
解Bug之路-主从切换"未成功"? 前言
数据库主从切换是个非常有意思的话题。能够稳定的处理主从切换是保证业务连续性的必要条件。今天笔者就来讲讲主从切换过程中一个小小的问题。
故障场景最近线上进行主从切换,大部分应用都切过去了,但是某些应用的连接确还在老的主(新的从)上面。
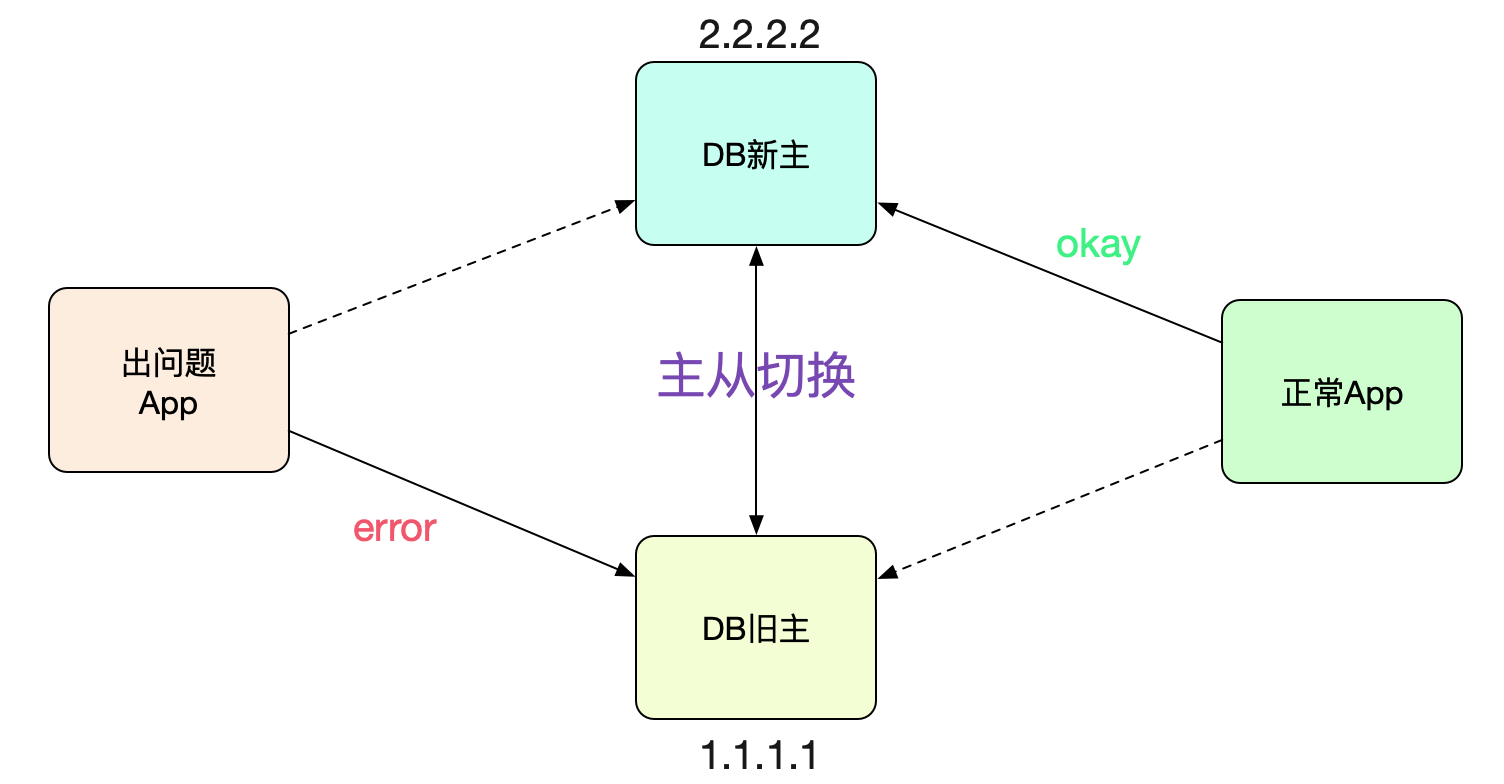
这让对应应用的开发百思不得其解,于是求助了笔者一探究竟。 怎么发现的
应用开发收到Cat监控告警,发现这个应用(A)中的请求在好几台机器中一直稳定失败。联想到昨晚刚做过数据库主从切换演练,于是上机器netstat -anp下,发现机器一直连的是旧的从库!
