谷歌三驾马车如何解决海量数据存储与计算问题。
我是我:“缘起于美丽,相识于邂逅,厮守到白头!”
众听众:“呃,难道今天是要分享如何作诗?!”
我是我:“大家不要误会,今天主要的分享不是如何作诗,而是《揭秘:‘撩’大数据的正确姿势》,下面进入正题。”
话说当下技术圈的朋友,一起聚个会聊个天,如果不会点大数据的知识,感觉都融入不了圈子,为了以后聚会时让你有聊有料,接下来就跟随我的讲述,一起与大数据混个脸熟吧,不过在“撩”大数据之前,还是先揭秘一下研发这些年我们都经历了啥?
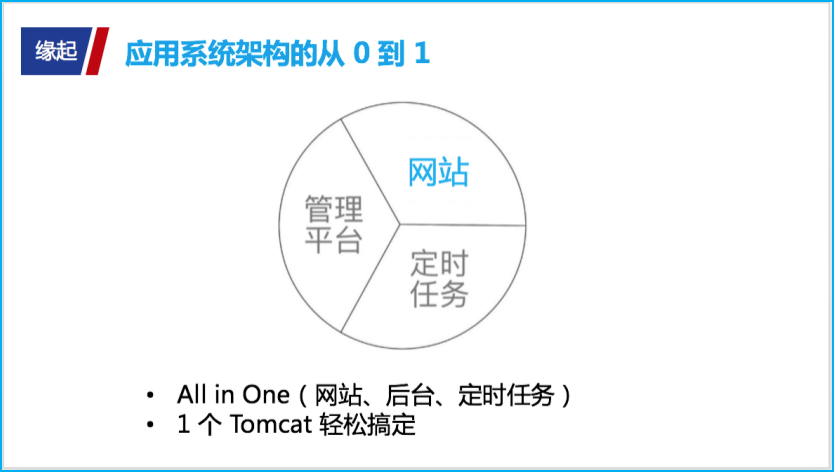
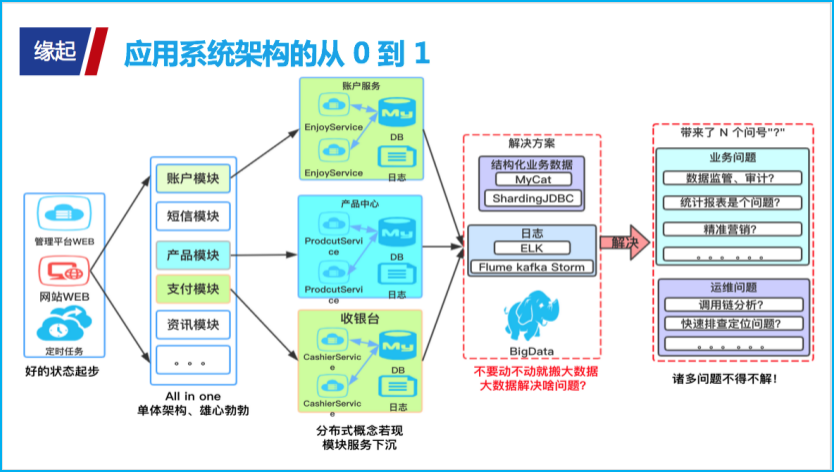
缘起:应用系统架构的从 0 到 1 揭秘:研发这些年我们都经历了啥?大道至简。生活在技术圈里,大家静下来想想,无论一个应用系统多庞大、多复杂,无非也就是由一个漂亮的网站门面 + 一个丑陋的管理模块 + 一个闷头干活的定时任务三大板块组成。
我们负责的应用系统当然也不例外,起初设计的时候三大模块绑在一起(All in one),线上跑一个 Tomcat 轻松就搞定,可谓是像极了一个大泥球。
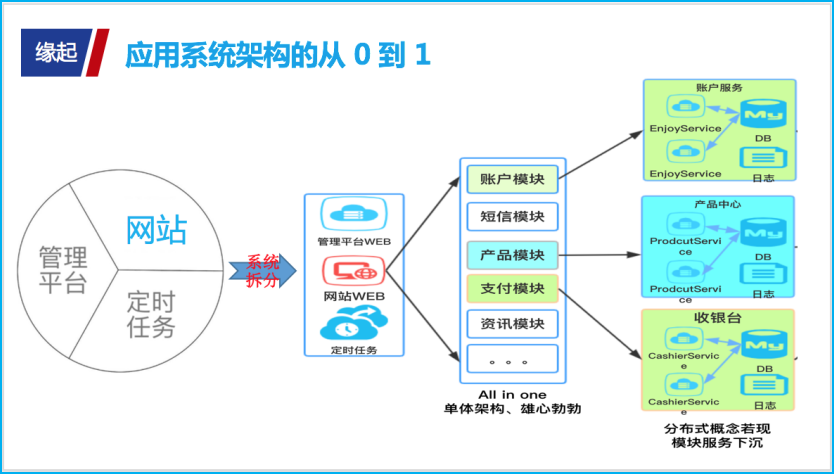
