
MySQL多版本并发控制机制(MVCC)-源码浅析 前言
作为一个数据库爱好者,自己动手写过简单的SQL解析器以及存储引擎,但感觉还是不够过瘾。<<事务处理-概念与技术>>诚然讲的非常透彻,但只能提纲挈领,不能让你玩转某个真正的数据库。感谢cmake,能够让我在mac上用xcode去debug MySQL,从而能去领略它的各种实现细节。
笔者一直对数据库的隔离性很好奇,此篇博客就是我debug MySQL过程中的偶有所得。
(注:本文的MySQL采用的是MySQL-5.6.35版本)
隔离性也可以被称作并发控制、可串行化等。谈到并发控制首先想到的就是锁,MySQL通过使用两阶段锁的方式实现了更新的可串行化,同时为了加速查询性能,采用了MVCC(Multi Version Concurrency Control)的机制,使得不用锁也可以获取一致性的版本。
Repeatable ReadMySQL的通过MVCC以及(Next-Key Lock)实现了可重复读(Repeatable Read),其思想(MVCC)就是记录数据的版本变迁,通过精巧的选择不同数据的版本从而能够对用户呈现一致的结果。如下图所示:
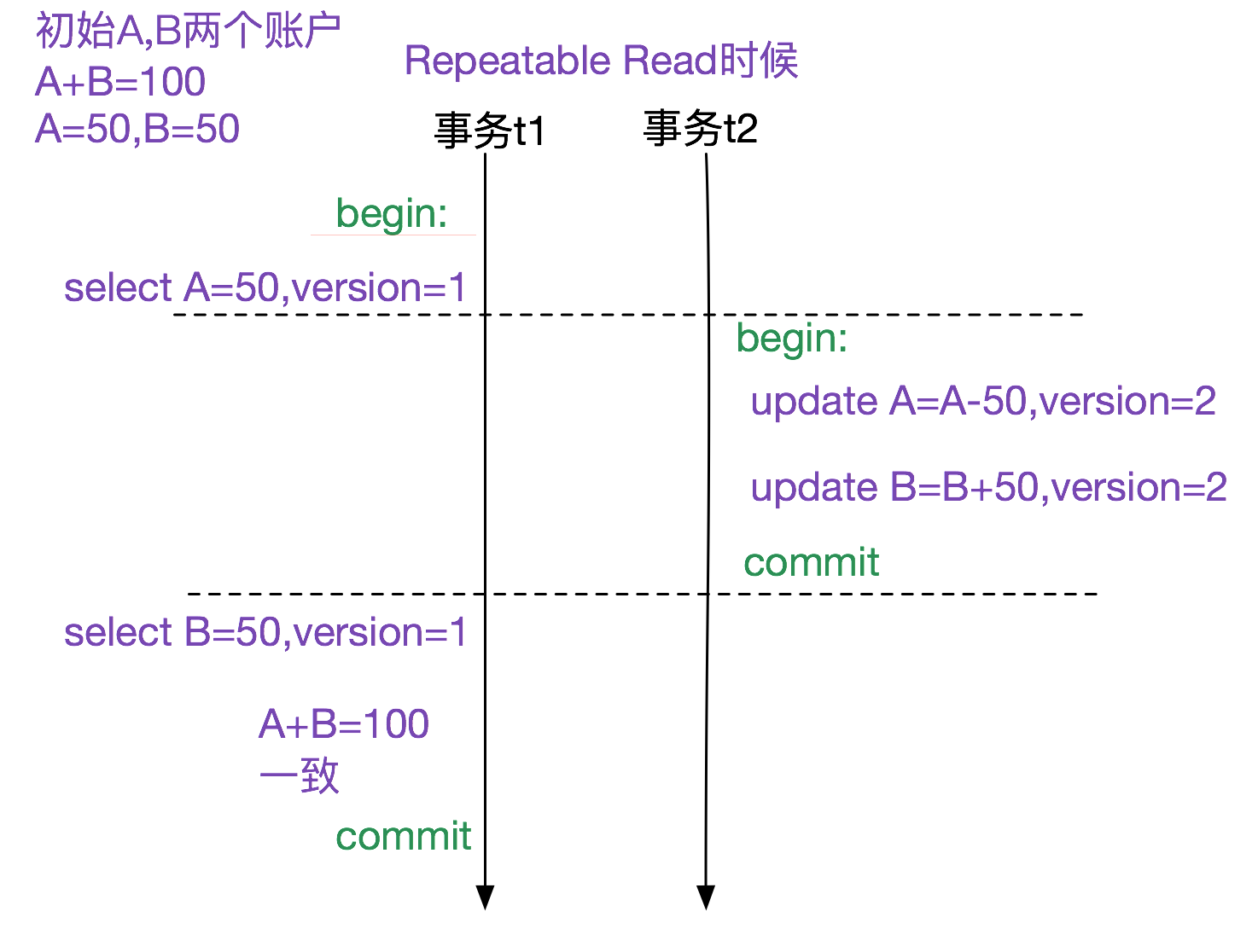
上图中,(A=50|B=50)的初始版本为1。
1.事务t1在select A时候看到的版本为1,即A=50
2.事务t2对A和B的修改将版本升级为2,即A=0,B=100
3.事务t1再此select B的时候看到的版本还是1, 即B=50
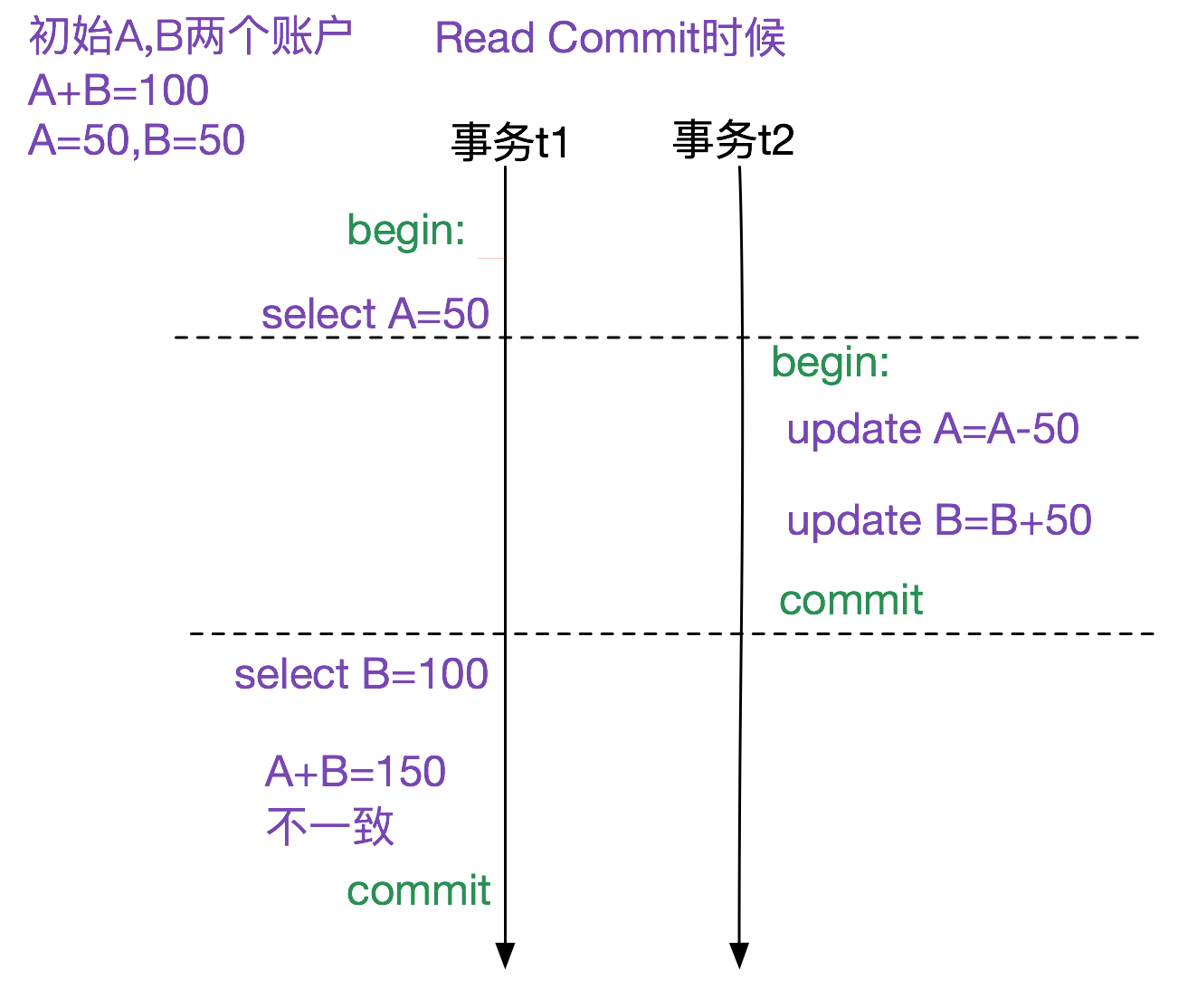
这样就隔离了版本的影响,A+B始终为100。 Read Commit
而如果不通过版本控制机制,而是读到最近提交的结果的话,则隔离级别是read commit,如下图所示:
在这种情况下,就需要使用锁机制(例如select for update)将此A,B记录锁住,从而获得正确的一致结果,如下图所示:
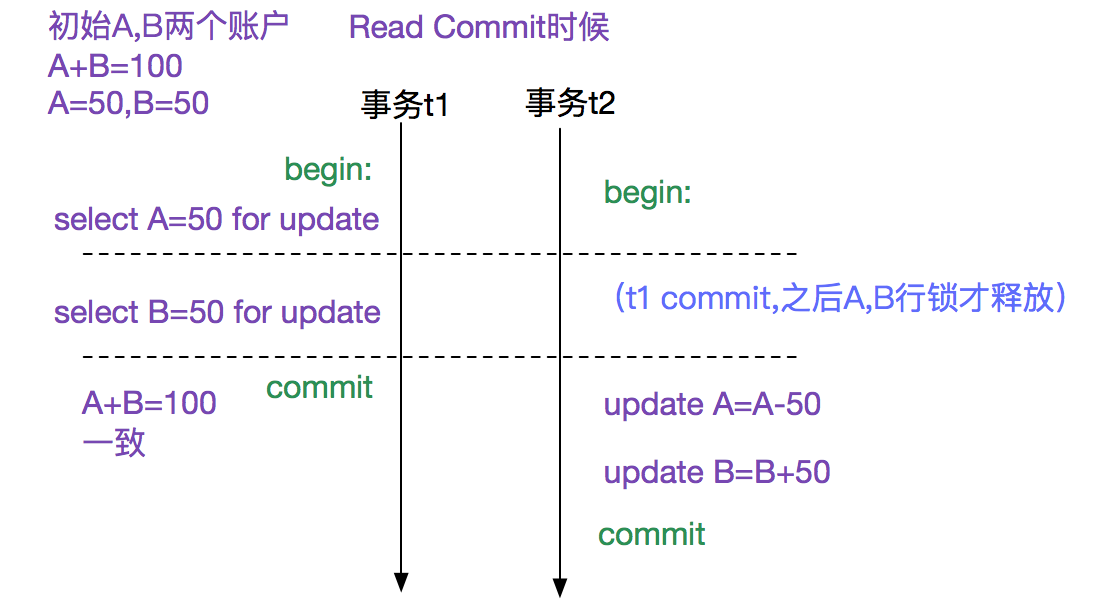