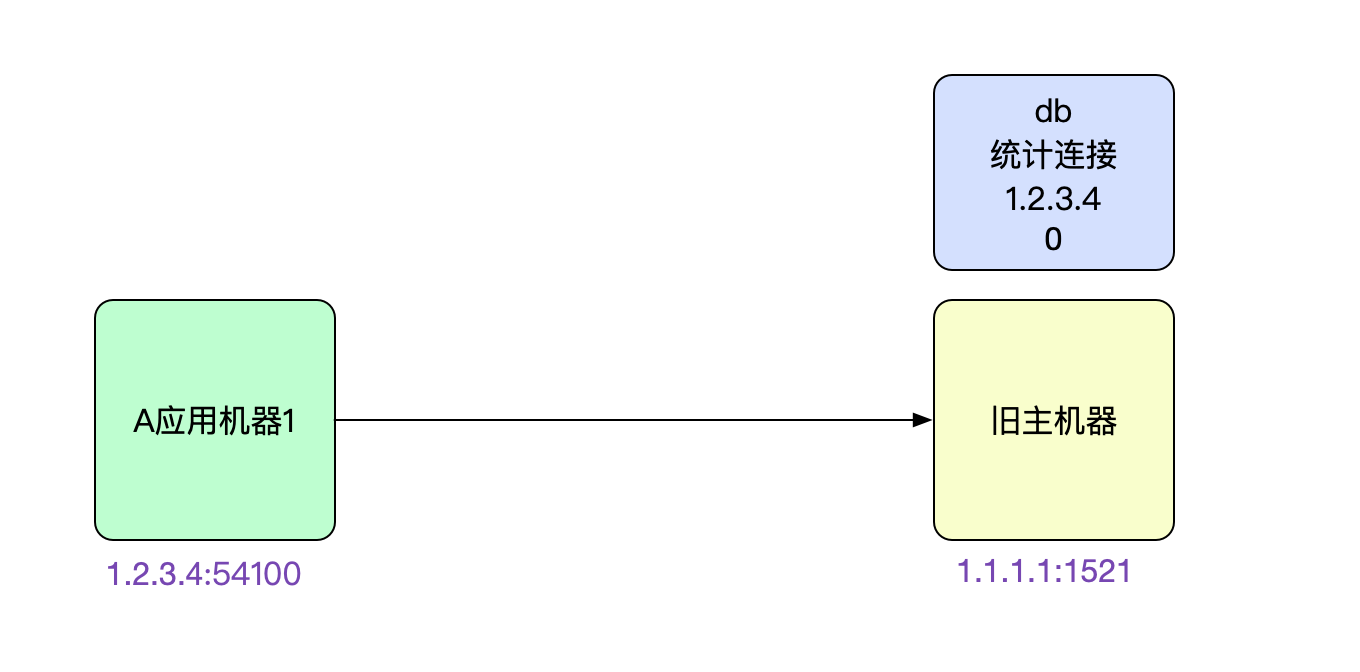
netstat -anp | grep 1521 tcp 0 0 1.2.3.4:54100 1.1.1.1:1521 ESTABLISHED开发感觉肯定是主从没有切换过去导致请求失败。乍一看,好像非常有道理的样子。
着手调查神马情况?距离切换成功已经8个小时了,为什么连接还连在上面呢?于是笔者ping了下对应数据库的域名:
ping db.prd 64byres from db.prd (2.2.2.2): icmp_seq=1 ttl=64 time=0.02ms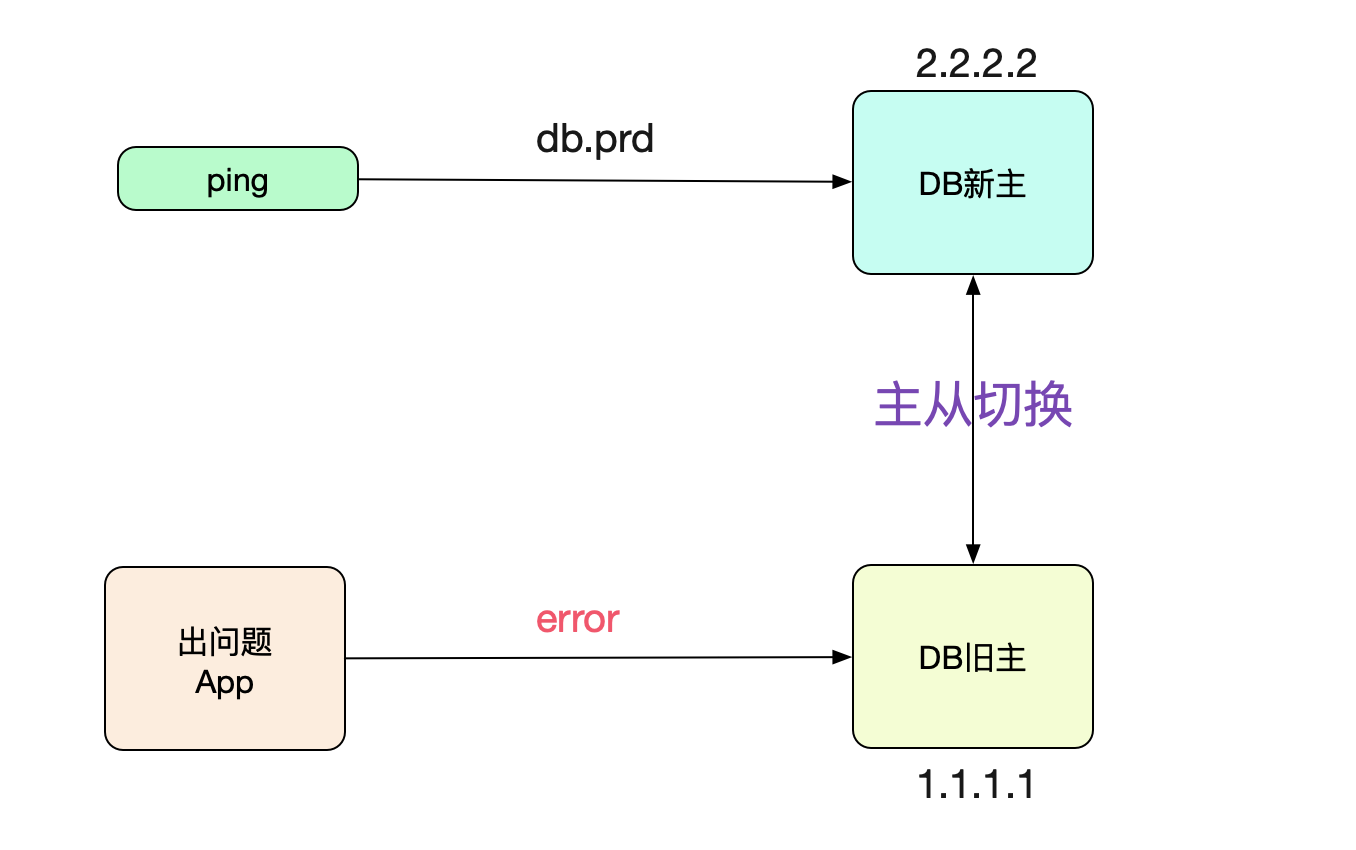
好奇怪,DNS已经切换过去了。应用怎么还连到老库呢? 第一个猜想,DNS延迟
最先想到的是主从切换到DNS反应过来有延迟。例如主从切换完,DNS在2min后才能生效,所以在此期间新建的连接还是到从库。