衍化至繁。由于网站模块、管理平台、定时任务三大模块绑定在一起,开发协作会比较麻烦,时不时会有代码合并冲突出现;线上应用升级时,也会导致其它模块暂时不能使用,例如如果修改了一个定时任务的配置,可能会导致网站、管理平台的服务暂时不能用。面对诸多的不便,就不得不对 All in one 的大泥球系统进行拆解。

随着产品需求的快速迭代,网站 WEB 功能逐渐增多,我们起初设计时雄心勃勃(All in one 的单体架构),以为直接按模块设计叠加实现就好了,谁成想系统越发显得臃肿(想想也是走弯路啦!)。所以不得不改变实现思路,让模块服务下沉,分布式思想若现——让原来网站 WEB 一个系统做的事,变成由子系统分担去完成。
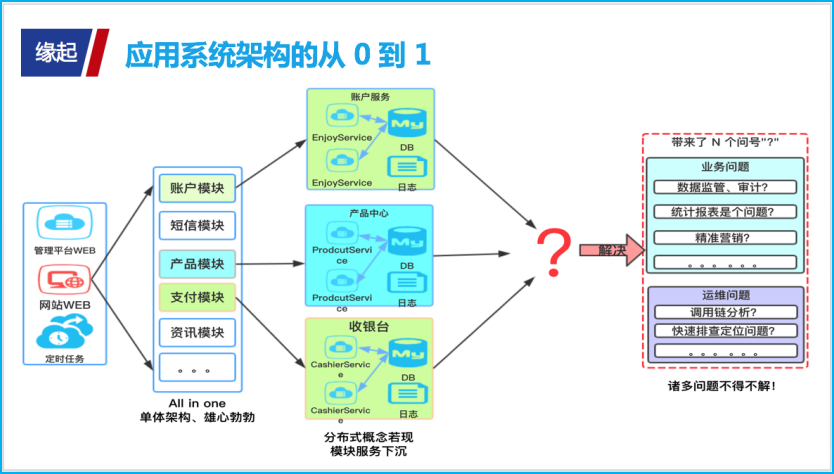
应用架构的演变,服务模块化拆分,随之而来的就是业务日志、业务数据散落在各处。随着业务的推广,业务量逐日增多,沉淀的数据日益庞大,在业务层面、运维层面上的很多问题,逐渐开始暴露。
在业务层面上,面对监管机构的监管,整合提取散落在各地的海量数据稍显困难;海量数据散落,想做个统计分析报表也非常不易。
在运维层面上,由于缺少统一的日志归档,想基于日志做快速分析也比较困难;如果想从散落在各模块的日志中,进行调用链路的分析也是相当费劲。
面对上述问题,此时一个硕大的红色问号出现在我们面前,到底该如何解决?
