
问了下DBA,他们不会kill -9所有进程,都是按照标准的数据库重启流程来操作的。kill -9所有进程的同时并关闭这些进程所拥有的连接。
如果我们使用的商业数据库用了上图的机制,那就会造成前面的现象。但是由于DB本身保持的session都已经没了,那么这个连接在数据库维度肯定是已经gg了(这也是数据库统计不出来的原因)。既然还保留在上面,这个连接肯定再也没有处理过请求!不然肯定出错了。

如果按照上面的论断的话,那么没有执行过请求,也就不会有报错喽?如果按照这个逻辑的话,那岂不是只有出现业务报错的才会有新的正常连接。笔者去报错的机器看了下,既然报错了,那肯定是执行过SQL了,然后触发Druid丢弃连接再新建连接。
果然,一直报错的机器上连接都连到新库了(但应用开发发现其它机器还是连到老库,所以找到了我求助),而且创建时间是3月29日,而不报错的应用的连接挂在老库上面,挑了几台看一下,这些挂在老库的连接依旧是1月29日创建的。
既然连接都正常了(到新库了),为何还在报错呢?难道说业务代码写的有问题,一旦报错,就永远错下去?于是笔者直接翻起了应用的源码。其使用这个数据库的连接用来获取(sequence)序列号。然后细细分析了源码后发现。其在数据库报错之后没有处理好,走了一个有问题的代码分支,导致永远不会再从数据库获取sequence(业务代码就不放上来了)。
为什么只有几台机器报错?因为这个序列号是取一段很大的范围到机器的内存中使用的,不耗尽之前不会执行SQL。所以只有一些内存中序列耗尽的机器才会运行到那一段有问题的代码分支。
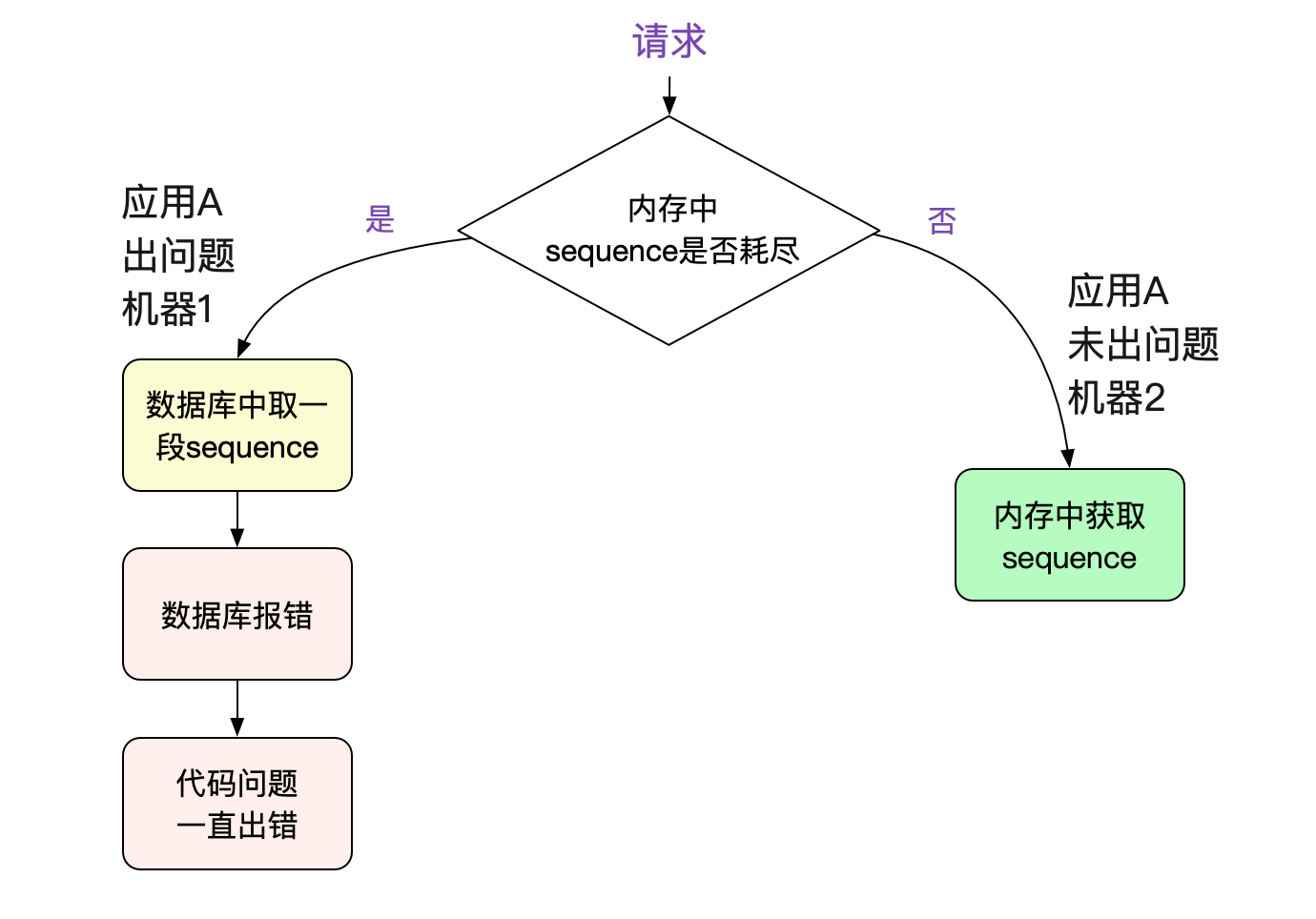
到这里大家可能会疑问?没有心跳检测么?确实没有,应用采用的是Druid数据源,而他们使用的那个版本的Druid是没有定时心跳检测的。
主从切换到底有没有成功呢?主从切换当然是成功的。这从其它的应用切过去之后运行良好可以判断出来。主从切换当中的数据库流量损失是我们可预期的正常现象。但是,数据库切换完之后,应用确恢复不回来,那就要仔细看看应用代码本身有什么问题了。
总结数据库主从切换是个频繁而又重要的动作,是保证业务连续性的必要条件。这不仅要看DBA的努力,还需要我们在应用层写出健壮的代码,才能够让我们的产线更加稳定。