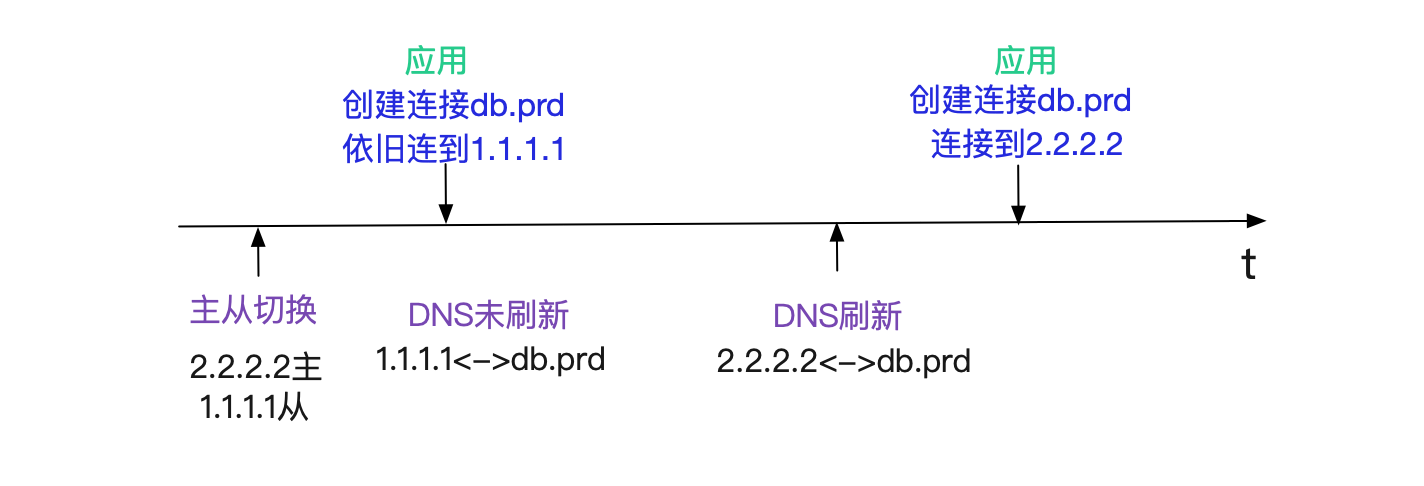
这种情况很正常,对于这种情况需要DBA将旧主的连接全都杀掉即可。咨询了下DBA,他们反馈他们已经把连接全部杀掉了。而且当场给我看了下数据库的统计连接SQL,确实没有对应机器的连接。这就奇怪了,应用机器上的连接是ESTABLISHED状态啊! 应用大部分机器都连的是老库!
这时候,开发向笔者反应,这个应用对应的大部分机器都是连的老库!如果是DNS延迟,不可能这么巧吧,40多台呢!
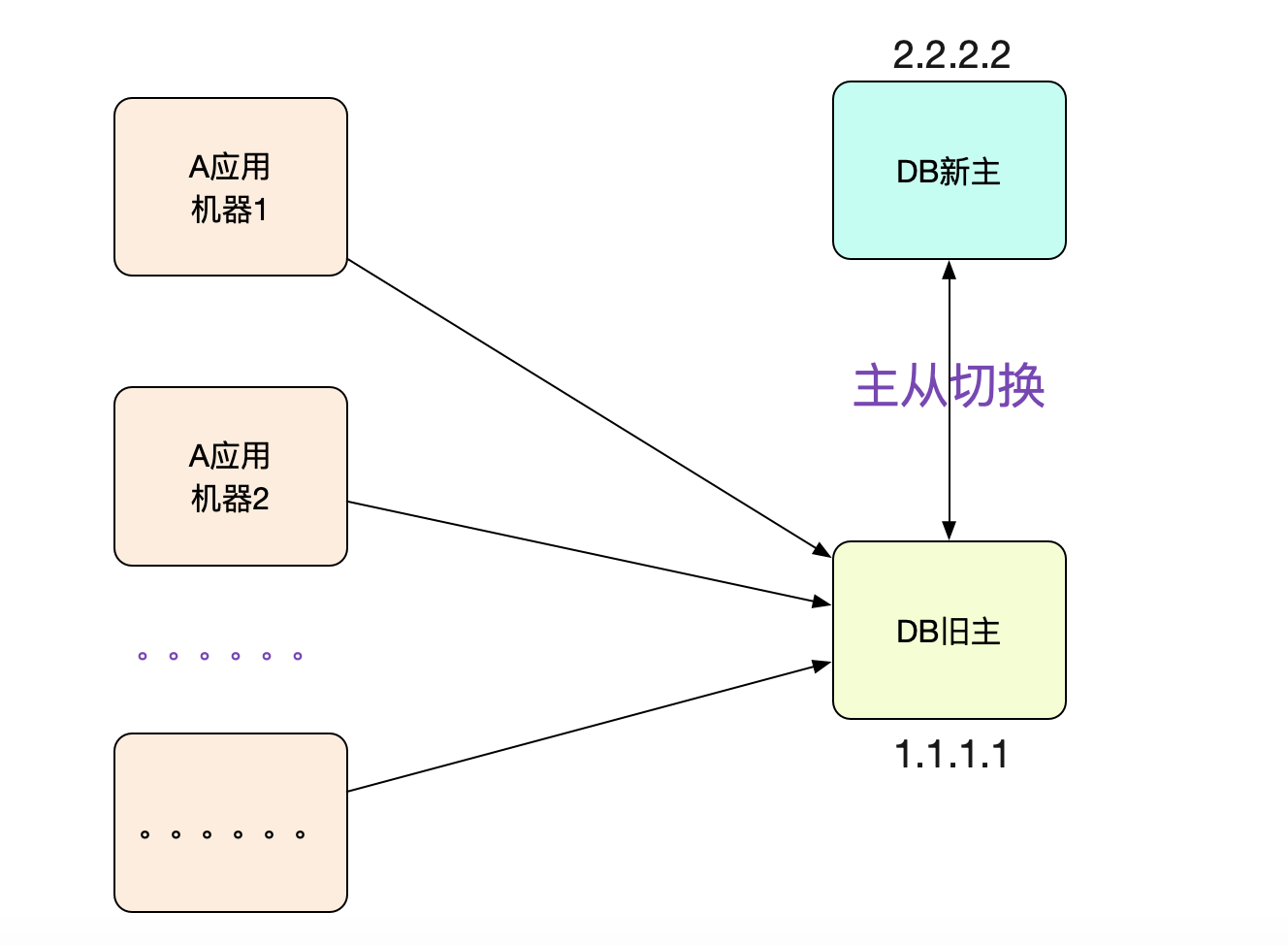
而且这些机器的DNS都是指向新库的。 DB没有kill连接?
难道是DBA漏了kill连接的步骤?但是和他和我展示的DB统计信息矛盾啊。于是笔者让DBA在对应老库的机器上netstat了一把。发现,连接还真的存在!
netstat -anp | grep 1.2.3.4 tcp 0 0 1.1.1.1:1521 1.2.3.4:54100 ESTABLISHED难道统计信息真的有问题?