面对结构化的业务数据,不妨先考虑采用国内比较成熟的开源数据库中间件 Sharding-JDBC、MyCat 看是否能够解决业务问题;面对日志数据,可以考虑采用 ELK 等开源组件。如果以上方案或者能尝试的方式都无法帮我们解决,尝试搬出大数据吧。
那到底什么时候需要用大数据呢?大数据到底能帮我们解决什么问题呢?注意,前方高能预警,门外汉“撩”大数据的正确姿势即将开启。
邂逅:一起撬开大数据之门 槽点:门外汉“撩”大数据的正确姿势与大数据的邂逅,源于两个头痛的问题。第一个问题是海量数据的存储,如何解决?第二个问题是海量数据的计算,如何解决?

面对这两个头痛的问题,不得不提及谷歌的“三驾马车”(分布式文件系统 GFS、MapReduce 和 BigTable),谷歌“三驾马车”的出现,奠定了大数据发展的基石,毫不夸张地说,没有谷歌的“三驾马车”就没有大数据,所以接下来很有必要逐一认识。
大家都知道,谷歌搜索引擎每天要抓取数以亿计的网页,那么抓取的海量数据该怎么存储?
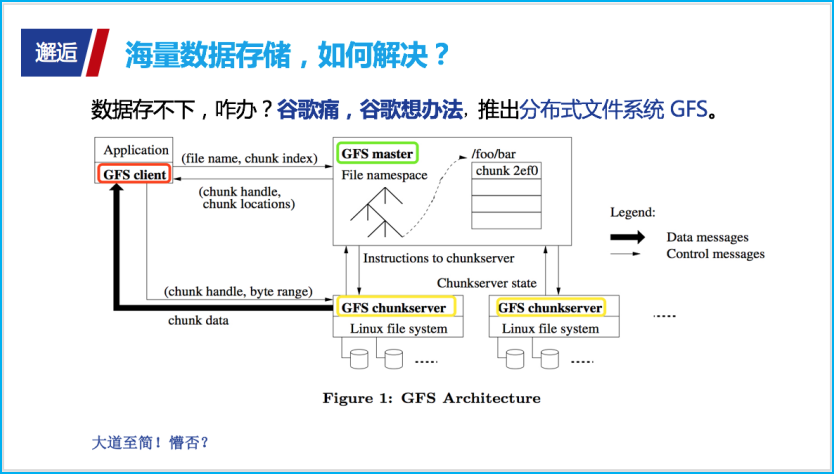
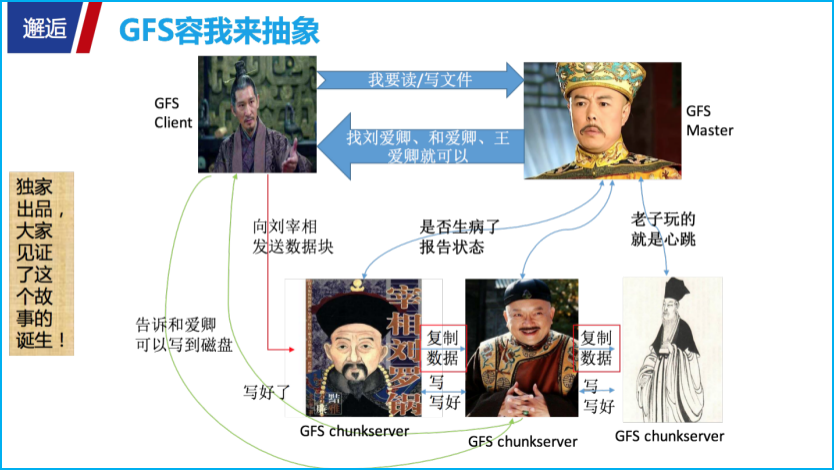
谷歌痛则思变,重磅推出分布式文件系统 GFS。面对谷歌推出的分布式文件系统 GFS 架构,如 PPT 中示意,参与角色着实很简单,主要分为 GFS Master(主服务器)、GFS Chunkserver(块存储服务器)、GFS Client(客户端)。
不过对于首次接触这个的你,可能还是一脸懵 ,大家心莫慌,接下来容我抽象一下。