始测试环境就使用了单节点安装的方式,后来因为 Rancher Server 那台机器出现过一次重启,就导致了测试环境故障,虽然备份了,但是还是丢失了少量数据,最后我们测试环境也采用了 HA 高可用部署,整个架构如下图所示。
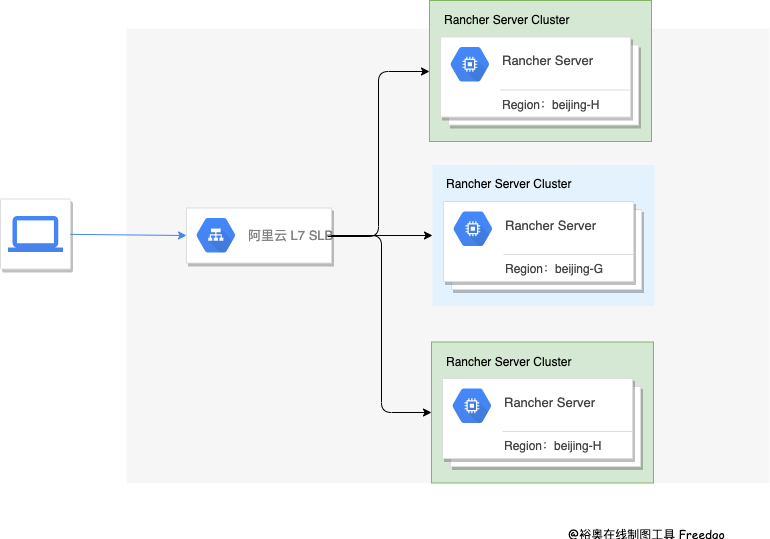
Rancher Server 我是采用的 RKE 安装,并且为了防止阿里云出现区域性的故障,我们将 Rancher Server 的三台机器,部署在了两个可用区,Rancher Server-001、003 在北京的 H 区、Rancher Server-002 在北京的 G 区。
负载均衡,我们采用的是阿里云的 SLB,也是采购的主备型实例,防止单点故障,因为 Rancher 必须使用 SSL 证书,我们也有自己的域名证书,为了方便在 SLB 上进行 SSL 证书的维护,我们使用的是 7 层协议,在 SLB 上做的 SSL 终止,Rancher Server 的架构图可以参考下图:
下游集群,也就是用来承载业务的 K8s 集群,我们也是一半一半,在阿里云的两个可用区进行部署的,需要注意的是,为了保证两个区的网络时延 <= 15 ms,这就完成了一个高可用的灾备架构。
备份方面,我们也使用了阿里云 ECS 快照 + ETCD S3 协议备份到了阿里云的 OSS 对象存储两种方案,确保出现故障后,能够及时恢复服务。
部署的详细教程可以参考 Rancher 官方文档。
容器的运维容器的运维,这里主要指容器的日志收集和容器监控,容器监控方面呢,Rancher 自带了 Prometheus 和 Grafana,而且和 Rancher 的 UI 有一些整合,就非常的方便,所以监控方面我就不展开讲了,我主要说一说日志收集。
在 K8s 里,日志的收集相比传统的物理机、虚机等方式要复杂一些,因为 K8s 所提供的是动态的环境,像绑定 hostpath 这种方式是不适用的,我们可以通过以下这个表格直观的对比一下:

可以看到,K8s 需要采集的日志种类比较多,而容器化的部署方式,在单机器内的应用数是很高的,而且都是动态的,所以传统的采集方式是不适用于 K8s 的。
目前 K8s 的采集方式大体可以分为两种,被动采集和主动推送。
主动推送一般有 DockerEngine 和 业务直写两种方式:DockerEngine 是 Docker 的 LogDriver 原生自带的,一般只能收集 STDOUT、一般不建议使用;而业务直写,则需要在应用里集成日志收集的 SDK,通过 SDK 直接发送到收集端,日志不需要落盘,也不需要部署Agent,但是业务会和 SDK 强绑定,灵活性偏低,建议对于日志量较大,或者对日志有定制化要求的场景使用。