
GFS Master 我们姑且认为是古代的皇上,统筹全局,运筹帷幄。主要负责掌控管理所有文件系统的元数据,包括文件和块的命名空间、从文件到块的映射、每个块所在的节点位置。说白了,就是要维护哪个文件存在哪些文件服务器上的元数据信息,并且定期通过心跳机制与每一个 GFS Chunkserver 通信,向其发送指令并收集其状态。
GFS Chunkserver 可以认为是宰相,因为宰相肚子里面能撑船,能够海纳百川。主要提供数据块的存储服务,以文件的形式存储于 Chunkserver 上。
GFS Client 可以认为是使者,对外提供一套类似传统文件系统的 API 接口,对内主要通过与皇帝通信来获取元数据,然后直接和宰相交互,来进行所有的数据操作。
为了让大家对 GFS 背后的读写流程有更多认识,献上两首歌谣。

到这里,大家应该对分布式文件系统 GFS 不再陌生,以后在饭桌上讨论该话题时,也能与朋友交涉两嗓子啦。
不过这还只是了解了海量数据怎么存储,那如何从海量数据存储中,快速计算出我们想要的结果呢?

面对海量数据的计算,谷歌再次创新,推出了 MapReduce 编程模型及实现。
MapReduce 主要是采取分而治之的思想,通俗地讲,主要是将一个大规模的问题,分成多个小规模的问题,把多个小规模问题解决,然后再合并小规模问题的结果,就能够解决大规模的问题。
也有人说 MapReduce 就像光头强的锯子和锤子,世界上的万事万物都可以先锯几下,然后再锤几下,就能轻松搞定,至于锯子怎么锯,锤子怎么锤,那就是个人的手艺了。
这么解释不免显得枯燥乏味,我们不妨换种方式,走进生活真实感受 MapReduce。

斗地主估计大家都玩过,每次开玩之前,都会统计一副牌的张数到底够不够,最快的步骤莫过于:分几份给大家一起数,最后大家把数累加,算总张数,接着就可以愉快地玩耍啦... ...这不就是分而治之的思想吗?!不得不说架构思想来源于人们的生活!
再举个不太贴切的例子来感受MapReduce 背后的运转流程,估计很多人掰过玉米,每当玉米成熟的季节,地主家就开始忙碌起来。
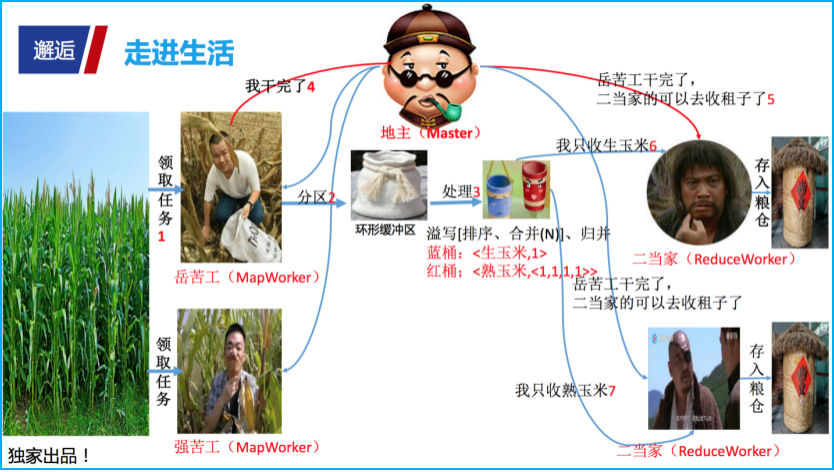
首先地主将一亩地的玉米分给处于空闲状态的长工来处理;专门负责掰玉米的长工领取任务,开始掰玉米操作(Map 操作),并把掰好的玉米放到在麻袋里(缓冲区),麻袋装不下时,会被装到木桶中(溢写),木桶被划分为蓝色的生玉米木桶、红色的熟玉米木桶(分区),地主通知二当家来“收”属于自己的那部分玉米,二当家收到地主的通知后,就到相应的长工那儿“拿回”属于自己的那部分玉米(Fetch 操作),二当家对收取的玉米进行处理(Reduce 操作),并把处理后的结果放入粮仓。
一个不太贴切的生活体验 + 一张画得不太对的丑图 = 苦涩难懂的技术,也不知道这样解释,你了解了多少?不过如果以后再谈大数据,知道 MapReduce 这个词的存在,那这次的分享就算成功(哈哈)。
MapReduce 解决了海量数据的计算问题,可谓是力作,但谷歌新的业务需求一直在不断出现。众所周知,谷歌要存储爬取的海量网页,由于网页会不断更新,所以要不断地针对同一个 URL 进行爬取,那么就需要能够存储一个 URL 不同时期的多个版本的网页内容。谷歌面临很多诸如此类的业务场景,面对此类头痛的需求,该怎么办?
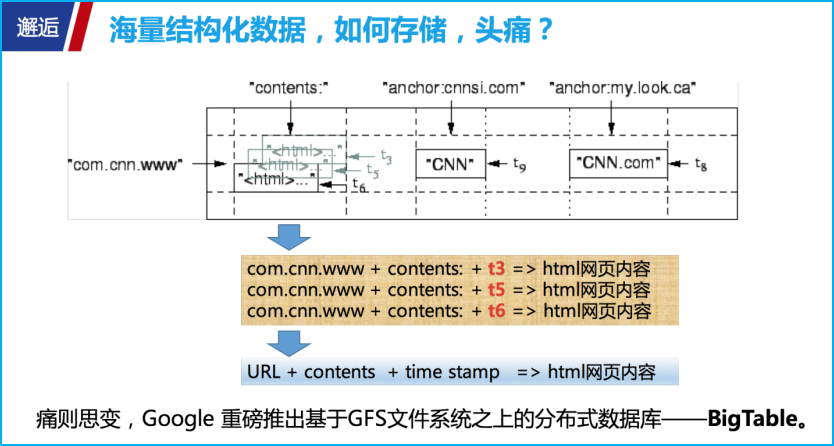
谷歌重磅打造了一款类似以“URL + contents + time stamp”为 key,以“html 网页内容”为值的存储系统,于是就有了 BigTable 这个键值系统的存在(本文不展开详述)。
