
2.连接查询和连接条件
3.谓词下推
4.内连接查询中的谓词下推规则
4.1.Join后条件通过AND连接
4.2.Join后条件通过OR连接
4.3.分区表使用OR连接过滤条件
1.SparkSqlSparkSql 是架构在 Spark 计算框架之上的分布式 Sql 引擎,使用 DataFrame 和 DataSet 承载结构化和半结构化数据来实现数据复杂查询处理,提供的 DSL可以直接使用 scala 语言完成 Sql 查询,同时也使用 thriftserver 提供服务化的 Sql 查询功能。
SparkSql 提供了 DataSource API ,用户通过这套 API 可以自己开发一套 Connector,直接查询各类数据源,数据源包括 NoSql、RDBMS、搜索引擎以及 HDFS 等分布式文件系统上的文件等。和 SparkSql 类似的系统有 Hive、PrestoDB 以及 Impala,这类系统都属于所谓的" Sql on Hadoop "系统,每个都相当火爆,毕竟在这个不搞 SQL 就是耍流氓的年代,没 SQL 确实很难找到用户使用。
2.连接查询和连接条件Sql中的连接查询(join),主要分为内连接查询(inner join)、外连接查询(outter join)和半连接查询(semi join),具体的区别可以参考wiki的解释。
连接条件(join condition),则是指当这个条件满足时两表的两行数据才能"join"在一起被返回,例如有如下查询:

其中的"LT.id=RT.idAND LT.id>1"这部分条件被称为"join中条件",直接用来判断被join的两表的两行记录能否被join在一起,如果不满足这个条件,两表的这两行记录并非全部被踢出局,而是根据连接查询类型的不同有不同的处理,所以这并非一个单表的过滤过程或者两个表的的“联合过滤”过程;而where后的"RT.id>2"这部分被称为"join后条件",这里虽然成为"join后条件",但是并非一定要在join后才能去过滤数据,只是说明如果在join后进行过滤,肯定可以得到一个正确的结果,这也是我们后边分析问题时得到正确结果的基准方法。
3.谓词下推所谓谓词(predicate),英文定义是这样的:A predicate is a function that returns bool (or something that can be implicitly converted to bool),也就是返回值是true或者false的函数,使用过scala或者spark的同学都知道有个filter方法,这个高阶函数传入的参数就是一个返回true或者false的函数。大数据技术答疑扣扣群:606加+【八五九】+705,无论你是初学者小白还是大牛都欢迎,资料分享一起学习进步。
但是如果是在sql语言中,没有方法,只有表达式。where后边的表达式起的作用正是过滤的作用,而这部分语句被sql层解析处理后,在数据库内部正是以谓词的形式呈现的。
那么问题来了,谓词为什么要下推呢? SparkSql中的谓词下推有两层含义,第一层含义是指由谁来完成数据过滤,第二层含义是指何时完成数据过滤。要解答这两个问题我们需要了解SparkSql的Sql语句处理逻辑,大致可以把SparkSql中的查询处理流程做如下的划分:
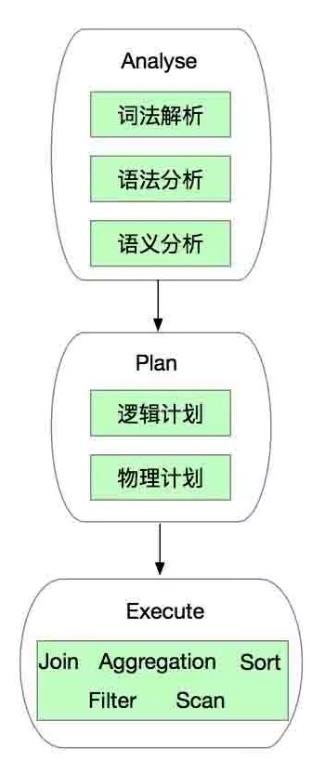
SparkSql首先会对输入的Sql语句进行一系列的分析(Analyse),包括词法解析(可以理解为搜索引擎中的分词这个过程)、语法分析以及语义分析(例如判断database或者table是否存在、group by必须和聚合函数结合等规则);之后是执行计划的生成,包括逻辑计划和物理计划。其中在逻辑计划阶段会有很多的优化,对谓词的处理就在这个阶段完成;而物理计划则是RDD的DAG图的生成过程;这两步完成之后则是具体的执行了(也就是各种重量级的计算逻辑,例如join、groupby、filter以及distinct等),这就会有各种物理操作符(RDD的Transformation)的乱入。
能够完成数据过滤的主体有两个,第一是分布式Sql层(在execute阶段),第二个是数据源。那么谓词下推的第一层含义就是指由Sql层的Filter操作符来完成过滤,还是由Scan操作符在扫描阶段完成过滤。
上边提到,我们可以通过封装SparkSql的Data Source API完成各类数据源的查询,那么如果底层数据源无法高效完成数据的过滤,就会执行全局扫描,把每条相关的数据都交给SparkSql的Filter操作符完成过滤,虽然SparkSql使用的Code Generation技术极大的提高了数据过滤的效率,但是这个过程无法避免大量数据的磁盘读取,甚至在某些情况下会涉及网络IO(例如数据非本地化存储时);如果底层数据源在进行扫描时能非常快速的完成数据的过滤,那么就会把过滤交给底层数据源来完成(至于哪些数据源能高效完成数据的过滤以及SparkSql又是如何完成高效数据过滤的则不是本文讨论的重点,会在其他系列的文章中介绍)。