为了验证笔者对于DNS延迟的猜想,就通过一些技巧来获取这个连接的创建时间。首先
netstat -anp | grep 1.2.3.4找出来这个连接。由于明显是属于应用java进程的,所以
直接找到进程pid:8299
既然有了进程pid,我们直接cat /proc/8299/net/tcp,直接获取到其所有的连接信息,然后在其中grep 1521的16进制05F1(当前机器上1521的连接只有一个)
...... local_address rem_address inode ...... ...... xxx:D345 xxx:05F1 23456789 ......找到这个socket(1.2.3.4:54100<->1.1.1.1:1521)对应的inode号。
有了这个inode号就简单了,我们直接
这么一看,这个连接是1月29日创建的。但是主从切换的时间点确是3月19日,
这个连接已经建了2个月了!那么就不可能是笔者所说的DNS失效问题了。因为连接就没有重连过。
看到这个连接创建时间,笔者第一反应,DBA确定杀连接了吗?问了下DBA有没有可能是统计问题。DBA听了后,告诉笔者,他们都重启过数据库了,怎么可能还有连接存在呢?看了下DB进程的创建时间。
ps -eo lstart,cmd | grep db进程名 Mar 19 17:52:32 2021 db进程名从进程启动时间来看,真的是在3月19日启动的。而这个诡异的连接还确实属于这个3月19日启动的进程。这个怎么看逻辑上都不通啊。

但是,既然linux的统计信息在这(还是要先暂时认为是靠谱的),那肯定是又有什么其它的诡异逻辑在里面了。 子进程继承了父进程的连接
稍微思考了一会,笔者就找到了一种可能。父进程先新建了连接进行处理,在创建子进程fork的时候,子进程会继承父进程的连接,这时候父进程退出,只保留子进程的话。就会出现连接在进程启动之前就已经存在的诡异现象。