当我们要对一些数据做一些只读操作来检查一致性,例如检查账务是否对齐的操作时候,并不希望加上对性能损耗很大的锁。这时候MVCC的一致性版本就有很大的优势了。
MVCC(实现机制)本节就开始谈谈MVCC的实现机制,注意MVCC仅仅在纯select时有效(不包括select for update,lock in share mode等加锁操作,以及update\insert等)。
select运行栈首先我们追踪一下一条普通的查询sql在mysql源码中的运行过程,sql为(select * from test);

其运行栈为: handle_one_connection MySQL的网络模型是one request one thread |-do_handle_one_connection |-do_command |-dispatch_command |-mysql_parse 解析SQL |-mysql_execute_command |-execute_sqlcom_select 执行select语句 |-handle_select ...一堆parse join 等的操作,当前并不关心 |-*tab->read_record.read_record 读取记录
由于mysql默认隔离级别是repeatable_read(RR),所以read_record重载为
rr_sequential(当前我们并不关心select通过index扫描出row之后再通过condition过滤的过程)。继续追踪:
让我们看下该函数内部:
bool lock_clust_rec_cons_read_sees(const rec_t* rec /*由innodb扫描出来的一行*/,....){ ... // 从当前扫描的行中获取其最后修改的版本trx_id(事务id) trx_id = row_get_rec_trx_id(rec, index, offsets); // 通过参数(一致性快照视图和事务id)决定看到的行快照 return(read_view_sees_trx_id(view, trx_id)); } read_view的创建过程我们先关注一致性视图的创建过程,我们先看下read_view结构:
struct read_view_t{ // 由于是逆序排列,所以low/up有所颠倒 // 能看到当前行版本的高水位标识,>= low_limit_id皆不能看见 trx_id_t low_limit_id; // 能看到当前行版本的低水位标识,< up_limit_id皆能看见 trx_id_t up_limit_id; // 当前活跃事务(即未提交的事务)的数量 ulint n_trx_ids; // 以逆序排列的当前获取活跃事务id的数组 // 其up_limit_id<tx_id<low_limit_id trx_id_t* trx_ids; // 创建当前视图的事务id trx_id_t creator_trx_id; // 事务系统中的一致性视图链表 UT_LIST_NODE_T(read_view_t) view_list; };然后通过debug,发现创建read_view结构也是在上述的rr_sequential中操作的,继续跟踪调用栈:
rr_sequential |-ha_rnd_next |-rnd_next |-index_first 在start_of_scan为true时候走当前分支index_first |-index_read |-row_search_for_mysql |-trx_assign_read_view我们看下row_search_for_mysql里的一个分支:
row_search_for_mysql: // 这边只有select不加锁模式的时候才会创建一致性视图 else if (prebuilt->select_lock_type == LOCK_NONE) { // 创建一致性视图 trx_assign_read_view(trx); prebuilt->sql_stat_start = FALSE; }