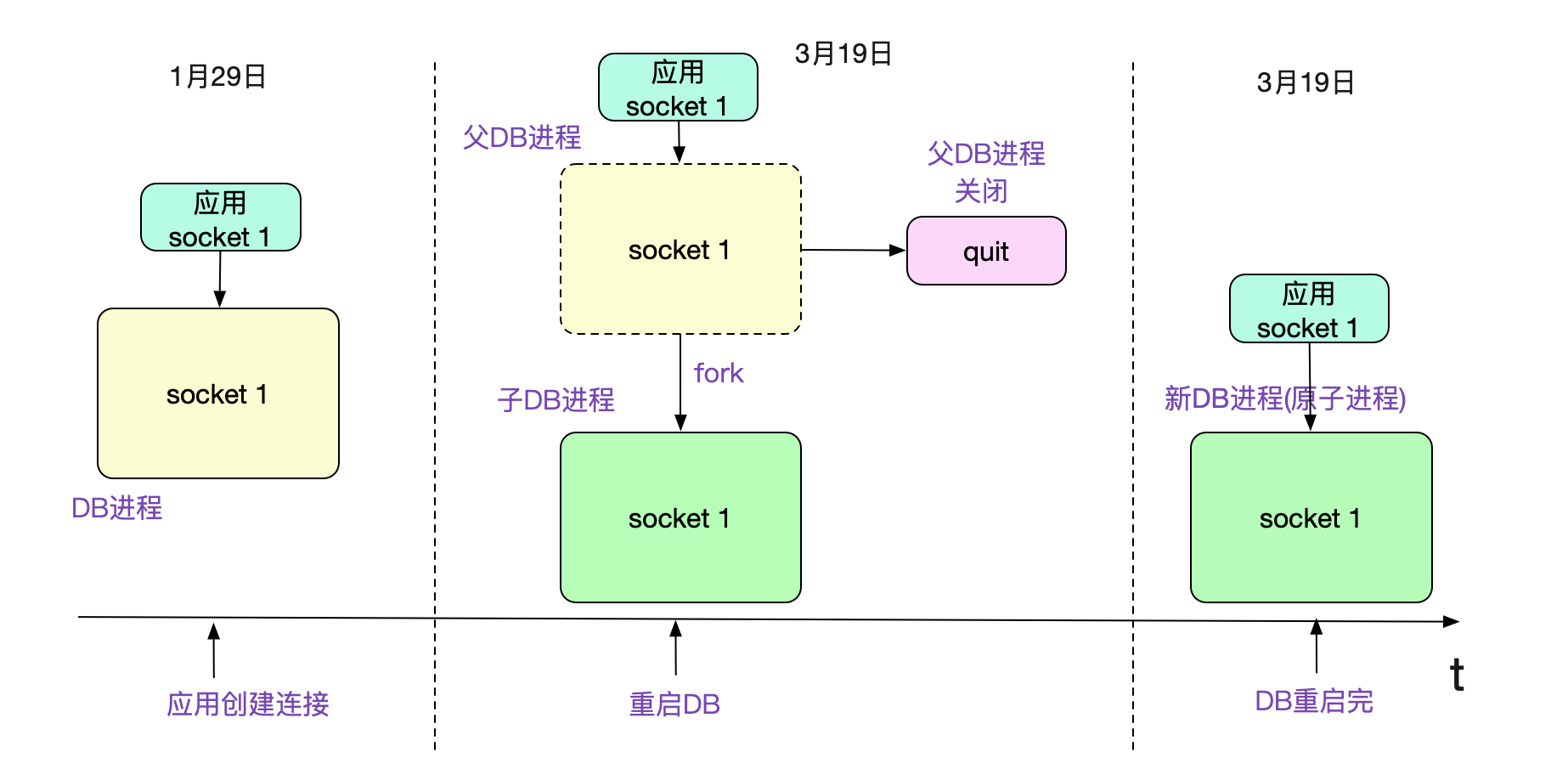
为了验证这个问题,笔者自己写了段简单的C程序,执行了一下确实如此。代码例子为: main.c ...... int main(int argc,char* argv[]){ ...... if((client_fd = accept(sockfd,(struct sockaddr*)&remote_addr,&sin_size)) == -1){ printf("accept error!\n"); } printf("Received a connection \n"); // 制造两分钟延迟,以造成上面的现象 sleep(2 * 60); if(!fork()){ // 子进程保持 while(1){ sleep(100000); } }else{ // 父进程关闭连接 close(client_fd); } return 0; }